 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Induced Information for Rerooting Levin Tree Search
May 28, 2026Subgoal-based policy tree search, which uses a policy to guide search, is effective for complex single-agent deterministic problems but often relies on explicit subgoal generation that can incur substantial overhead and hinders scalability. In this paper, we overcome these limitations by using a learned ``rerooter'' through the recently-introduced $\sqrt{\text{LTS}}$ algorithm. A rerooter implicitly decomposes the problem into soft subtasks. While previous work focused on the formal guarantees for given or handcrafted rerooters, in this work we propose three rerooter designs: (i) a clustering-based rerooter that exploits global state-space structure, (ii) a heuristic-based rerooter that leverages learned cost-to-go estimates, and (iii) a hybrid that combines both signals. Our framework avoids having to explicitly reconstruct and reason over generated subgoals, thereby enabling scalable allocation of search effort with significantly lower computational overhead. Empirically, our rerooting-based methods scale to complex environments where subgoal-based policy tree search fails, and achieve state-of-the-art online training efficiency on the domains tested.
Gradient-Based Program Synthesis with Neurally Interpreted Languages
Apr 20, 2026A central challenge in program induction has long been the trade-off between symbolic and neural approaches. Symbolic methods offer compositional generalisation and data efficiency, yet their scalability is constrained by formalisms such as domain-specific languages (DSLs), which are labour-intensive to create and may not transfer to new domains. In contrast, neural networks flexibly learn from data but tend to generalise poorly in compositional and out-of-distribution settings. We bridge this divide with an instance of a Latent Adaptation Network architecture named Neural Language Interpreter (NLI), which learns its own discrete, symbolic-like programming language end-to-end. NLI autonomously discovers a vocabulary of primitive operations and uses a novel differentiable neural executor to interpret variable-length sequences of these primitives. This allows NLI to represent programs that are not bound to a constant number of computation steps, enabling it to solve more complex problems than those seen during training. To make these discrete, compositional program structures amenable to gradient-based optimisation, we employ the Gumbel-Softmax relaxation, enabling the entire model to be trained end-to-end. Crucially, this same differentiability enables powerful test-time adaptation. At inference, NLI's program inductor provides an initial program guess. This guess is then refined via gradient descent through the neural executor, enabling efficient search for the neural program that best explains the given data. We demonstrate that NLI outperforms in-context learning, test-time training, and continuous latent program networks on tasks that require combinatorial generalisation and rapid adaptation to unseen tasks. Our results establish a new path toward models that combine the compositionality of discrete languages with the gradient-based search and end-to-end learning of neural networks.
Common Benchmarks Undervalue the Generalization Power of Programmatic Policies
Jun 17, 2025
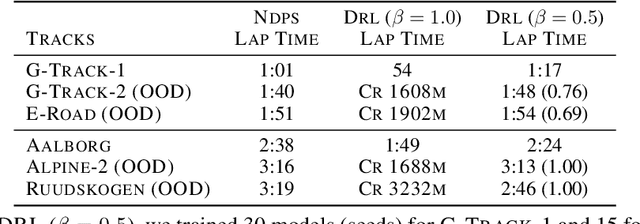


Algorithms for learning programmatic representations for sequential decision-making problems are often evaluated on out-of-distribution (OOD) problems, with the common conclusion that programmatic policies generalize better than neural policies on OOD problems. In this position paper, we argue that commonly used benchmarks undervalue the generalization capabilities of programmatic representations. We analyze the experiments of four papers from the literature and show that neural policies, which were shown not to generalize, can generalize as effectively as programmatic policies on OOD problems. This is achieved with simple changes in the neural policies training pipeline. Namely, we show that simpler neural architectures with the same type of sparse observation used with programmatic policies can help attain OOD generalization. Another modification we have shown to be effective is the use of reward functions that allow for safer policies (e.g., agents that drive slowly can generalize better). Also, we argue for creating benchmark problems highlighting concepts needed for OOD generalization that may challenge neural policies but align with programmatic representations, such as tasks requiring algorithmic constructs like stacks.
Subgoal-Guided Policy Heuristic Search with Learned Subgoals
Jun 08, 2025Policy tree search is a family of tree search algorithms that use a policy to guide the search. These algorithms provide guarantees on the number of expansions required to solve a given problem that are based on the quality of the policy. While these algorithms have shown promising results, the process in which they are trained requires complete solution trajectories to train the policy. Search trajectories are obtained during a trial-and-error search process. When the training problem instances are hard, learning can be prohibitively costly, especially when starting from a randomly initialized policy. As a result, search samples are wasted in failed attempts to solve these hard instances. This paper introduces a novel method for learning subgoal-based policies for policy tree search algorithms. The subgoals and policies conditioned on subgoals are learned from the trees that the search expands while attempting to solve problems, including the search trees of failed attempts. We empirically show that our policy formulation and training method improve the sample efficiency of learning a policy and heuristic function in this online setting.
InnateCoder: Learning Programmatic Options with Foundation Models
May 18, 2025Outside of transfer learning settings, reinforcement learning agents start their learning process from a clean slate. As a result, such agents have to go through a slow process to learn even the most obvious skills required to solve a problem. In this paper, we present InnateCoder, a system that leverages human knowledge encoded in foundation models to provide programmatic policies that encode "innate skills" in the form of temporally extended actions, or options. In contrast to existing approaches to learning options, InnateCoder learns them from the general human knowledge encoded in foundation models in a zero-shot setting, and not from the knowledge the agent gains by interacting with the environment. Then, InnateCoder searches for a programmatic policy by combining the programs encoding these options into larger and more complex programs. We hypothesized that InnateCoder's way of learning and using options could improve the sampling efficiency of current methods for learning programmatic policies. Empirical results in MicroRTS and Karel the Robot support our hypothesis, since they show that InnateCoder is more sample efficient than versions of the system that do not use options or learn them from experience.
Exponential Speedups by Rerooting Levin Tree Search
Dec 06, 2024Levin Tree Search (LTS) (Orseau et al., 2018) is a search algorithm for deterministic environments that uses a user-specified policy to guide the search. It comes with a formal guarantee on the number of search steps for finding a solution node that depends on the quality of the policy. In this paper, we introduce a new algorithm, called $\sqrt{\text{LTS}}$ (pronounce root-LTS), which implicitly starts an LTS search rooted at every node of the search tree. Each LTS search is assigned a rerooting weight by a (user-defined or learnt) rerooter, and the search effort is shared between all LTS searches proportionally to their weights. The rerooting mechanism implicitly decomposes the search space into subtasks, leading to significant speedups. We prove that the number of search steps that $\sqrt{\text{LTS}}$ takes is competitive with the best decomposition into subtasks, at the price of a factor that relates to the uncertainty of the rerooter. If LTS takes time $T$, in the best case with $q$ rerooting points, $\sqrt{\text{LTS}}$ only takes time $O(q\sqrt[q]{T})$. Like the policy, the rerooter can be learnt from data, and we expect $\sqrt{\text{LTS}}$ to be applicable to a wide range of domains.
Reclaiming the Source of Programmatic Policies: Programmatic versus Latent Spaces
Oct 16, 2024Recent works have introduced LEAPS and HPRL, systems that learn latent spaces of domain-specific languages, which are used to define programmatic policies for partially observable Markov decision processes (POMDPs). These systems induce a latent space while optimizing losses such as the behavior loss, which aim to achieve locality in program behavior, meaning that vectors close in the latent space should correspond to similarly behaving programs. In this paper, we show that the programmatic space, induced by the domain-specific language and requiring no training, presents values for the behavior loss similar to those observed in latent spaces presented in previous work. Moreover, algorithms searching in the programmatic space significantly outperform those in LEAPS and HPRL. To explain our results, we measured the "friendliness" of the two spaces to local search algorithms. We discovered that algorithms are more likely to stop at local maxima when searching in the latent space than when searching in the programmatic space. This implies that the optimization topology of the programmatic space, induced by the reward function in conjunction with the neighborhood function, is more conducive to search than that of the latent space. This result provides an explanation for the superior performance in the programmatic space.
Unveiling Options with Neural Decomposition
Oct 15, 2024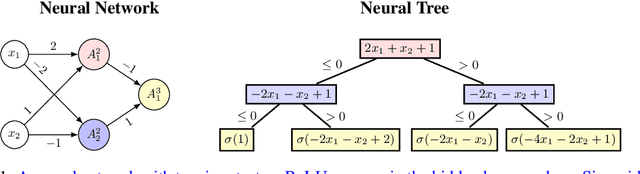



In reinforcement learning, agents often learn policies for specific tasks without the ability to generalize this knowledge to related tasks. This paper introduces an algorithm that attempts to address this limitation by decomposing neural networks encoding policies for Markov Decision Processes into reusable sub-policies, which are used to synthesize temporally extended actions, or options. We consider neural networks with piecewise linear activation functions, so that they can be mapped to an equivalent tree that is similar to oblique decision trees. Since each node in such a tree serves as a function of the input of the tree, each sub-tree is a sub-policy of the main policy. We turn each of these sub-policies into options by wrapping it with while-loops of varied number of iterations. Given the large number of options, we propose a selection mechanism based on minimizing the Levin loss for a uniform policy on these options. Empirical results in two grid-world domains where exploration can be difficult confirm that our method can identify useful options, thereby accelerating the learning process on similar but different tasks.
Searching for Programmatic Policies in Semantic Spaces
May 08, 2024Syntax-guided synthesis is commonly used to generate programs encoding policies. In this approach, the set of programs, that can be written in a domain-specific language defines the search space, and an algorithm searches within this space for programs that encode strong policies. In this paper, we propose an alternative method for synthesizing programmatic policies, where we search within an approximation of the language's semantic space. We hypothesized that searching in semantic spaces is more sample-efficient compared to syntax-based spaces. Our rationale is that the search is more efficient if the algorithm evaluates different agent behaviors as it searches through the space, a feature often missing in syntax-based spaces. This is because small changes in the syntax of a program often do not result in different agent behaviors. We define semantic spaces by learning a library of programs that present different agent behaviors. Then, we approximate the semantic space by defining a neighborhood function for local search algorithms, where we replace parts of the current candidate program with programs from the library. We evaluated our hypothesis in a real-time strategy game called MicroRTS. Empirical results support our hypothesis that searching in semantic spaces can be more sample-efficient than searching in syntax-based spaces.
Assessing the Interpretability of Programmatic Policies with Large Language Models
Nov 12, 2023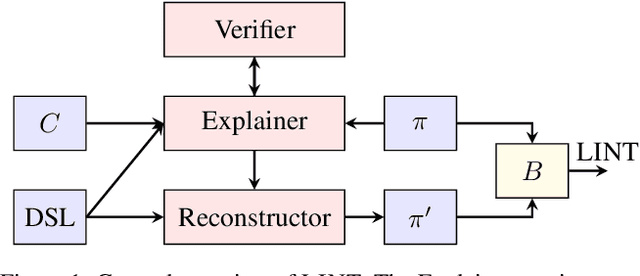


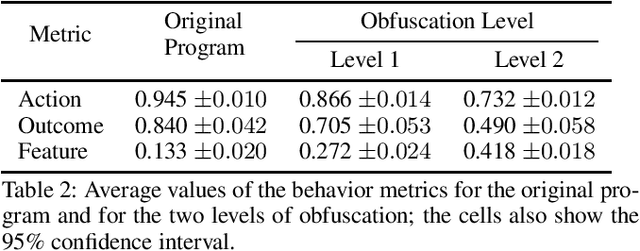
Although the synthesis of programs encoding policies often carries the promise of interpretability, systematic evaluations to assess the interpretability of these policies were never performed, likely because of the complexity of such an evaluation. In this paper, we introduce a novel metric that uses large-language models (LLM) to assess the interpretability of programmatic policies. For our metric, an LLM is given both a program and a description of its associated programming language. The LLM then formulates a natural language explanation of the program. This explanation is subsequently fed into a second LLM, which tries to reconstruct the program from the natural language explanation. Our metric measures the behavioral similarity between the reconstructed program and the original. We validate our approach using obfuscated programs that are used to solve classic programming problems. We also assess our metric with programmatic policies synthesized for playing a real-time strategy game, comparing the interpretability scores of programmatic policies synthesized by an existing system to lightly obfuscated versions of the same programs. Our LLM-based interpretability score consistently ranks less interpretable programs lower and more interpretable ones higher. These findings suggest that our metric could serve as a reliable and inexpensive tool for evaluating the interpretability of programmatic policies.