 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordances Enable Partial World Modeling with LLMs
Feb 11, 2026Full models of the world require complex knowledge of immense detail. While pre-trained large models have been hypothesized to contain similar knowledge due to extensive pre-training on vast amounts of internet scale data, using them directly in a search procedure is inefficient and inaccurate. Conversely, partial models focus on making high quality predictions for a subset of state and actions: those linked through affordances that achieve user intents~\citep{khetarpal2020can}. Can we posit large models as partial world models? We provide a formal answer to this question, proving that agents achieving task-agnostic, language-conditioned intents necessarily possess predictive partial-world models informed by affordances. In the multi-task setting, we introduce distribution-robust affordances and show that partial models can be extracted to significantly improve search efficiency. Empirical evaluations in tabletop robotics tasks demonstrate that our affordance-aware partial models reduce the search branching factor and achieve higher rewards compared to full world models.
Understanding Prompt Tuning and In-Context Learning via Meta-Learning
May 22, 2025Prompting is one of the main ways to adapt a pretrained model to target tasks. Besides manually constructing prompts, many prompt optimization methods have been proposed in the literature. Method development is mainly empirically driven, with less emphasis on a conceptual understanding of prompting. In this paper we discuss how optimal prompting can be understood through a Bayesian view, which also implies some fundamental limitations of prompting that can only be overcome by tuning weights. The paper explains in detail how meta-trained neural networks behave as Bayesian predictors over the pretraining distribution, whose hallmark feature is rapid in-context adaptation. Optimal prompting can be studied formally as conditioning these Bayesian predictors, yielding criteria for target tasks where optimal prompting is and is not possible. We support the theory with educational experiments on LSTMs and Transformers, where we compare different versions of prefix-tuning and different weight-tuning methods. We also confirm that soft prefixes, which are sequences of real-valued vectors outside the token alphabet, can lead to very effective prompts for trained and even untrained networks by manipulating activations in ways that are not achievable by hard tokens. This adds an important mechanistic aspect beyond the conceptual Bayesian theory.
Exponential Speedups by Rerooting Levin Tree Search
Dec 06, 2024Levin Tree Search (LTS) (Orseau et al., 2018) is a search algorithm for deterministic environments that uses a user-specified policy to guide the search. It comes with a formal guarantee on the number of search steps for finding a solution node that depends on the quality of the policy. In this paper, we introduce a new algorithm, called $\sqrt{\text{LTS}}$ (pronounce root-LTS), which implicitly starts an LTS search rooted at every node of the search tree. Each LTS search is assigned a rerooting weight by a (user-defined or learnt) rerooter, and the search effort is shared between all LTS searches proportionally to their weights. The rerooting mechanism implicitly decomposes the search space into subtasks, leading to significant speedups. We prove that the number of search steps that $\sqrt{\text{LTS}}$ takes is competitive with the best decomposition into subtasks, at the price of a factor that relates to the uncertainty of the rerooter. If LTS takes time $T$, in the best case with $q$ rerooting points, $\sqrt{\text{LTS}}$ only takes time $O(q\sqrt[q]{T})$. Like the policy, the rerooter can be learnt from data, and we expect $\sqrt{\text{LTS}}$ to be applicable to a wide range of domains.
Super-Exponential Regret for UCT, AlphaGo and Variants
May 07, 2024We improve the proofs of the lower bounds of Coquelin and Munos (2007) that demonstrate that UCT can have $\exp(\dots\exp(1)\dots)$ regret (with $\Omega(D)$ exp terms) on the $D$-chain environment, and that a `polynomial' UCT variant has $\exp_2(\exp_2(D - O(\log D)))$ regret on the same environment -- the original proofs contain an oversight for rewards bounded in $[0, 1]$, which we fix in the present draft. We also adapt the proofs to AlphaGo's MCTS and its descendants (e.g., AlphaZero, Leela Zero) to also show $\exp_2(\exp_2(D - O(\log D)))$ regret.
Learning Universal Predictors
Jan 26, 2024



Meta-learning has emerged as a powerful approach to train neural networks to learn new tasks quickly from limited data. Broad exposure to different tasks leads to versatile representations enabling general problem solving. But, what are the limits of meta-learning? In this work, we explore the potential of amortizing the most powerful universal predictor, namely Solomonoff Induction (SI), into neural networks via leveraging meta-learning to its limits. We use Universal Turing Machines (UTMs) to generate training data used to expose networks to a broad range of patterns. We provide theoretical analysis of the UTM data generation processes and meta-training protocols. We conduct comprehensive experiments with neural architectures (e.g. LSTMs, Transformers) and algorithmic data generators of varying complexity and universality. Our results suggest that UTM data is a valuable resource for meta-learning, and that it can be used to train neural networks capable of learning universal prediction strategies.
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search
Nov 06, 2023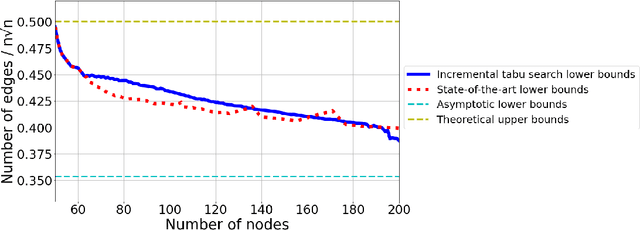
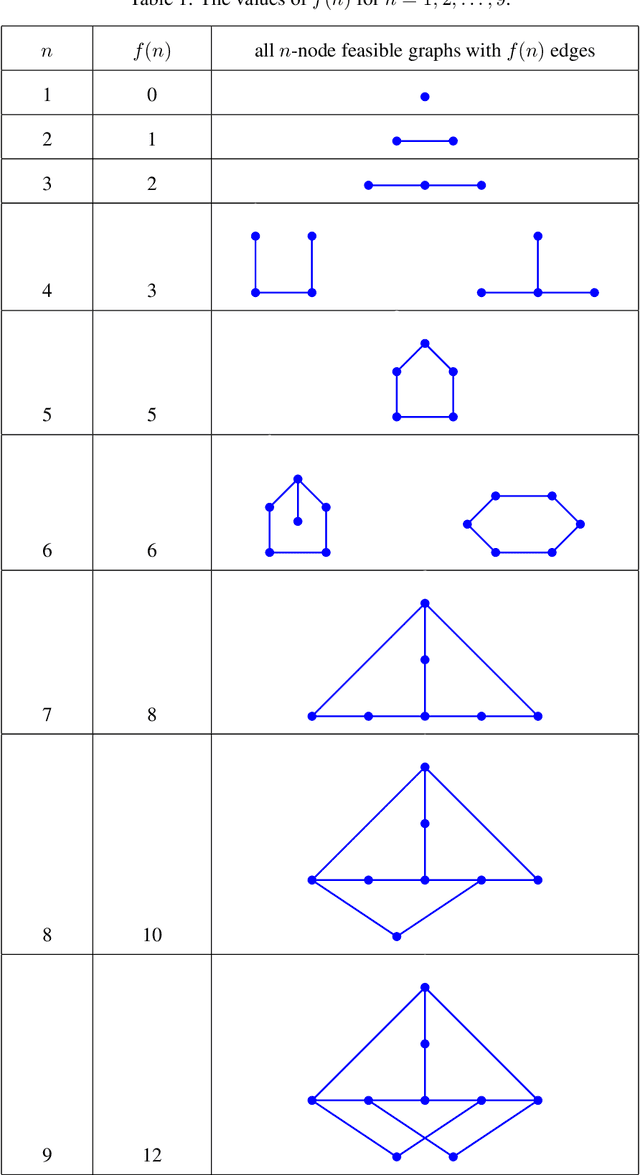
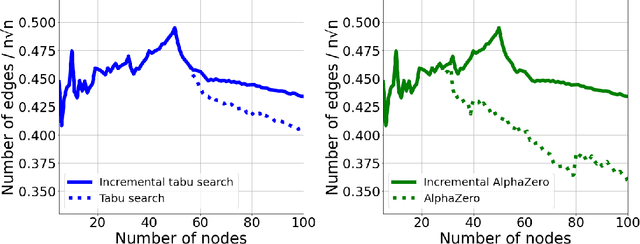

This work studies a central extremal graph theory problem inspired by a 1975 conjecture of Erd\H{o}s, which aims to find graphs with a given size (number of nodes) that maximize the number of edges without having 3- or 4-cycles. We formulate this problem as a sequential decision-making problem and compare AlphaZero, a neural network-guided tree search, with tabu search, a heuristic local search method. Using either method, by introducing a curriculum -- jump-starting the search for larger graphs using good graphs found at smaller sizes -- we improve the state-of-the-art lower bounds for several sizes. We also propose a flexible graph-generation environment and a permutation-invariant network architecture for learning to search in the space of graphs.
Language Modeling Is Compression
Sep 19, 2023It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
Line Search for Convex Minimization
Jul 31, 2023Golden-section search and bisection search are the two main principled algorithms for 1d minimization of quasiconvex (unimodal) functions. The first one only uses function queries, while the second one also uses gradient queries. Other algorithms exist under much stronger assumptions, such as Newton's method. However, to the best of our knowledge, there is no principled exact line search algorithm for general convex functions -- including piecewise-linear and max-compositions of convex functions -- that takes advantage of convexity. We propose two such algorithms: $\Delta$-Bisection is a variant of bisection search that uses (sub)gradient information and convexity to speed up convergence, while $\Delta$-Secant is a variant of golden-section search and uses only function queries. While bisection search reduces the $x$ interval by a factor 2 at every iteration, $\Delta$-Bisection reduces the (sometimes much) smaller $x^*$-gap $\Delta^x$ (the $x$ coordinates of $\Delta$) by at least a factor 2 at every iteration. Similarly, $\Delta$-Secant also reduces the $x^*$-gap by at least a factor 2 every second function query. Moreover, the $y^*$-gap $\Delta^y$ (the $y$ coordinates of $\Delta$) also provides a refined stopping criterion, which can also be used with other algorithms. Experiments on a few convex functions confirm that our algorithms are always faster than their quasiconvex counterparts, often by more than a factor 2. We further design a quasi-exact line search algorithm based on $\Delta$-Secant. It can be used with gradient descent as a replacement for backtracking line search, for which some parameters can be finicky to tune -- and we provide examples to this effect, on strongly-convex and smooth functions. We provide convergence guarantees, and confirm the efficiency of quasi-exact line search on a few single- and multivariate convex functions.
Levin Tree Search with Context Models
May 26, 2023



Levin Tree Search (LTS) is a search algorithm that makes use of a policy (a probability distribution over actions) and comes with a theoretical guarantee on the number of expansions before reaching a goal node, depending on the quality of the policy. This guarantee can be used as a loss function, which we call the LTS loss, to optimize neural networks representing the policy (LTS+NN). In this work we show that the neural network can be substituted with parameterized context models originating from the online compression literature (LTS+CM). We show that the LTS loss is convex under this new model, which allows for using standard convex optimization tools, and obtain convergence guarantees to the optimal parameters in an online setting for a given set of solution trajectories -- guarantees that cannot be provided for neural networks. The new LTS+CM algorithm compares favorably against LTS+NN on several benchmarks: Sokoban (Boxoban), The Witness, and the 24-Sliding Tile puzzle (STP). The difference is particularly large on STP, where LTS+NN fails to solve most of the test instances while LTS+CM solves each test instance in a fraction of a second. Furthermore, we show that LTS+CM is able to learn a policy that solves the Rubik's cube in only a few hundred expansions, which considerably improves upon previous machine learning techniques.
Memory-Based Meta-Learning on Non-Stationary Distributions
Feb 06, 2023Memory-based meta-learning is a technique for approximating Bayes-optimal predictors. Under fairly general conditions, minimizing sequential prediction error, measured by the log loss, leads to implicit meta-learning. The goal of this work is to investigate how far this interpretation can be realized by current sequence prediction models and training regimes. The focus is on piecewise stationary sources with unobserved switching-points, which arguably capture an important characteristic of natural language and action-observation sequences in partially observable environments. We show that various types of memory-based neural models, including Transformers, LSTMs, and RNNs can learn to accurately approximate known Bayes-optimal algorithms and behave as if performing Bayesian inference over the latent switching-points and the latent parameters governing the data distribution within each segment.