 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Depths: Dynamically allocating compute in transformer-based language models
Apr 02, 2024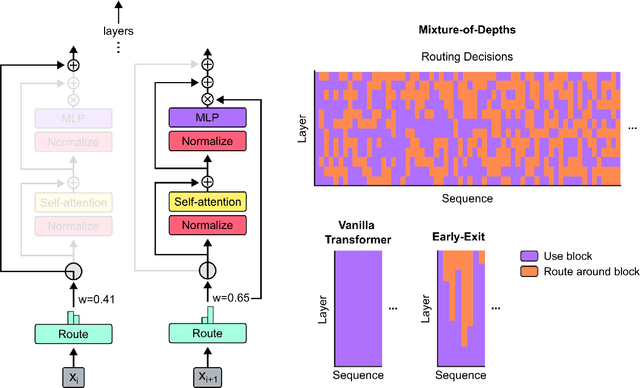
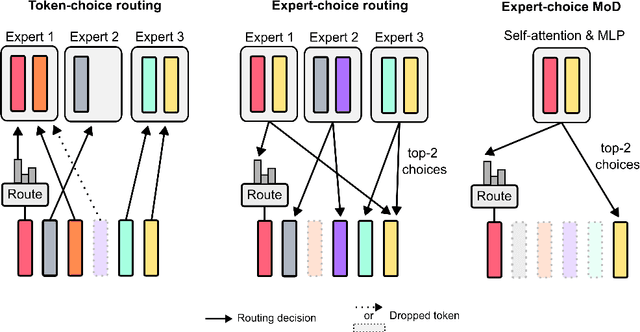
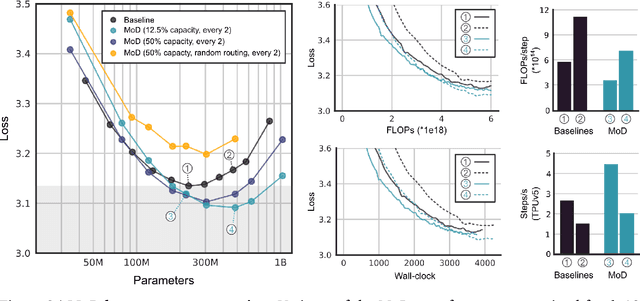
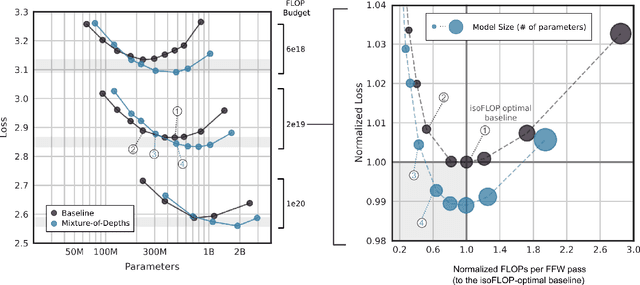
Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens ($k$) that can participate in the self-attention and MLP computations at a given layer. The tokens to be processed are determined by the network using a top-$k$ routing mechanism. Since $k$ is defined a priori, this simple procedure uses a static computation graph with known tensor sizes, unlike other conditional computation techniques. Nevertheless, since the identities of the $k$ tokens are fluid, this method can expend FLOPs non-uniformly across the time and model depth dimensions. Thus, compute expenditure is entirely predictable in sum total, but dynamic and context-sensitive at the token-level. Not only do models trained in this way learn to dynamically allocate compute, they do so efficiently. These models match baseline performance for equivalent FLOPS and wall-clock times to train, but require a fraction of the FLOPs per forward pass, and can be upwards of 50\% faster to step during post-training sampling.
A data-driven approach for learning to control computers
Feb 16, 2022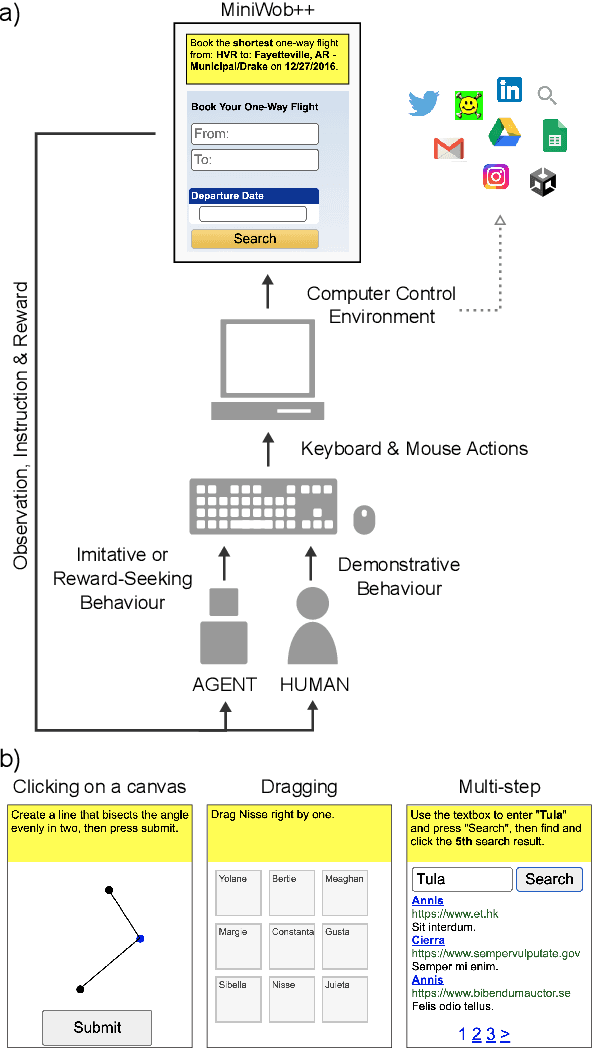
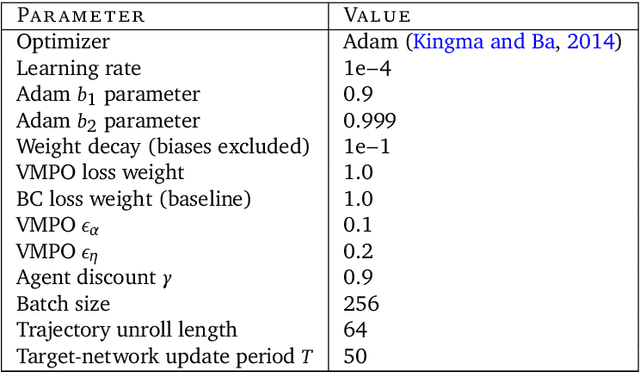
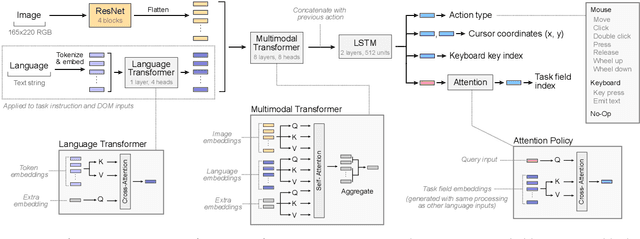
It would be useful for machines to use computers as humans do so that they can aid us in everyday tasks. This is a setting in which there is also the potential to leverage large-scale expert demonstrations and human judgements of interactive behaviour, which are two ingredients that have driven much recent success in AI. Here we investigate the setting of computer control using keyboard and mouse, with goals specified via natural language. Instead of focusing on hand-designed curricula and specialized action spaces, we focus on developing a scalable method centered on reinforcement learning combined with behavioural priors informed by actual human-computer interactions. We achieve state-of-the-art and human-level mean performance across all tasks within the MiniWob++ benchmark, a challenging suite of computer control problems, and find strong evidence of cross-task transfer. These results demonstrate the usefulness of a unified human-agent interface when training machines to use computers. Altogether our results suggest a formula for achieving competency beyond MiniWob++ and towards controlling computers, in general, as a human would.
Synthetic Returns for Long-Term Credit Assignment
Feb 24, 2021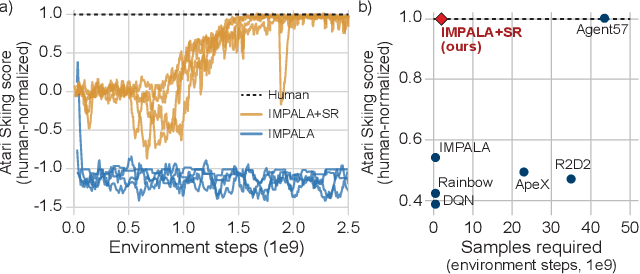
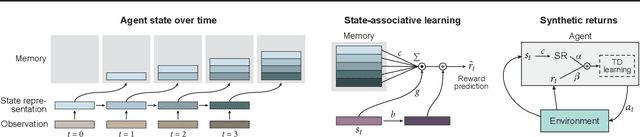
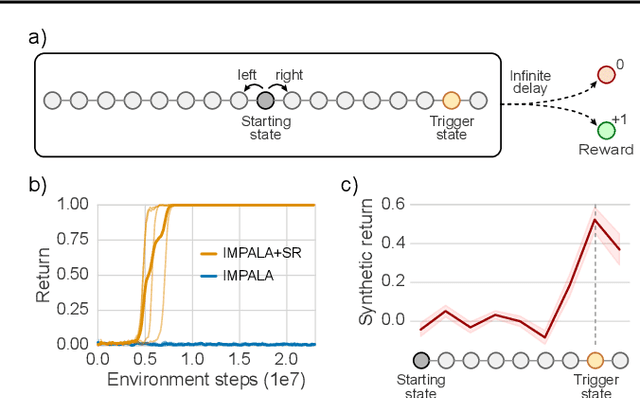
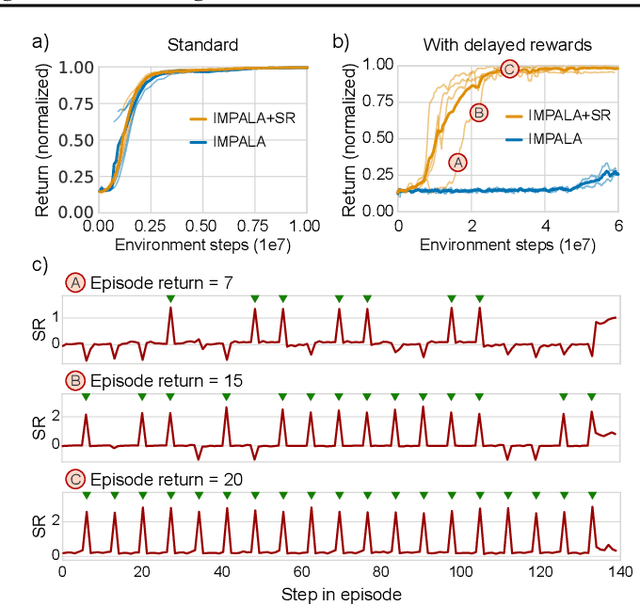
Since the earliest days of reinforcement learning, the workhorse method for assigning credit to actions over time has been temporal-difference (TD) learning, which propagates credit backward timestep-by-timestep. This approach suffers when delays between actions and rewards are long and when intervening unrelated events contribute variance to long-term returns. We propose state-associative (SA) learning, where the agent learns associations between states and arbitrarily distant future rewards, then propagates credit directly between the two. In this work, we use SA-learning to model the contribution of past states to the current reward. With this model we can predict each state's contribution to the far future, a quantity we call "synthetic returns". TD-learning can then be applied to select actions that maximize these synthetic returns (SRs). We demonstrate the effectiveness of augmenting agents with SRs across a range of tasks on which TD-learning alone fails. We show that the learned SRs are interpretable: they spike for states that occur after critical actions are taken. Finally, we show that our IMPALA-based SR agent solves Atari Skiing -- a game with a lengthy reward delay that posed a major hurdle to deep-RL agents -- 25 times faster than the published state-of-the-art.
Symbolic Behaviour in Artificial Intelligence
Feb 05, 2021The ability to use symbols is the pinnacle of human intelligence, but has yet to be fully replicated in machines. Here we argue that the path towards symbolically fluent artificial intelligence (AI) begins with a reinterpretation of what symbols are, how they come to exist, and how a system behaves when it uses them. We begin by offering an interpretation of symbols as entities whose meaning is established by convention. But crucially, something is a symbol only for those who demonstrably and actively participate in this convention. We then outline how this interpretation thematically unifies the behavioural traits humans exhibit when they use symbols. This motivates our proposal that the field place a greater emphasis on symbolic behaviour rather than particular computational mechanisms inspired by more restrictive interpretations of symbols. Finally, we suggest that AI research explore social and cultural engagement as a tool to develop the cognitive machinery necessary for symbolic behaviour to emerge. This approach will allow for AI to interpret something as symbolic on its own rather than simply manipulate things that are only symbols to human onlookers, and thus will ultimately lead to AI with more human-like symbolic fluency.
Rapid Task-Solving in Novel Environments
Jun 05, 2020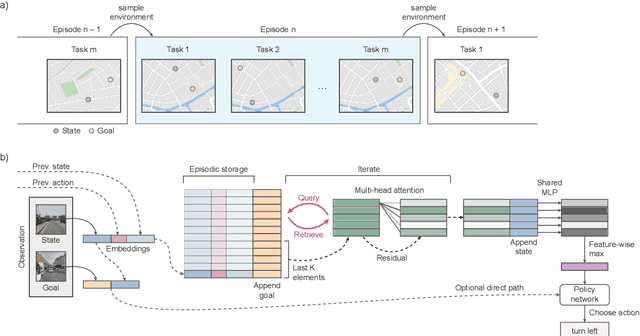

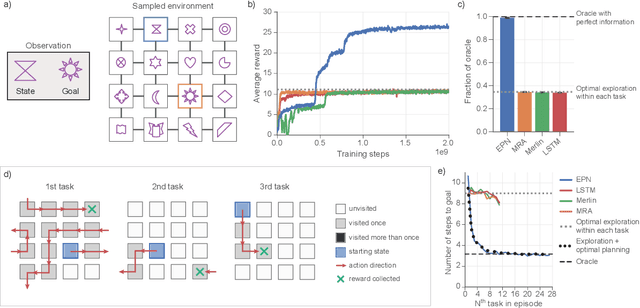
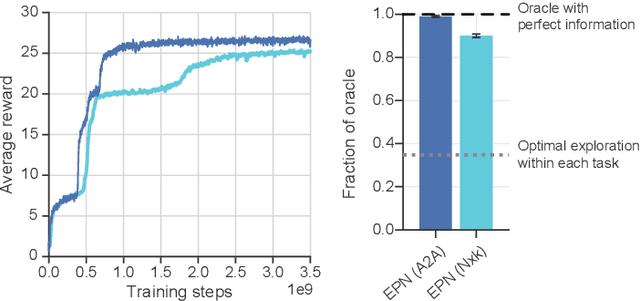
When thrust into an unfamiliar environment and charged with solving a series of tasks, an effective agent should (1) leverage prior knowledge to solve its current task while (2) efficiently exploring to gather knowledge for use in future tasks, and then (3) plan using that knowledge when faced with new tasks in that same environment. We introduce two domains for conducting research on this challenge, and find that state-of-the-art deep reinforcement learning (RL) agents fail to plan in novel environments. We develop a recursive implicit planning module that operates over episodic memories, and show that the resulting deep-RL agent is able to explore and plan in novel environments, outperforming the nearest baseline by factors of 2-3 across the two domains. We find evidence that our module (1) learned to execute a sensible information-propagating algorithm and (2) generalizes to situations beyond its training experience.
Is coding a relevant metaphor for building AI? A commentary on "Is coding a relevant metaphor for the brain?", by Romain Brette
Apr 18, 2019Brette contends that the neural coding metaphor is an invalid basis for theories of what the brain does. Here, we argue that it is an insufficient guide for building an artificial intelligence that learns to accomplish short- and long-term goals in a complex, changing environment.
Causal Reasoning from Meta-reinforcement Learning
Jan 23, 2019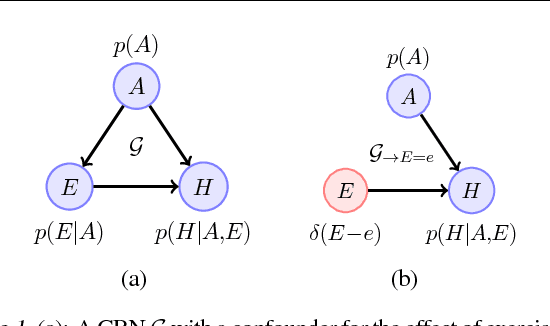


Discovering and exploiting the causal structure in the environment is a crucial challenge for intelligent agents. Here we explore whether causal reasoning can emerge via meta-reinforcement learning. We train a recurrent network with model-free reinforcement learning to solve a range of problems that each contain causal structure. We find that the trained agent can perform causal reasoning in novel situations in order to obtain rewards. The agent can select informative interventions, draw causal inferences from observational data, and make counterfactual predictions. Although established formal causal reasoning algorithms also exist, in this paper we show that such reasoning can arise from model-free reinforcement learning, and suggest that causal reasoning in complex settings may benefit from the more end-to-end learning-based approaches presented here. This work also offers new strategies for structured exploration in reinforcement learning, by providing agents with the ability to perform -- and interpret -- experiments.
An investigation of model-free planning
Jan 11, 2019
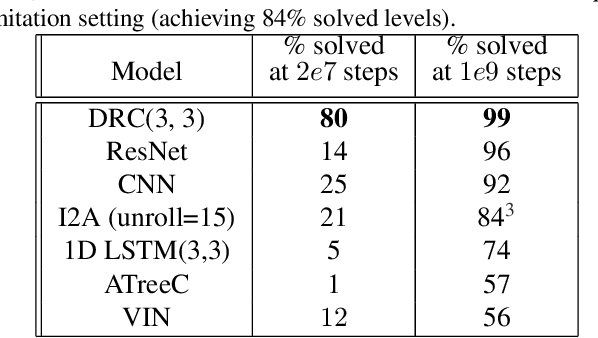
The field of reinforcement learning (RL) is facing increasingly challenging domains with combinatorial complexity. For an RL agent to address these challenges, it is essential that it can plan effectively. Prior work has typically utilized an explicit model of the environment, combined with a specific planning algorithm (such as tree search). More recently, a new family of methods have been proposed that learn how to plan, by providing the structure for planning via an inductive bias in the function approximator (such as a tree structured neural network), trained end-to-end by a model-free RL algorithm. In this paper, we go even further, and demonstrate empirically that an entirely model-free approach, without special structure beyond standard neural network components such as convolutional networks and LSTMs, can learn to exhibit many of the characteristics typically associated with a model-based planner. We measure our agent's effectiveness at planning in terms of its ability to generalize across a combinatorial and irreversible state space, its data efficiency, and its ability to utilize additional thinking time. We find that our agent has many of the characteristics that one might expect to find in a planning algorithm. Furthermore, it exceeds the state-of-the-art in challenging combinatorial domains such as Sokoban and outperforms other model-free approaches that utilize strong inductive biases toward planning.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
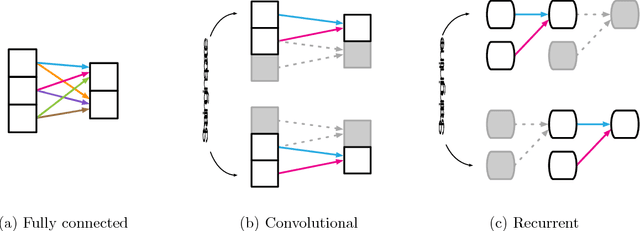
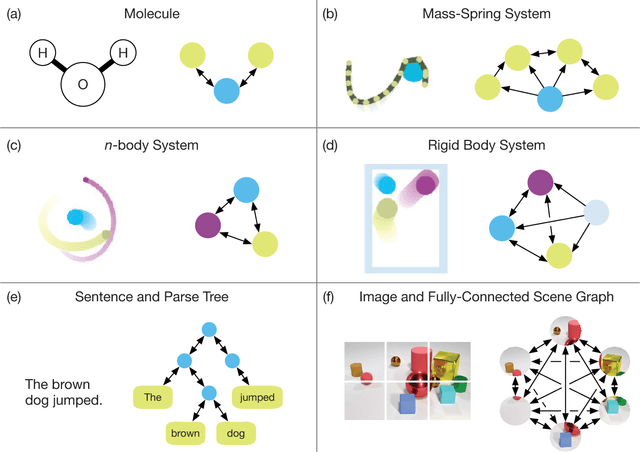
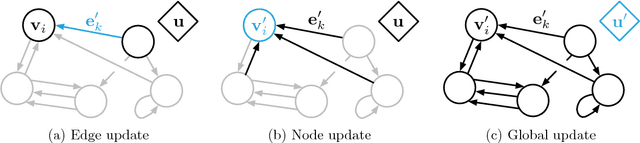
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Relational recurrent neural networks
Jun 28, 2018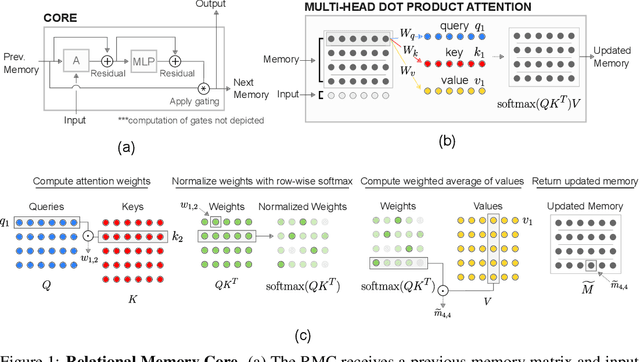
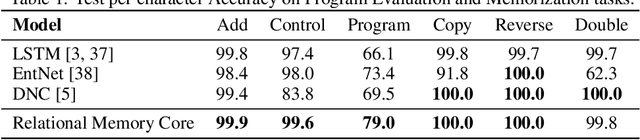
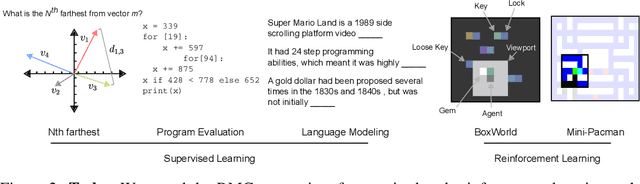
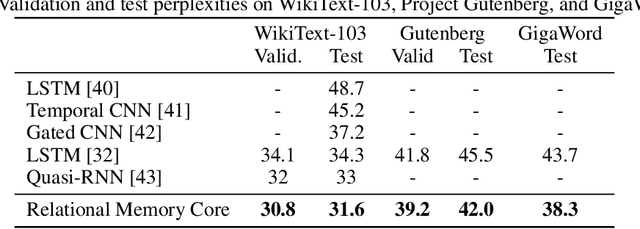
Memory-based neural networks model temporal data by leveraging an ability to remember information for long periods. It is unclear, however, whether they also have an ability to perform complex relational reasoning with the information they remember. Here, we first confirm our intuitions that standard memory architectures may struggle at tasks that heavily involve an understanding of the ways in which entities are connected -- i.e., tasks involving relational reasoning. We then improve upon these deficits by using a new memory module -- a \textit{Relational Memory Core} (RMC) -- which employs multi-head dot product attention to allow memories to interact. Finally, we test the RMC on a suite of tasks that may profit from more capable relational reasoning across sequential information, and show large gains in RL domains (e.g. Mini PacMan), program evaluation, and language modeling, achieving state-of-the-art results on the WikiText-103, Project Gutenberg, and GigaWord datasets.