 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Depths: Dynamically allocating compute in transformer-based language models
Apr 02, 2024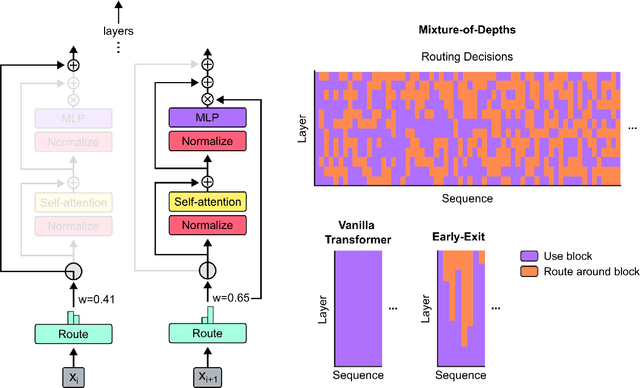
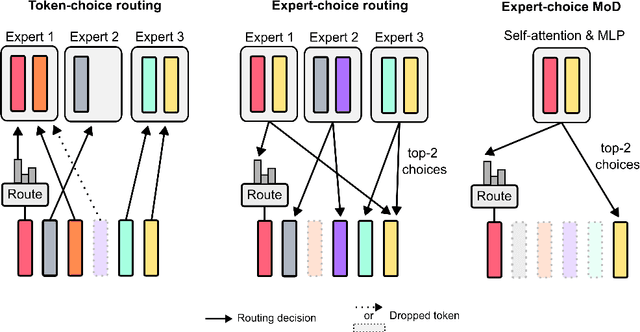
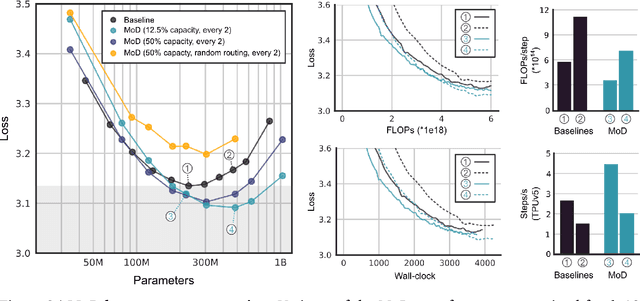
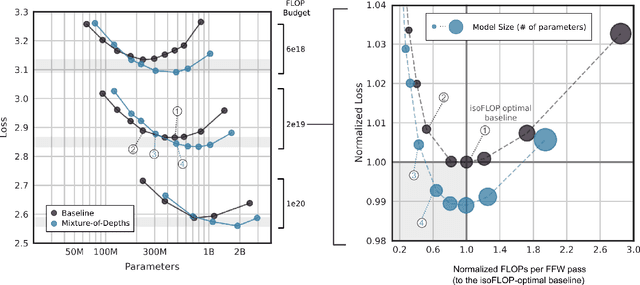
Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens ($k$) that can participate in the self-attention and MLP computations at a given layer. The tokens to be processed are determined by the network using a top-$k$ routing mechanism. Since $k$ is defined a priori, this simple procedure uses a static computation graph with known tensor sizes, unlike other conditional computation techniques. Nevertheless, since the identities of the $k$ tokens are fluid, this method can expend FLOPs non-uniformly across the time and model depth dimensions. Thus, compute expenditure is entirely predictable in sum total, but dynamic and context-sensitive at the token-level. Not only do models trained in this way learn to dynamically allocate compute, they do so efficiently. These models match baseline performance for equivalent FLOPS and wall-clock times to train, but require a fraction of the FLOPs per forward pass, and can be upwards of 50\% faster to step during post-training sampling.
How to Learn and Represent Abstractions: An Investigation using Symbolic Alchemy
Dec 14, 2021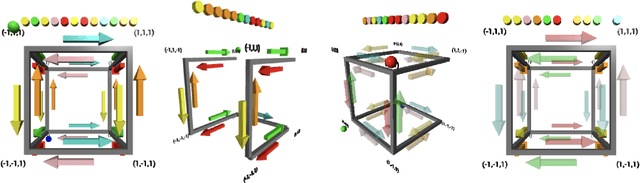
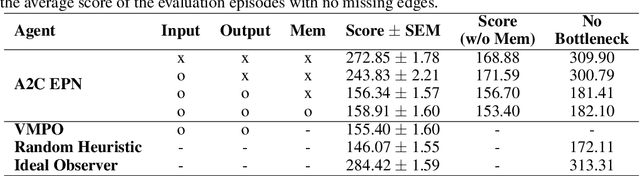
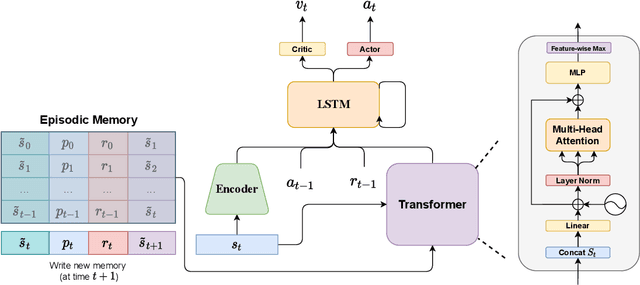
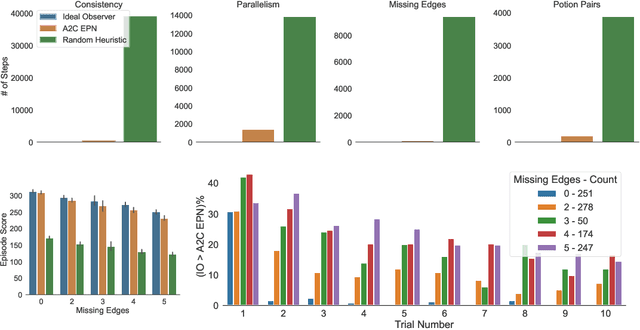
Alchemy is a new meta-learning environment rich enough to contain interesting abstractions, yet simple enough to make fine-grained analysis tractable. Further, Alchemy provides an optional symbolic interface that enables meta-RL research without a large compute budget. In this work, we take the first steps toward using Symbolic Alchemy to identify design choices that enable deep-RL agents to learn various types of abstraction. Then, using a variety of behavioral and introspective analyses we investigate how our trained agents use and represent abstract task variables, and find intriguing connections to the neuroscience of abstraction. We conclude by discussing the next steps for using meta-RL and Alchemy to better understand the representation of abstract variables in the brain.
Synthetic Returns for Long-Term Credit Assignment
Feb 24, 2021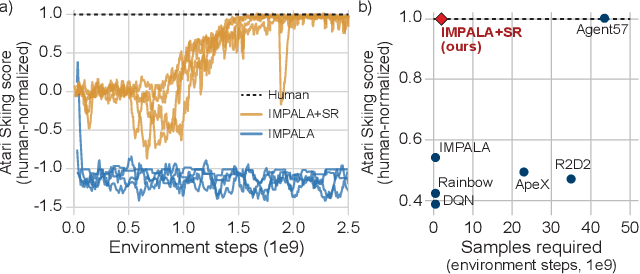
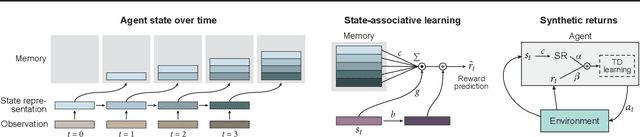
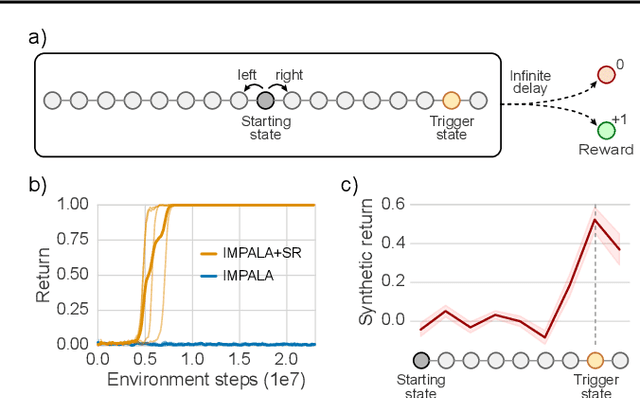
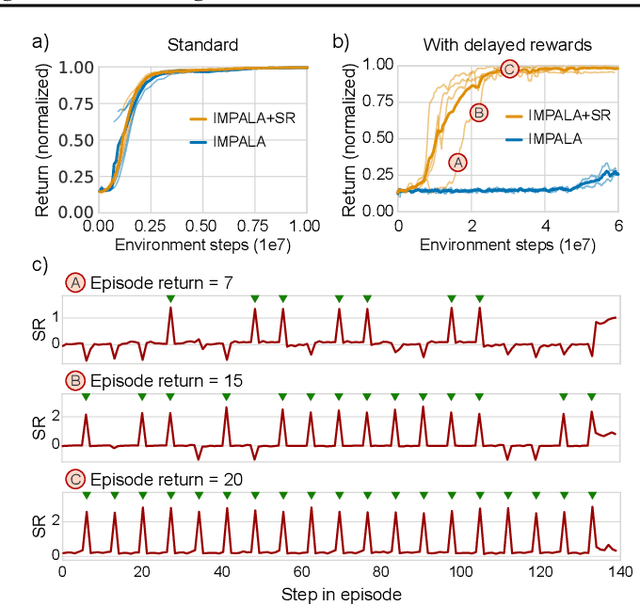
Since the earliest days of reinforcement learning, the workhorse method for assigning credit to actions over time has been temporal-difference (TD) learning, which propagates credit backward timestep-by-timestep. This approach suffers when delays between actions and rewards are long and when intervening unrelated events contribute variance to long-term returns. We propose state-associative (SA) learning, where the agent learns associations between states and arbitrarily distant future rewards, then propagates credit directly between the two. In this work, we use SA-learning to model the contribution of past states to the current reward. With this model we can predict each state's contribution to the far future, a quantity we call "synthetic returns". TD-learning can then be applied to select actions that maximize these synthetic returns (SRs). We demonstrate the effectiveness of augmenting agents with SRs across a range of tasks on which TD-learning alone fails. We show that the learned SRs are interpretable: they spike for states that occur after critical actions are taken. Finally, we show that our IMPALA-based SR agent solves Atari Skiing -- a game with a lengthy reward delay that posed a major hurdle to deep-RL agents -- 25 times faster than the published state-of-the-art.
Rapid Task-Solving in Novel Environments
Jun 05, 2020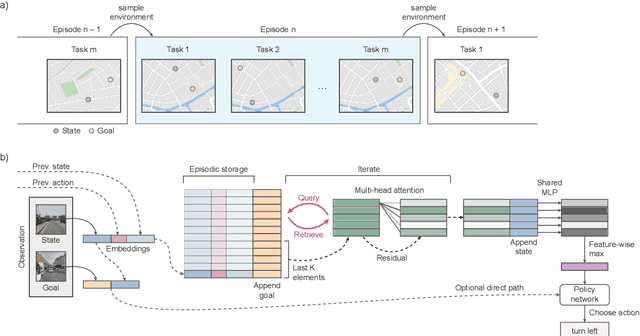

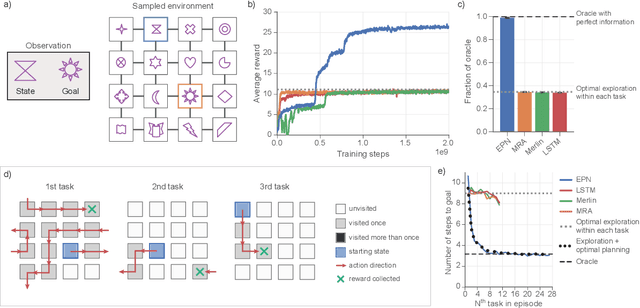
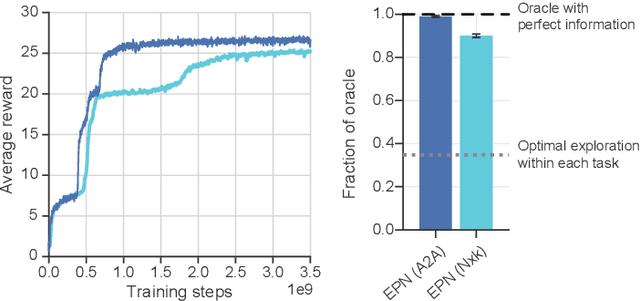
When thrust into an unfamiliar environment and charged with solving a series of tasks, an effective agent should (1) leverage prior knowledge to solve its current task while (2) efficiently exploring to gather knowledge for use in future tasks, and then (3) plan using that knowledge when faced with new tasks in that same environment. We introduce two domains for conducting research on this challenge, and find that state-of-the-art deep reinforcement learning (RL) agents fail to plan in novel environments. We develop a recursive implicit planning module that operates over episodic memories, and show that the resulting deep-RL agent is able to explore and plan in novel environments, outperforming the nearest baseline by factors of 2-3 across the two domains. We find evidence that our module (1) learned to execute a sensible information-propagating algorithm and (2) generalizes to situations beyond its training experience.