 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Paper and Code
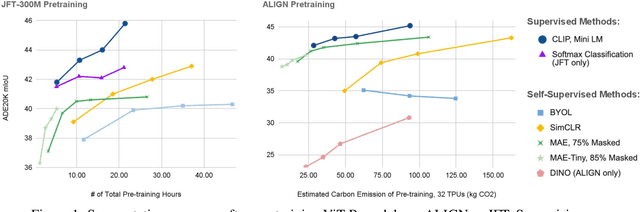
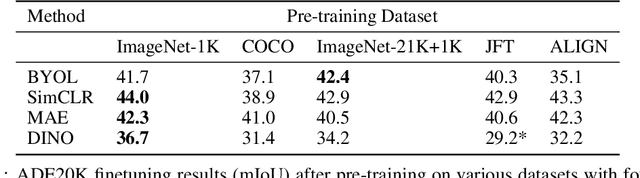
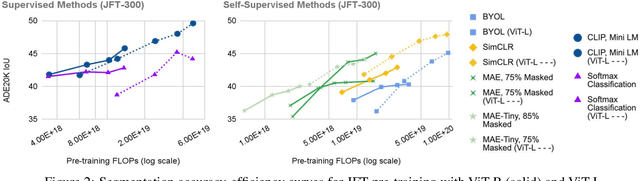
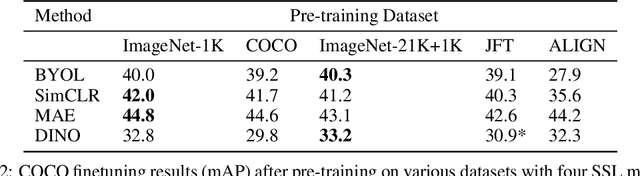
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.