 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuned In-Context Learners for Efficient Adaptation
Dec 22, 2025When adapting large language models (LLMs) to a specific downstream task, two primary approaches are commonly employed: (1) prompt engineering, often with in-context few-shot learning, leveraging the model's inherent generalization abilities, and (2) fine-tuning on task-specific data, directly optimizing the model's parameters. While prompt-based methods excel in few-shot scenarios, their effectiveness often plateaus as more data becomes available. Conversely, fine-tuning scales well with data but may underperform when training examples are scarce. We investigate a unified approach that bridges these two paradigms by incorporating in-context learning directly into the fine-tuning process. Specifically, we fine-tune the model on task-specific data augmented with in-context examples, mimicking the structure of k-shot prompts. This approach, while requiring per-task fine-tuning, combines the sample efficiency of in-context learning with the performance gains of fine-tuning, leading to a method that consistently matches and often significantly exceeds both these baselines. To perform hyperparameter selection in the low-data regime, we propose to use prequential evaluation, which eliminates the need for expensive cross-validation and leverages all available data for training while simultaneously providing a robust validation signal. We conduct an extensive empirical study to determine which adaptation paradigm - fine-tuning, in-context learning, or our proposed unified approach offers the best predictive performance on a concrete data downstream-tasks.
Predicting from Strings: Language Model Embeddings for Bayesian Optimization
Oct 15, 2024


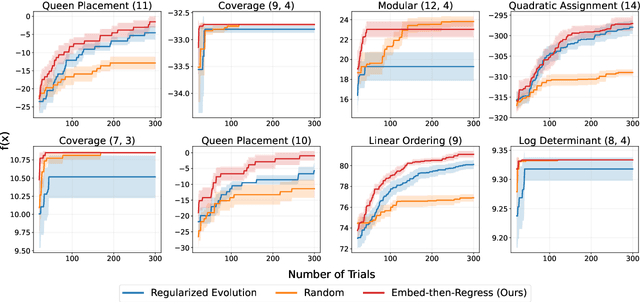
Bayesian Optimization is ubiquitous in the field of experimental design and blackbox optimization for improving search efficiency, but has been traditionally restricted to regression models which are only applicable to fixed search spaces and tabular input features. We propose Embed-then-Regress, a paradigm for applying in-context regression over string inputs, through the use of string embedding capabilities of pretrained language models. By expressing all inputs as strings, we are able to perform general-purpose regression for Bayesian Optimization over various domains including synthetic, combinatorial, and hyperparameter optimization, obtaining comparable results to state-of-the-art Gaussian Process-based algorithms. Code can be found at https://github.com/google-research/optformer/tree/main/optformer/embed_then_regress.
Imitating Language via Scalable Inverse Reinforcement Learning
Sep 02, 2024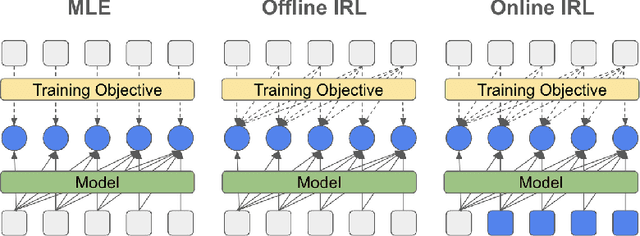
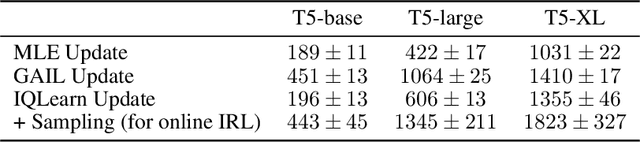
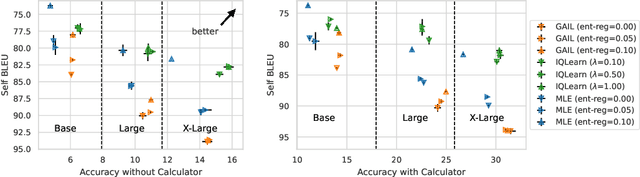

The majority of language model training builds on imitation learning. It covers pretraining, supervised fine-tuning, and affects the starting conditions for reinforcement learning from human feedback (RLHF). The simplicity and scalability of maximum likelihood estimation (MLE) for next token prediction led to its role as predominant paradigm. However, the broader field of imitation learning can more effectively utilize the sequential structure underlying autoregressive generation. We focus on investigating the inverse reinforcement learning (IRL) perspective to imitation, extracting rewards and directly optimizing sequences instead of individual token likelihoods and evaluate its benefits for fine-tuning large language models. We provide a new angle, reformulating inverse soft-Q-learning as a temporal difference regularized extension of MLE. This creates a principled connection between MLE and IRL and allows trading off added complexity with increased performance and diversity of generations in the supervised fine-tuning (SFT) setting. We find clear advantages for IRL-based imitation, in particular for retaining diversity while maximizing task performance, rendering IRL a strong alternative on fixed SFT datasets even without online data generation. Our analysis of IRL-extracted reward functions further indicates benefits for more robust reward functions via tighter integration of supervised and preference-based LLM post-training.
Denoising Autoregressive Representation Learning
Mar 08, 2024In this paper, we explore a new generative approach for learning visual representations. Our method, DARL, employs a decoder-only Transformer to predict image patches autoregressively. We find that training with Mean Squared Error (MSE) alone leads to strong representations. To enhance the image generation ability, we replace the MSE loss with the diffusion objective by using a denoising patch decoder. We show that the learned representation can be improved by using tailored noise schedules and longer training in larger models. Notably, the optimal schedule differs significantly from the typical ones used in standard image diffusion models. Overall, despite its simple architecture, DARL delivers performance remarkably close to state-of-the-art masked prediction models under the fine-tuning protocol. This marks an important step towards a unified model capable of both visual perception and generation, effectively combining the strengths of autoregressive and denoising diffusion models.
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
Mar 03, 2024



We consider the problem of online fine tuning the parameters of a language model at test time, also known as dynamic evaluation. While it is generally known that this approach improves the overall predictive performance, especially when considering distributional shift between training and evaluation data, we here emphasize the perspective that online adaptation turns parameters into temporally changing states and provides a form of context-length extension with memory in weights, more in line with the concept of memory in neuroscience. We pay particular attention to the speed of adaptation (in terms of sample efficiency),sensitivity to the overall distributional drift, and the computational overhead for performing gradient computations and parameter updates. Our empirical study provides insights on when online adaptation is particularly interesting. We highlight that with online adaptation the conceptual distinction between in-context learning and fine tuning blurs: both are methods to condition the model on previously observed tokens.
Transformers for Supervised Online Continual Learning
Mar 03, 2024



Transformers have become the dominant architecture for sequence modeling tasks such as natural language processing or audio processing, and they are now even considered for tasks that are not naturally sequential such as image classification. Their ability to attend to and to process a set of tokens as context enables them to develop in-context few-shot learning abilities. However, their potential for online continual learning remains relatively unexplored. In online continual learning, a model must adapt to a non-stationary stream of data, minimizing the cumulative nextstep prediction loss. We focus on the supervised online continual learning setting, where we learn a predictor $x_t \rightarrow y_t$ for a sequence of examples $(x_t, y_t)$. Inspired by the in-context learning capabilities of transformers and their connection to meta-learning, we propose a method that leverages these strengths for online continual learning. Our approach explicitly conditions a transformer on recent observations, while at the same time online training it with stochastic gradient descent, following the procedure introduced with Transformer-XL. We incorporate replay to maintain the benefits of multi-epoch training while adhering to the sequential protocol. We hypothesize that this combination enables fast adaptation through in-context learning and sustained longterm improvement via parametric learning. Our method demonstrates significant improvements over previous state-of-the-art results on CLOC, a challenging large-scale real-world benchmark for image geo-localization.
Kalman Filter for Online Classification of Non-Stationary Data
Jun 14, 2023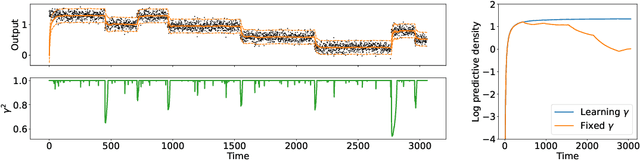
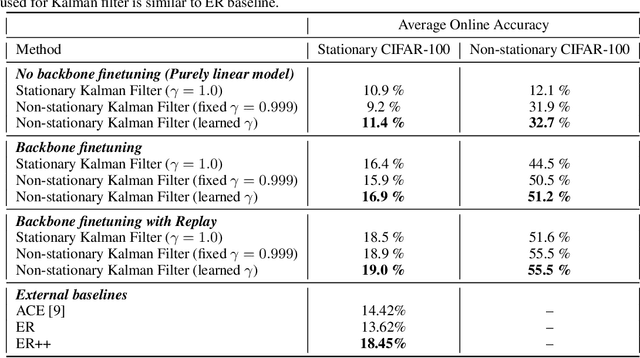
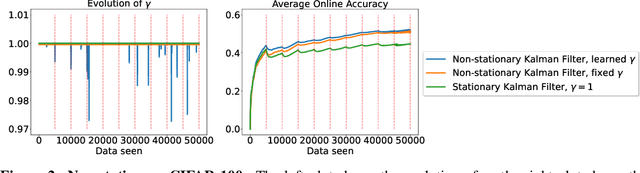
In Online Continual Learning (OCL) a learning system receives a stream of data and sequentially performs prediction and training steps. Important challenges in OCL are concerned with automatic adaptation to the particular non-stationary structure of the data, and with quantification of predictive uncertainty. Motivated by these challenges we introduce a probabilistic Bayesian online learning model by using a (possibly pretrained) neural representation and a state space model over the linear predictor weights. Non-stationarity over the linear predictor weights is modelled using a parameter drift transition density, parametrized by a coefficient that quantifies forgetting. Inference in the model is implemented with efficient Kalman filter recursions which track the posterior distribution over the linear weights, while online SGD updates over the transition dynamics coefficient allows to adapt to the non-stationarity seen in data. While the framework is developed assuming a linear Gaussian model, we also extend it to deal with classification problems and for fine-tuning the deep learning representation. In a set of experiments in multi-class classification using data sets such as CIFAR-100 and CLOC we demonstrate the predictive ability of the model and its flexibility to capture non-stationarity.
DiscoGen: Learning to Discover Gene Regulatory Networks
Apr 12, 2023Accurately inferring Gene Regulatory Networks (GRNs) is a critical and challenging task in biology. GRNs model the activatory and inhibitory interactions between genes and are inherently causal in nature. To accurately identify GRNs, perturbational data is required. However, most GRN discovery methods only operate on observational data. Recent advances in neural network-based causal discovery methods have significantly improved causal discovery, including handling interventional data, improvements in performance and scalability. However, applying state-of-the-art (SOTA) causal discovery methods in biology poses challenges, such as noisy data and a large number of samples. Thus, adapting the causal discovery methods is necessary to handle these challenges. In this paper, we introduce DiscoGen, a neural network-based GRN discovery method that can denoise gene expression measurements and handle interventional data. We demonstrate that our model outperforms SOTA neural network-based causal discovery methods.
Evaluating Representations with Readout Model Switching
Feb 19, 2023



Although much of the success of Deep Learning builds on learning good representations, a rigorous method to evaluate their quality is lacking. In this paper, we treat the evaluation of representations as a model selection problem and propose to use the Minimum Description Length (MDL) principle to devise an evaluation metric. Contrary to the established practice of limiting the capacity of the readout model, we design a hybrid discrete and continuous-valued model space for the readout models and employ a switching strategy to combine their predictions. The MDL score takes model complexity, as well as data efficiency into account. As a result, the most appropriate model for the specific task and representation will be chosen, making it a unified measure for comparison. The proposed metric can be efficiently computed with an online method and we present results for pre-trained vision encoders of various architectures (ResNet and ViT) and objective functions (supervised and self-supervised) on a range of downstream tasks. We compare our methods with accuracy-based approaches and show that the latter are inconsistent when multiple readout models are used. Finally, we discuss important properties revealed by our evaluations such as model scaling, preferred readout model, and data efficiency.
Bridging the Gap Between Offline and Online Reinforcement Learning Evaluation Methodologies
Dec 15, 2022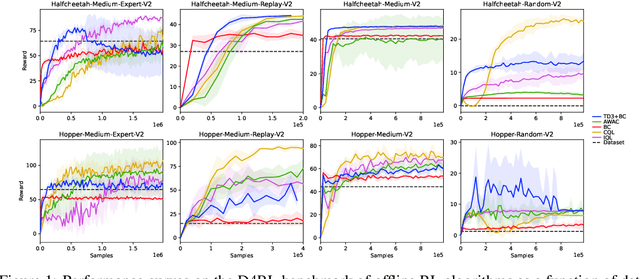
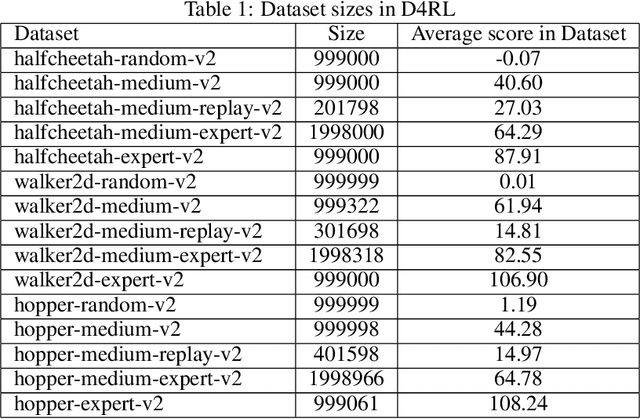

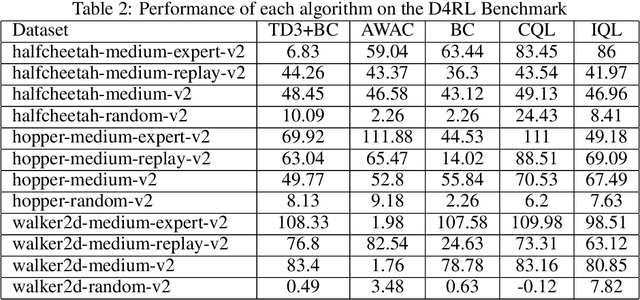
Reinforcement learning (RL) has shown great promise with algorithms learning in environments with large state and action spaces purely from scalar reward signals. A crucial challenge for current deep RL algorithms is that they require a tremendous amount of environment interactions for learning. This can be infeasible in situations where such interactions are expensive; such as in robotics. Offline RL algorithms try to address this issue by bootstrapping the learning process from existing logged data without needing to interact with the environment from the very beginning. While online RL algorithms are typically evaluated as a function of the number of environment interactions, there exists no single established protocol for evaluating offline RL methods.In this paper, we propose a sequential approach to evaluate offline RL algorithms as a function of the training set size and thus by their data efficiency. Sequential evaluation provides valuable insights into the data efficiency of the learning process and the robustness of algorithms to distribution changes in the dataset while also harmonizing the visualization of the offline and online learning phases. Our approach is generally applicable and easy to implement. We compare several existing offline RL algorithms using this approach and present insights from a variety of tasks and offline datasets.