 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and the Future of Digital Public Squares
Dec 13, 2024



Two substantial technological advances have reshaped the public square in recent decades: first with the advent of the internet and second with the recent introduction of large language models (LLMs). LLMs offer opportunities for a paradigm shift towards more decentralized, participatory online spaces that can be used to facilitate deliberative dialogues at scale, but also create risks of exacerbating societal schisms. Here, we explore four applications of LLMs to improve digital public squares: collective dialogue systems, bridging systems, community moderation, and proof-of-humanity systems. Building on the input from over 70 civil society experts and technologists, we argue that LLMs both afford promising opportunities to shift the paradigm for conversations at scale and pose distinct risks for digital public squares. We lay out an agenda for future research and investments in AI that will strengthen digital public squares and safeguard against potential misuses of AI.
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem
Apr 23, 2024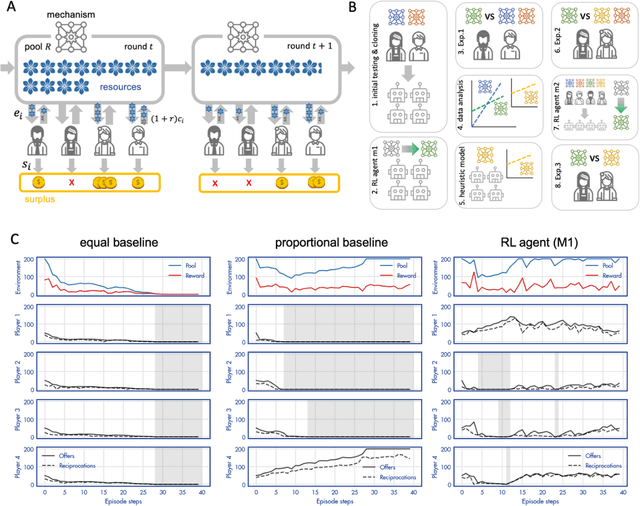
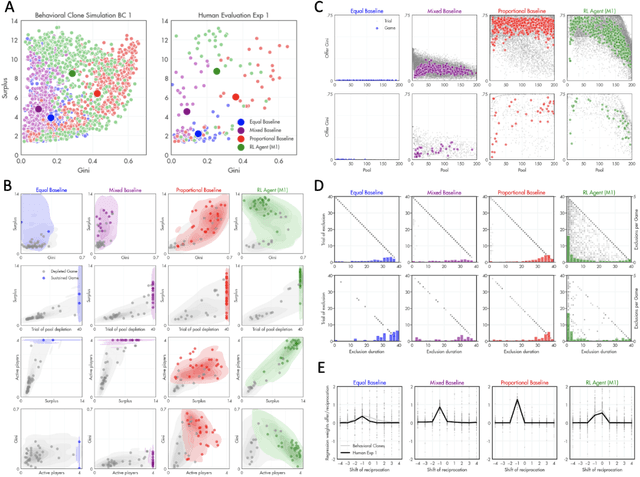
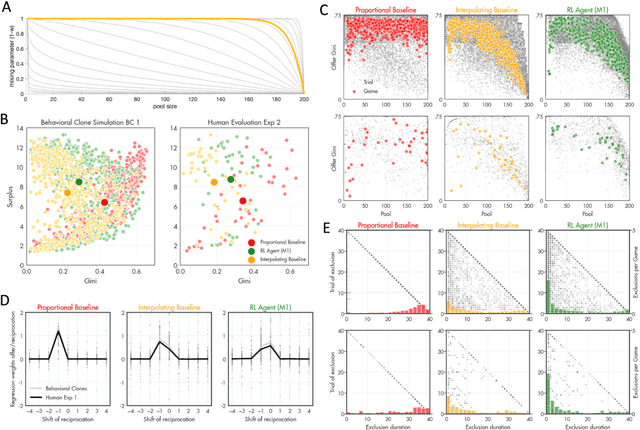
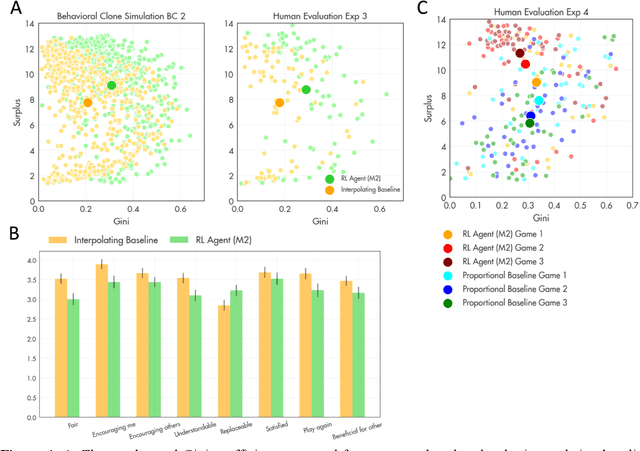
A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.
Hierarchical Perceiver
Feb 22, 2022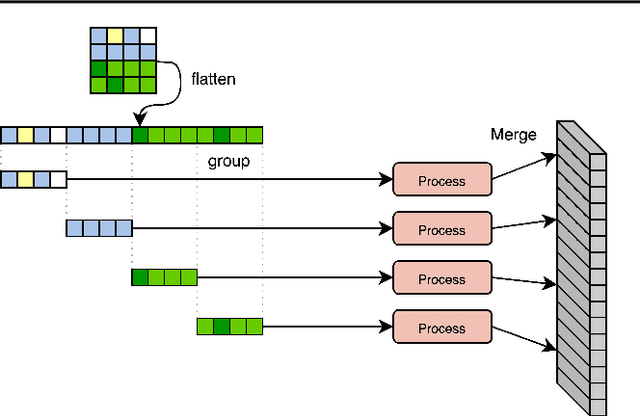

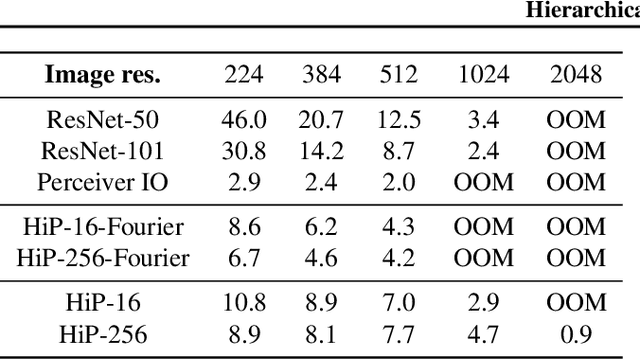

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
Collaborating with Humans without Human Data
Oct 15, 2021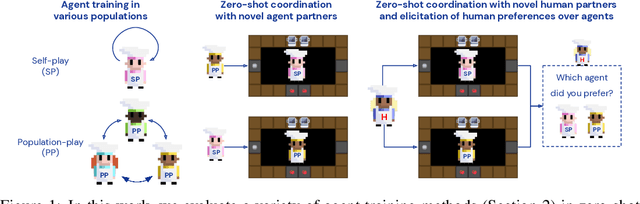

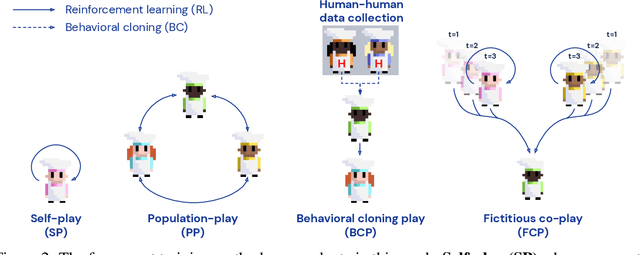
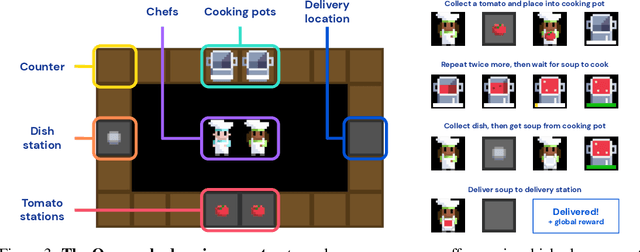
Collaborating with humans requires rapidly adapting to their individual strengths, weaknesses, and preferences. Unfortunately, most standard multi-agent reinforcement learning techniques, such as self-play (SP) or population play (PP), produce agents that overfit to their training partners and do not generalize well to humans. Alternatively, researchers can collect human data, train a human model using behavioral cloning, and then use that model to train "human-aware" agents ("behavioral cloning play", or BCP). While such an approach can improve the generalization of agents to new human co-players, it involves the onerous and expensive step of collecting large amounts of human data first. Here, we study the problem of how to train agents that collaborate well with human partners without using human data. We argue that the crux of the problem is to produce a diverse set of training partners. Drawing inspiration from successful multi-agent approaches in competitive domains, we find that a surprisingly simple approach is highly effective. We train our agent partner as the best response to a population of self-play agents and their past checkpoints taken throughout training, a method we call Fictitious Co-Play (FCP). Our experiments focus on a two-player collaborative cooking simulator that has recently been proposed as a challenge problem for coordination with humans. We find that FCP agents score significantly higher than SP, PP, and BCP when paired with novel agent and human partners. Furthermore, humans also report a strong subjective preference to partnering with FCP agents over all baselines.
Deep reinforcement learning models the emergent dynamics of human cooperation
Mar 08, 2021


Collective action demands that individuals efficiently coordinate how much, where, and when to cooperate. Laboratory experiments have extensively explored the first part of this process, demonstrating that a variety of social-cognitive mechanisms influence how much individuals choose to invest in group efforts. However, experimental research has been unable to shed light on how social cognitive mechanisms contribute to the where and when of collective action. We leverage multi-agent deep reinforcement learning to model how a social-cognitive mechanism--specifically, the intrinsic motivation to achieve a good reputation--steers group behavior toward specific spatial and temporal strategies for collective action in a social dilemma. We also collect behavioral data from groups of human participants challenged with the same dilemma. The model accurately predicts spatial and temporal patterns of group behavior: in this public goods dilemma, the intrinsic motivation for reputation catalyzes the development of a non-territorial, turn-taking strategy to coordinate collective action.
Synthetic Returns for Long-Term Credit Assignment
Feb 24, 2021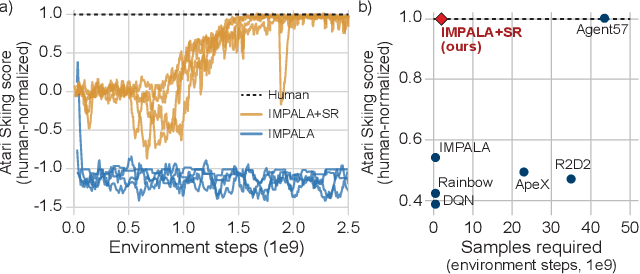
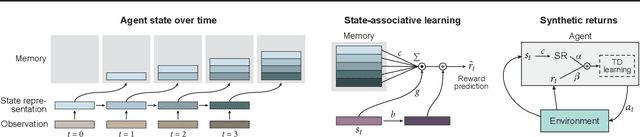
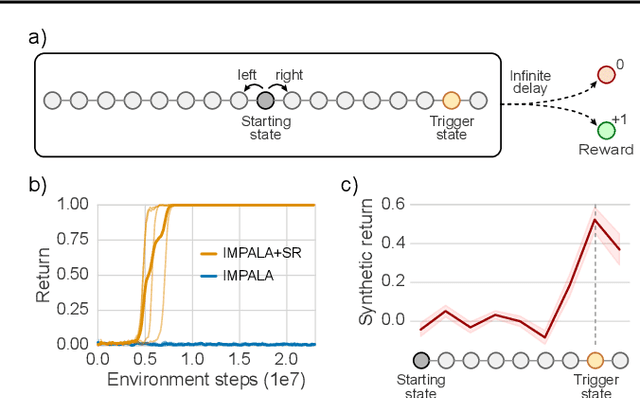
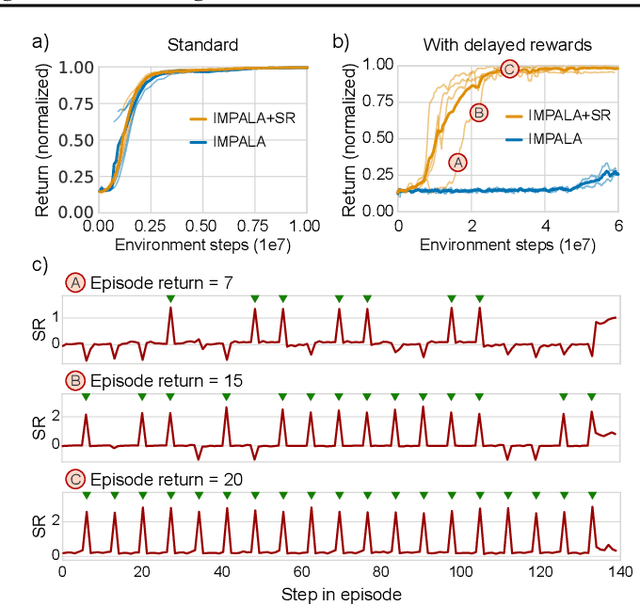
Since the earliest days of reinforcement learning, the workhorse method for assigning credit to actions over time has been temporal-difference (TD) learning, which propagates credit backward timestep-by-timestep. This approach suffers when delays between actions and rewards are long and when intervening unrelated events contribute variance to long-term returns. We propose state-associative (SA) learning, where the agent learns associations between states and arbitrarily distant future rewards, then propagates credit directly between the two. In this work, we use SA-learning to model the contribution of past states to the current reward. With this model we can predict each state's contribution to the far future, a quantity we call "synthetic returns". TD-learning can then be applied to select actions that maximize these synthetic returns (SRs). We demonstrate the effectiveness of augmenting agents with SRs across a range of tasks on which TD-learning alone fails. We show that the learned SRs are interpretable: they spike for states that occur after critical actions are taken. Finally, we show that our IMPALA-based SR agent solves Atari Skiing -- a game with a lengthy reward delay that posed a major hurdle to deep-RL agents -- 25 times faster than the published state-of-the-art.
Object-based attention for spatio-temporal reasoning: Outperforming neuro-symbolic models with flexible distributed architectures
Dec 15, 2020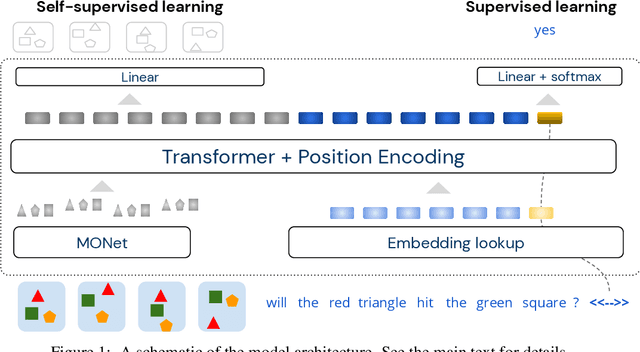
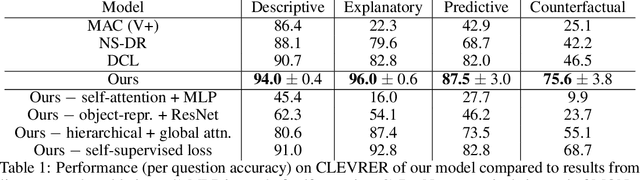
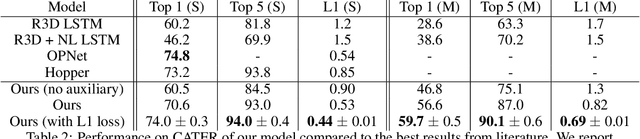
Neural networks have achieved success in a wide array of perceptual tasks, but it is often stated that they are incapable of solving tasks that require higher-level reasoning. Two new task domains, CLEVRER and CATER, have recently been developed to focus on reasoning, as opposed to perception, in the context of spatio-temporal interactions between objects. Initial experiments on these domains found that neuro-symbolic approaches, which couple a logic engine and language parser with a neural perceptual front-end, substantially outperform fully-learned distributed networks, a finding that was taken to support the above thesis. Here, we show on the contrary that a fully-learned neural network with the right inductive biases can perform substantially better than all previous neural-symbolic models on both of these tasks, particularly on questions that most emphasize reasoning over perception. Our model makes critical use of both self-attention and learned "soft" object-centric representations, as well as BERT-style semi-supervised predictive losses. These flexible biases allow our model to surpass the previous neuro-symbolic state-of-the-art using less than 60% of available labelled data. Together, these results refute the neuro-symbolic thesis laid out by previous work involving these datasets, and they provide evidence that neural networks can indeed learn to reason effectively about the causal, dynamic structure of physical events.
Rapid Task-Solving in Novel Environments
Jun 05, 2020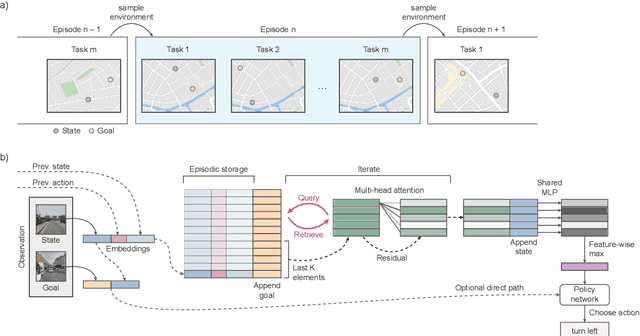

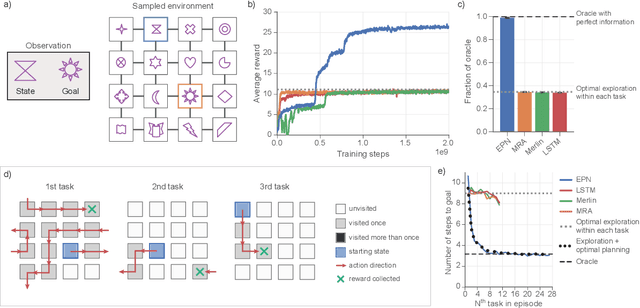
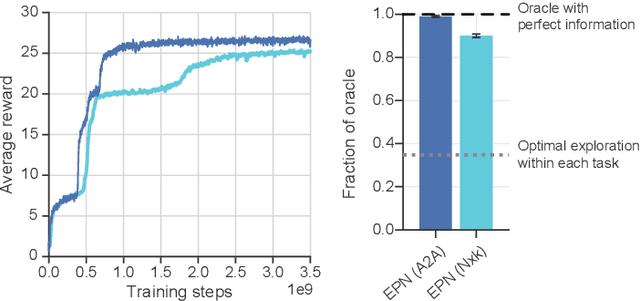
When thrust into an unfamiliar environment and charged with solving a series of tasks, an effective agent should (1) leverage prior knowledge to solve its current task while (2) efficiently exploring to gather knowledge for use in future tasks, and then (3) plan using that knowledge when faced with new tasks in that same environment. We introduce two domains for conducting research on this challenge, and find that state-of-the-art deep reinforcement learning (RL) agents fail to plan in novel environments. We develop a recursive implicit planning module that operates over episodic memories, and show that the resulting deep-RL agent is able to explore and plan in novel environments, outperforming the nearest baseline by factors of 2-3 across the two domains. We find evidence that our module (1) learned to execute a sensible information-propagating algorithm and (2) generalizes to situations beyond its training experience.
MONet: Unsupervised Scene Decomposition and Representation
Jan 22, 2019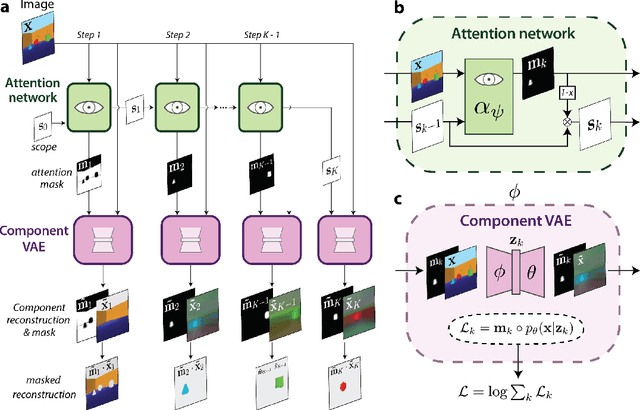
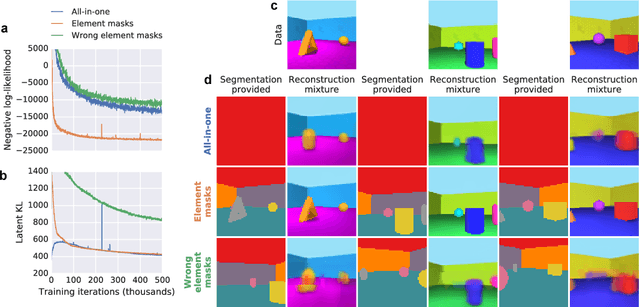
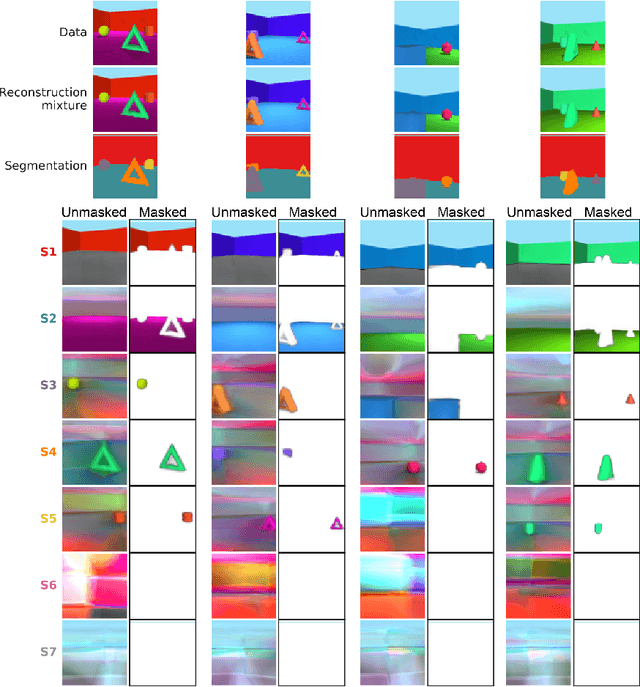
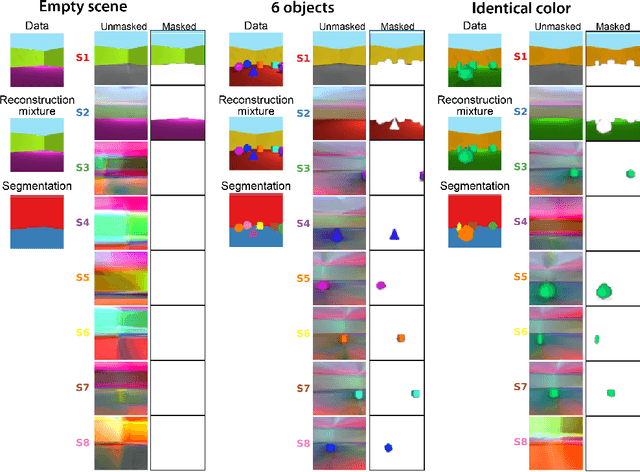
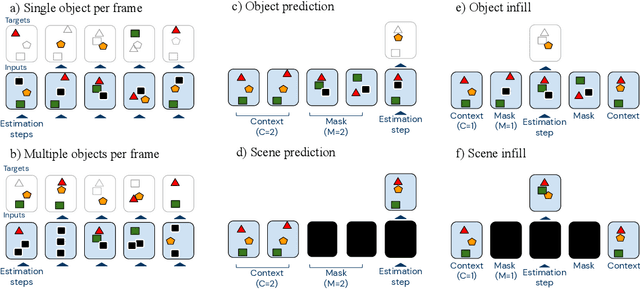
The ability to decompose scenes in terms of abstract building blocks is crucial for general intelligence. Where those basic building blocks share meaningful properties, interactions and other regularities across scenes, such decompositions can simplify reasoning and facilitate imagination of novel scenarios. In particular, representing perceptual observations in terms of entities should improve data efficiency and transfer performance on a wide range of tasks. Thus we need models capable of discovering useful decompositions of scenes by identifying units with such regularities and representing them in a common format. To address this problem, we have developed the Multi-Object Network (MONet). In this model, a VAE is trained end-to-end together with a recurrent attention network -- in a purely unsupervised manner -- to provide attention masks around, and reconstructions of, regions of images. We show that this model is capable of learning to decompose and represent challenging 3D scenes into semantically meaningful components, such as objects and background elements.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
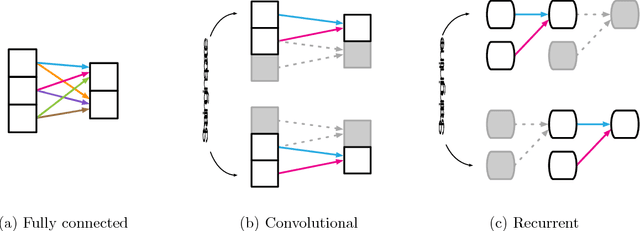
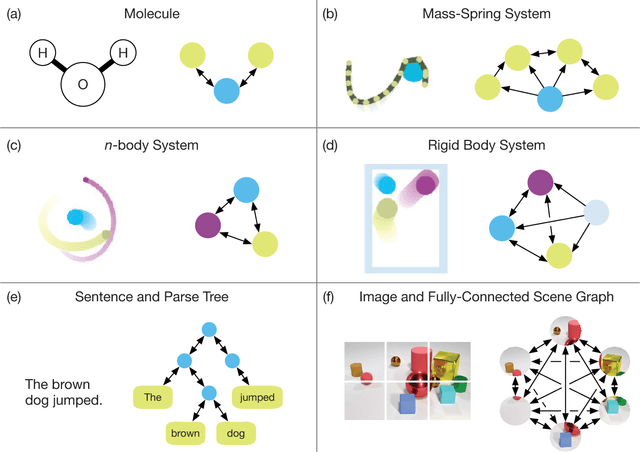
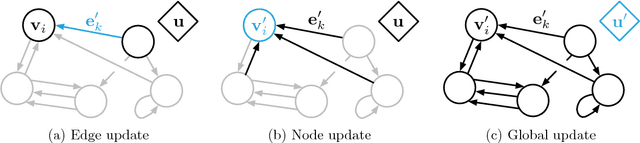
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.