 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuned In-Context Learners for Efficient Adaptation
Dec 22, 2025When adapting large language models (LLMs) to a specific downstream task, two primary approaches are commonly employed: (1) prompt engineering, often with in-context few-shot learning, leveraging the model's inherent generalization abilities, and (2) fine-tuning on task-specific data, directly optimizing the model's parameters. While prompt-based methods excel in few-shot scenarios, their effectiveness often plateaus as more data becomes available. Conversely, fine-tuning scales well with data but may underperform when training examples are scarce. We investigate a unified approach that bridges these two paradigms by incorporating in-context learning directly into the fine-tuning process. Specifically, we fine-tune the model on task-specific data augmented with in-context examples, mimicking the structure of k-shot prompts. This approach, while requiring per-task fine-tuning, combines the sample efficiency of in-context learning with the performance gains of fine-tuning, leading to a method that consistently matches and often significantly exceeds both these baselines. To perform hyperparameter selection in the low-data regime, we propose to use prequential evaluation, which eliminates the need for expensive cross-validation and leverages all available data for training while simultaneously providing a robust validation signal. We conduct an extensive empirical study to determine which adaptation paradigm - fine-tuning, in-context learning, or our proposed unified approach offers the best predictive performance on a concrete data downstream-tasks.
On the Hardness of Conditional Independence Testing In Practice
Dec 16, 2025Tests of conditional independence (CI) underpin a number of important problems in machine learning and statistics, from causal discovery to evaluation of predictor fairness and out-of-distribution robustness. Shah and Peters (2020) showed that, contrary to the unconditional case, no universally finite-sample valid test can ever achieve nontrivial power. While informative, this result (based on "hiding" dependence) does not seem to explain the frequent practical failures observed with popular CI tests. We investigate the Kernel-based Conditional Independence (KCI) test - of which we show the Generalized Covariance Measure underlying many recent tests is nearly a special case - and identify the major factors underlying its practical behavior. We highlight the key role of errors in the conditional mean embedding estimate for the Type-I error, while pointing out the importance of selecting an appropriate conditioning kernel (not recognized in previous work) as being necessary for good test power but also tending to inflate Type-I error.
Denoising Autoregressive Representation Learning
Mar 08, 2024In this paper, we explore a new generative approach for learning visual representations. Our method, DARL, employs a decoder-only Transformer to predict image patches autoregressively. We find that training with Mean Squared Error (MSE) alone leads to strong representations. To enhance the image generation ability, we replace the MSE loss with the diffusion objective by using a denoising patch decoder. We show that the learned representation can be improved by using tailored noise schedules and longer training in larger models. Notably, the optimal schedule differs significantly from the typical ones used in standard image diffusion models. Overall, despite its simple architecture, DARL delivers performance remarkably close to state-of-the-art masked prediction models under the fine-tuning protocol. This marks an important step towards a unified model capable of both visual perception and generation, effectively combining the strengths of autoregressive and denoising diffusion models.
Transformers for Supervised Online Continual Learning
Mar 03, 2024



Transformers have become the dominant architecture for sequence modeling tasks such as natural language processing or audio processing, and they are now even considered for tasks that are not naturally sequential such as image classification. Their ability to attend to and to process a set of tokens as context enables them to develop in-context few-shot learning abilities. However, their potential for online continual learning remains relatively unexplored. In online continual learning, a model must adapt to a non-stationary stream of data, minimizing the cumulative nextstep prediction loss. We focus on the supervised online continual learning setting, where we learn a predictor $x_t \rightarrow y_t$ for a sequence of examples $(x_t, y_t)$. Inspired by the in-context learning capabilities of transformers and their connection to meta-learning, we propose a method that leverages these strengths for online continual learning. Our approach explicitly conditions a transformer on recent observations, while at the same time online training it with stochastic gradient descent, following the procedure introduced with Transformer-XL. We incorporate replay to maintain the benefits of multi-epoch training while adhering to the sequential protocol. We hypothesize that this combination enables fast adaptation through in-context learning and sustained longterm improvement via parametric learning. Our method demonstrates significant improvements over previous state-of-the-art results on CLOC, a challenging large-scale real-world benchmark for image geo-localization.
Practical Kernel Tests of Conditional Independence
Feb 20, 2024



We describe a data-efficient, kernel-based approach to statistical testing of conditional independence. A major challenge of conditional independence testing, absent in tests of unconditional independence, is to obtain the correct test level (the specified upper bound on the rate of false positives), while still attaining competitive test power. Excess false positives arise due to bias in the test statistic, which is obtained using nonparametric kernel ridge regression. We propose three methods for bias control to correct the test level, based on data splitting, auxiliary data, and (where possible) simpler function classes. We show these combined strategies are effective both for synthetic and real-world data.
Evaluating Representations with Readout Model Switching
Feb 19, 2023Although much of the success of Deep Learning builds on learning good representations, a rigorous method to evaluate their quality is lacking. In this paper, we treat the evaluation of representations as a model selection problem and propose to use the Minimum Description Length (MDL) principle to devise an evaluation metric. Contrary to the established practice of limiting the capacity of the readout model, we design a hybrid discrete and continuous-valued model space for the readout models and employ a switching strategy to combine their predictions. The MDL score takes model complexity, as well as data efficiency into account. As a result, the most appropriate model for the specific task and representation will be chosen, making it a unified measure for comparison. The proposed metric can be efficiently computed with an online method and we present results for pre-trained vision encoders of various architectures (ResNet and ViT) and objective functions (supervised and self-supervised) on a range of downstream tasks. We compare our methods with accuracy-based approaches and show that the latter are inconsistent when multiple readout models are used. Finally, we discuss important properties revealed by our evaluations such as model scaling, preferred readout model, and data efficiency.
Investigating the role of model-based learning in exploration and transfer
Feb 08, 2023State of the art reinforcement learning has enabled training agents on tasks of ever increasing complexity. However, the current paradigm tends to favor training agents from scratch on every new task or on collections of tasks with a view towards generalizing to novel task configurations. The former suffers from poor data efficiency while the latter is difficult when test tasks are out-of-distribution. Agents that can effectively transfer their knowledge about the world pose a potential solution to these issues. In this paper, we investigate transfer learning in the context of model-based agents. Specifically, we aim to understand when exactly environment models have an advantage and why. We find that a model-based approach outperforms controlled model-free baselines for transfer learning. Through ablations, we show that both the policy and dynamics model learnt through exploration matter for successful transfer. We demonstrate our results across three domains which vary in their requirements for transfer: in-distribution procedural (Crafter), in-distribution identical (RoboDesk), and out-of-distribution (Meta-World). Our results show that intrinsic exploration combined with environment models present a viable direction towards agents that are self-supervised and able to generalize to novel reward functions.
Efficient Conditionally Invariant Representation Learning
Dec 16, 2022



We introduce the Conditional Independence Regression CovariancE (CIRCE), a measure of conditional independence for multivariate continuous-valued variables. CIRCE applies as a regularizer in settings where we wish to learn neural features $\varphi(X)$ of data $X$ to estimate a target $Y$, while being conditionally independent of a distractor $Z$ given $Y$. Both $Z$ and $Y$ are assumed to be continuous-valued but relatively low dimensional, whereas $X$ and its features may be complex and high dimensional. Relevant settings include domain-invariant learning, fairness, and causal learning. The procedure requires just a single ridge regression from $Y$ to kernelized features of $Z$, which can be done in advance. It is then only necessary to enforce independence of $\varphi(X)$ from residuals of this regression, which is possible with attractive estimation properties and consistency guarantees. By contrast, earlier measures of conditional feature dependence require multiple regressions for each step of feature learning, resulting in more severe bias and variance, and greater computational cost. When sufficiently rich features are used, we establish that CIRCE is zero if and only if $\varphi(X) \perp \!\!\! \perp Z \mid Y$. In experiments, we show superior performance to previous methods on challenging benchmarks, including learning conditionally invariant image features.
Sequential Learning Of Neural Networks for Prequential MDL
Oct 14, 2022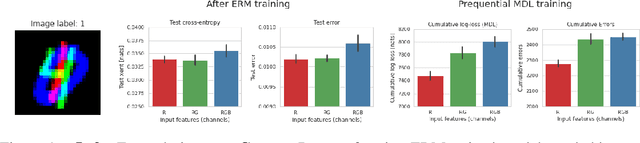
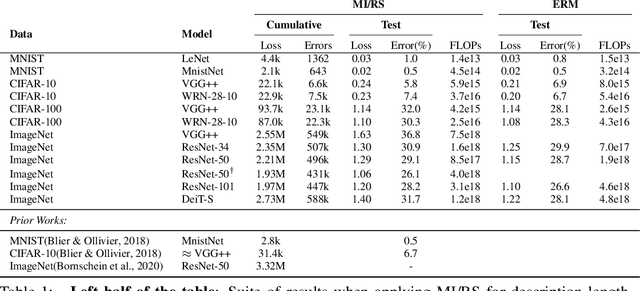


Minimum Description Length (MDL) provides a framework and an objective for principled model evaluation. It formalizes Occam's Razor and can be applied to data from non-stationary sources. In the prequential formulation of MDL, the objective is to minimize the cumulative next-step log-loss when sequentially going through the data and using previous observations for parameter estimation. It thus closely resembles a continual- or online-learning problem. In this study, we evaluate approaches for computing prequential description lengths for image classification datasets with neural networks. Considering the computational cost, we find that online-learning with rehearsal has favorable performance compared to the previously widely used block-wise estimation. We propose forward-calibration to better align the models predictions with the empirical observations and introduce replay-streams, a minibatch incremental training technique to efficiently implement approximate random replay while avoiding large in-memory replay buffers. As a result, we present description lengths for a suite of image classification datasets that improve upon previously reported results by large margins.
Where Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Oct 06, 2022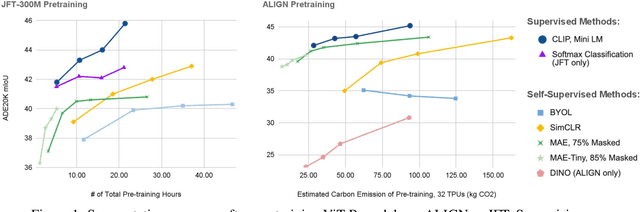
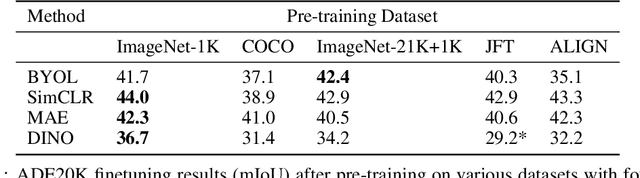
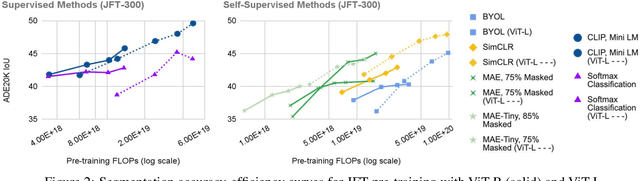
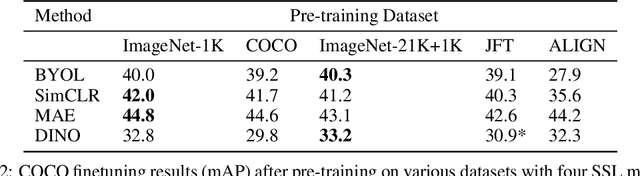
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.