 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Voices: Generating A-Roll Video from Audio with Mirage
Jun 09, 2025



From professional filmmaking to user-generated content, creators and consumers have long recognized that the power of video depends on the harmonious integration of what we hear (the video's audio track) with what we see (the video's image sequence). Current approaches to video generation either ignore sound to focus on general-purpose but silent image sequence generation or address both visual and audio elements but focus on restricted application domains such as re-dubbing. We introduce Mirage, an audio-to-video foundation model that excels at generating realistic, expressive output imagery from scratch given an audio input. When integrated with existing methods for speech synthesis (text-to-speech, or TTS), Mirage results in compelling multimodal video. When trained on audio-video footage of people talking (A-roll) and conditioned on audio containing speech, Mirage generates video of people delivering a believable interpretation of the performance implicit in input audio. Our central technical contribution is a unified method for training self-attention-based audio-to-video generation models, either from scratch or given existing weights. This methodology allows Mirage to retain generality as an approach to audio-to-video generation while producing outputs of superior subjective quality to methods that incorporate audio-specific architectures or loss components specific to people, speech, or details of how images or audio are captured. We encourage readers to watch and listen to the results of Mirage for themselves (see paper and comments for links).
SODA: Bottleneck Diffusion Models for Representation Learning
Nov 29, 2023We introduce SODA, a self-supervised diffusion model, designed for representation learning. The model incorporates an image encoder, which distills a source view into a compact representation, that, in turn, guides the generation of related novel views. We show that by imposing a tight bottleneck between the encoder and a denoising decoder, and leveraging novel view synthesis as a self-supervised objective, we can turn diffusion models into strong representation learners, capable of capturing visual semantics in an unsupervised manner. To the best of our knowledge, SODA is the first diffusion model to succeed at ImageNet linear-probe classification, and, at the same time, it accomplishes reconstruction, editing and synthesis tasks across a wide range of datasets. Further investigation reveals the disentangled nature of its emergent latent space, that serves as an effective interface to control and manipulate the model's produced images. All in all, we aim to shed light on the exciting and promising potential of diffusion models, not only for image generation, but also for learning rich and robust representations.
Active Acquisition for Multimodal Temporal Data: A Challenging Decision-Making Task
Nov 09, 2022

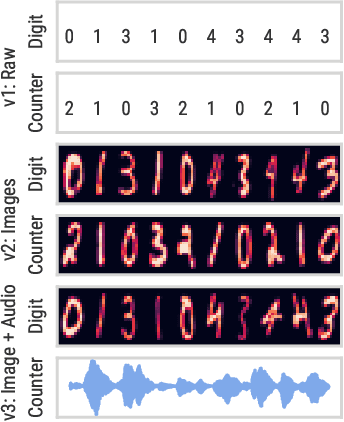

We introduce a challenging decision-making task that we call active acquisition for multimodal temporal data (A2MT). In many real-world scenarios, input features are not readily available at test time and must instead be acquired at significant cost. With A2MT, we aim to learn agents that actively select which modalities of an input to acquire, trading off acquisition cost and predictive performance. A2MT extends a previous task called active feature acquisition to temporal decision making about high-dimensional inputs. Further, we propose a method based on the Perceiver IO architecture to address A2MT in practice. Our agents are able to solve a novel synthetic scenario requiring practically relevant cross-modal reasoning skills. On two large-scale, real-world datasets, Kinetics-700 and AudioSet, our agents successfully learn cost-reactive acquisition behavior. However, an ablation reveals they are unable to learn to learn adaptive acquisition strategies, emphasizing the difficulty of the task even for state-of-the-art models. Applications of A2MT may be impactful in domains like medicine, robotics, or finance, where modalities differ in acquisition cost and informativeness.
Where Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Oct 06, 2022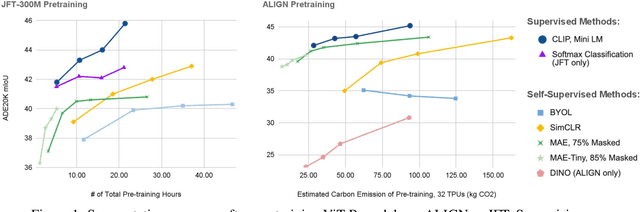
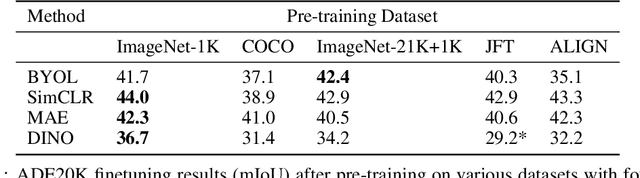
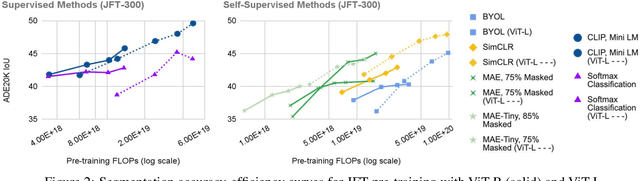
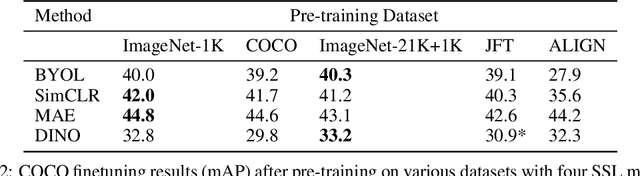
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.
Extended Intelligence
Sep 15, 2022We argue that intelligence, construed as the disposition to perform tasks successfully, is a property of systems composed of agents and their contexts. This is the thesis of extended intelligence. We argue that the performance of an agent will generally not be preserved if its context is allowed to vary. Hence, this disposition is not possessed by an agent alone, but is rather possessed by the system consisting of an agent and its context, which we dub an agent-in-context. An agent's context may include an environment, other agents, cultural artifacts (like language, technology), or all of these, as is typically the case for humans and artificial intelligence systems, as well as many non-human animals. In virtue of the thesis of extended intelligence, we contend that intelligence is context-bound, task-particular and incommensurable among agents. Our thesis carries strong implications for how intelligence is analyzed in the context of both psychology and artificial intelligence.
Transframer: Arbitrary Frame Prediction with Generative Models
Mar 18, 2022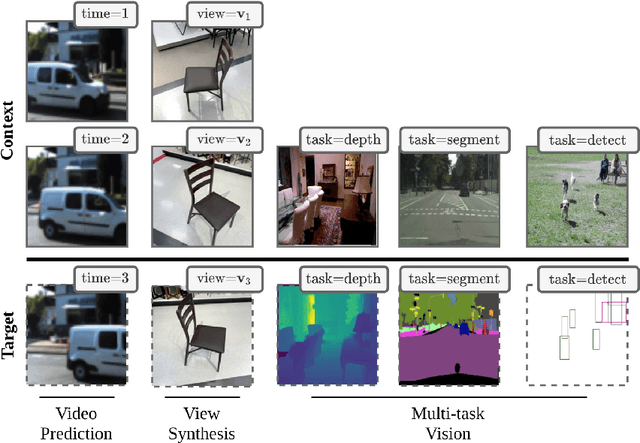

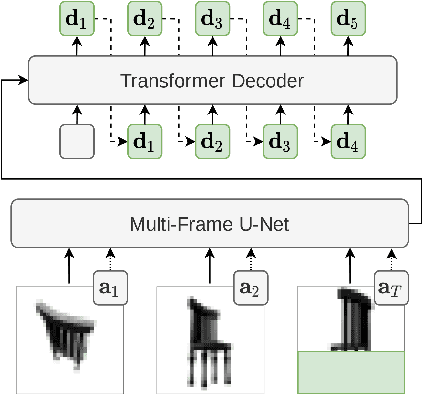

We present a general-purpose framework for image modelling and vision tasks based on probabilistic frame prediction. Our approach unifies a broad range of tasks, from image segmentation, to novel view synthesis and video interpolation. We pair this framework with an architecture we term Transframer, which uses U-Net and Transformer components to condition on annotated context frames, and outputs sequences of sparse, compressed image features. Transframer is the state-of-the-art on a variety of video generation benchmarks, is competitive with the strongest models on few-shot view synthesis, and can generate coherent 30 second videos from a single image without any explicit geometric information. A single generalist Transframer simultaneously produces promising results on 8 tasks, including semantic segmentation, image classification and optical flow prediction with no task-specific architectural components, demonstrating that multi-task computer vision can be tackled using probabilistic image models. Our approach can in principle be applied to a wide range of applications that require learning the conditional structure of annotated image-formatted data.
Object discovery and representation networks
Mar 16, 2022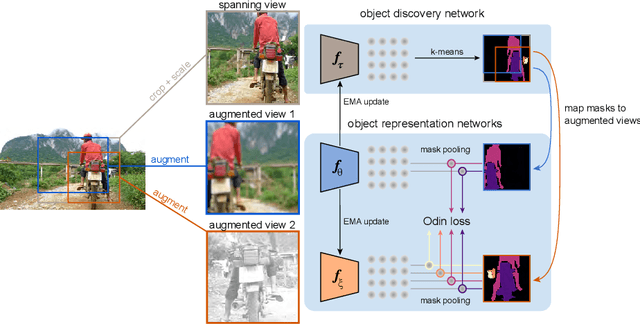
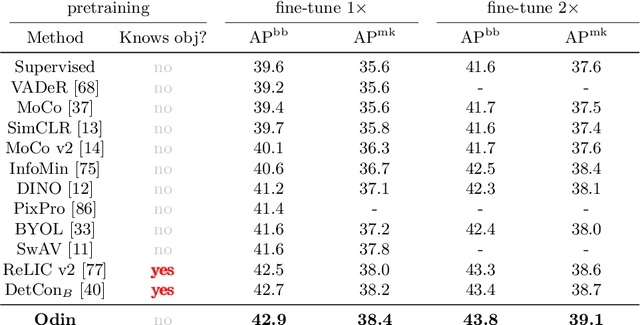


The promise of self-supervised learning (SSL) is to leverage large amounts of unlabeled data to solve complex tasks. While there has been excellent progress with simple, image-level learning, recent methods have shown the advantage of including knowledge of image structure. However, by introducing hand-crafted image segmentations to define regions of interest, or specialized augmentation strategies, these methods sacrifice the simplicity and generality that makes SSL so powerful. Instead, we propose a self-supervised learning paradigm that discovers the structure encoded in these priors by itself. Our method, Odin, couples object discovery and representation networks to discover meaningful image segmentations without any supervision. The resulting learning paradigm is simpler, less brittle, and more general, and achieves state-of-the-art transfer learning results for object detection and instance segmentation on COCO, and semantic segmentation on PASCAL and Cityscapes, while strongly surpassing supervised pre-training for video segmentation on DAVIS.
Hierarchical Perceiver
Feb 22, 2022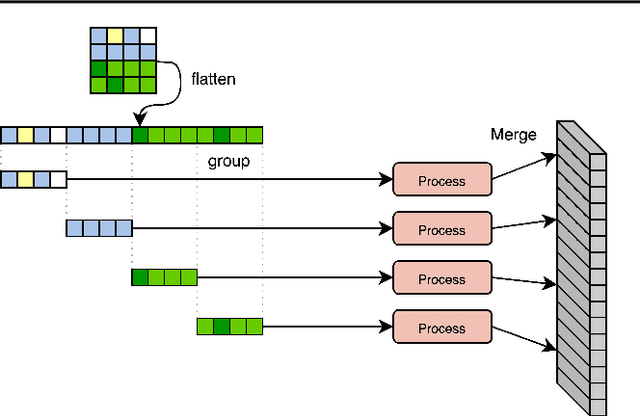

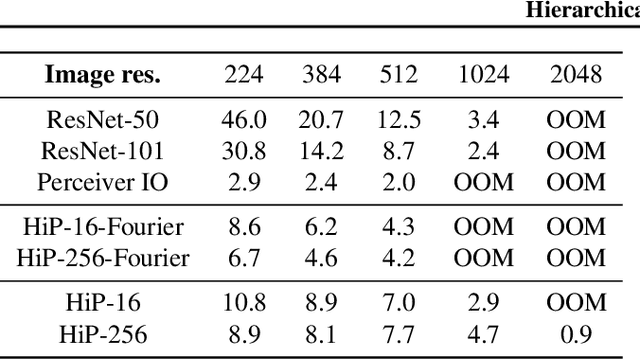

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022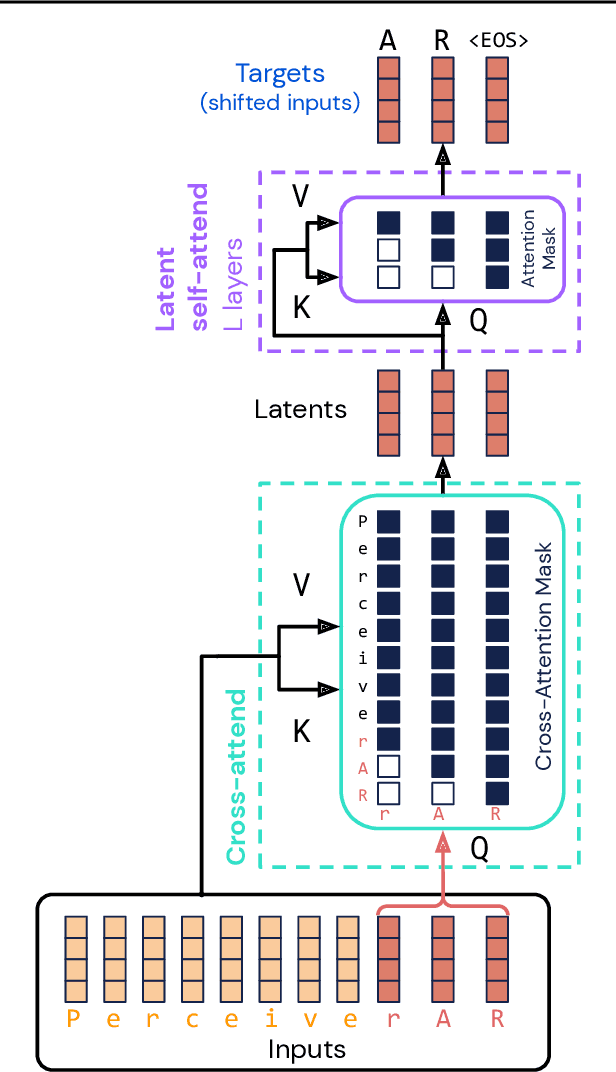
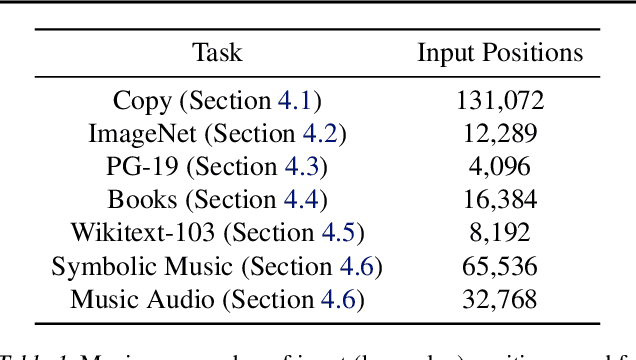
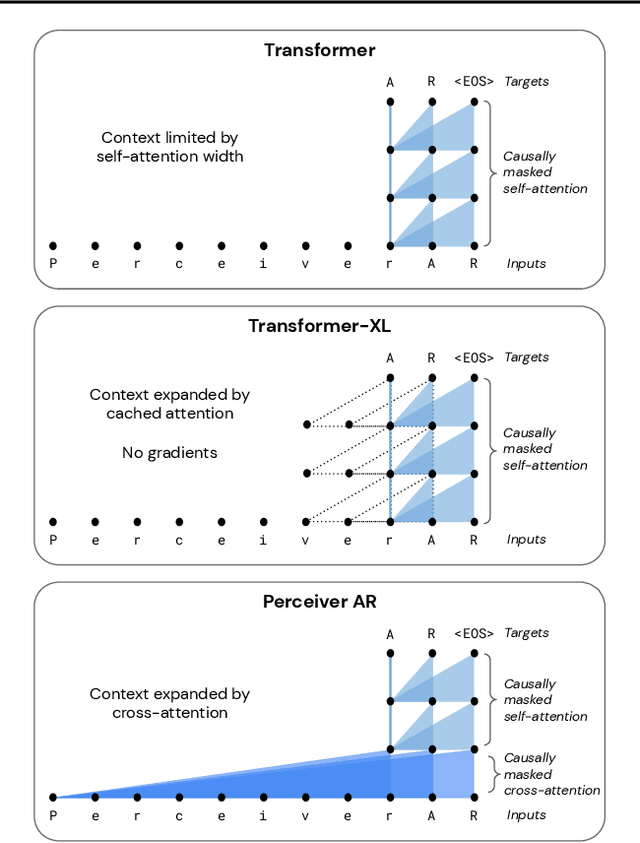
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.
Towards Learning Universal Audio Representations
Dec 01, 2021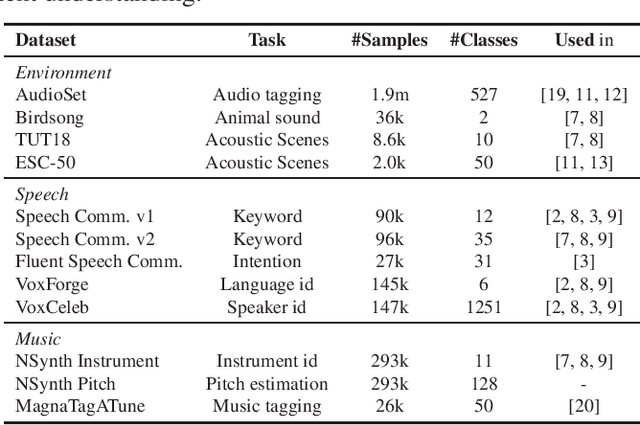
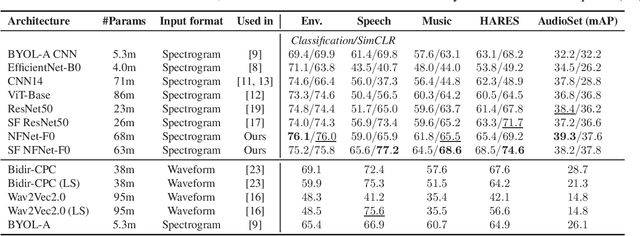
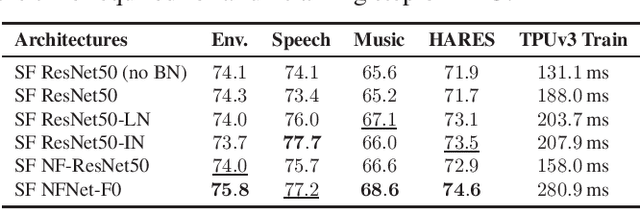
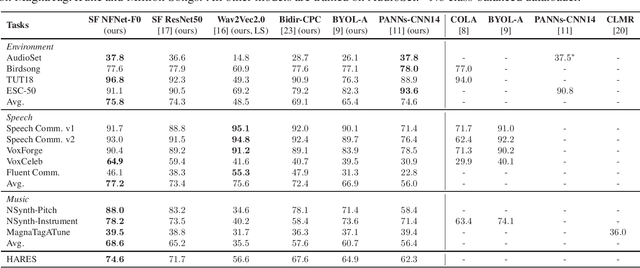
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.