 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployment of Deep Learning Model in Real World Clinical Setting: A Case Study in Obstetric Ultrasound
Mar 22, 2024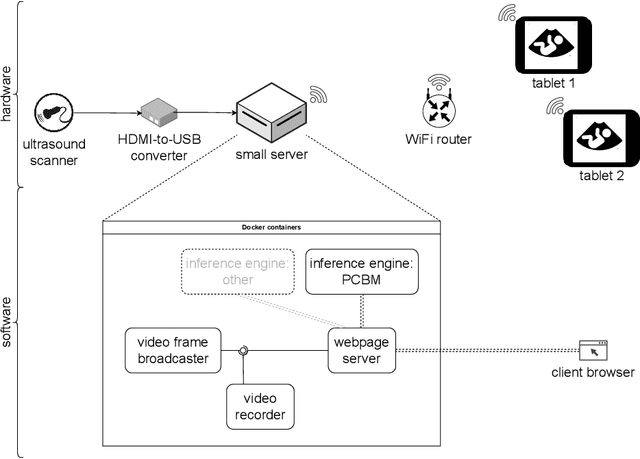

Despite the rapid development of AI models in medical image analysis, their validation in real-world clinical settings remains limited. To address this, we introduce a generic framework designed for deploying image-based AI models in such settings. Using this framework, we deployed a trained model for fetal ultrasound standard plane detection, and evaluated it in real-time sessions with both novice and expert users. Feedback from these sessions revealed that while the model offers potential benefits to medical practitioners, the need for navigational guidance was identified as a key area for improvement. These findings underscore the importance of early deployment of AI models in real-world settings, leading to insights that can guide the refinement of the model and system based on actual user feedback.
Diffusion-based Iterative Counterfactual Explanations for Fetal Ultrasound Image Quality Assessment
Mar 13, 2024



Obstetric ultrasound image quality is crucial for accurate diagnosis and monitoring of fetal health. However, producing high-quality standard planes is difficult, influenced by the sonographer's expertise and factors like the maternal BMI or the fetus dynamics. In this work, we propose using diffusion-based counterfactual explainable AI to generate realistic high-quality standard planes from low-quality non-standard ones. Through quantitative and qualitative evaluation, we demonstrate the effectiveness of our method in producing plausible counterfactuals of increased quality. This shows future promise both for enhancing training of clinicians by providing visual feedback, as well as for improving image quality and, consequently, downstream diagnosis and monitoring.
Shortcut Learning in Medical Image Segmentation
Mar 11, 2024Shortcut learning is a phenomenon where machine learning models prioritize learning simple, potentially misleading cues from data that do not generalize well beyond the training set. While existing research primarily investigates this in the realm of image classification, this study extends the exploration of shortcut learning into medical image segmentation. We demonstrate that clinical annotations such as calipers, and the combination of zero-padded convolutions and center-cropped training sets in the dataset can inadvertently serve as shortcuts, impacting segmentation accuracy. We identify and evaluate the shortcut learning on two different but common medical image segmentation tasks. In addition, we suggest strategies to mitigate the influence of shortcut learning and improve the generalizability of the segmentation models. By uncovering the presence and implications of shortcuts in medical image segmentation, we provide insights and methodologies for evaluating and overcoming this pervasive challenge and call for attention in the community for shortcuts in segmentation.
Learning semantic image quality for fetal ultrasound from noisy ranking annotation
Feb 13, 2024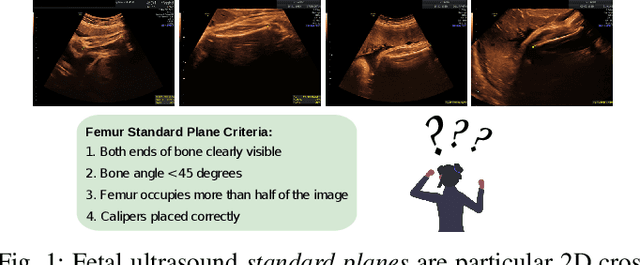
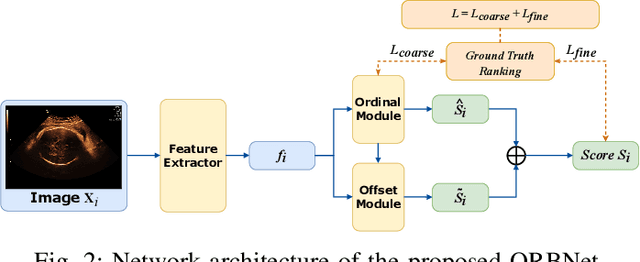
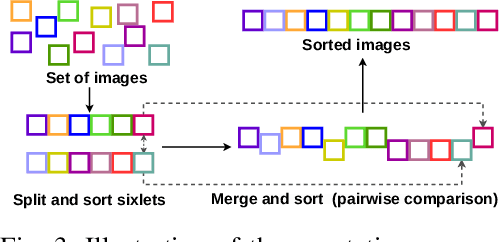

We introduce the notion of semantic image quality for applications where image quality relies on semantic requirements. Working in fetal ultrasound, where ranking is challenging and annotations are noisy, we design a robust coarse-to-fine model that ranks images based on their semantic image quality and endow our predicted rankings with an uncertainty estimate. To annotate rankings on training data, we design an efficient ranking annotation scheme based on the merge sort algorithm. Finally, we compare our ranking algorithm to a number of state-of-the-art ranking algorithms on a challenging fetal ultrasound quality assessment task, showing the superior performance of our method on the majority of rank correlation metrics.
Assessing the Interpretability of Programmatic Policies with Large Language Models
Nov 12, 2023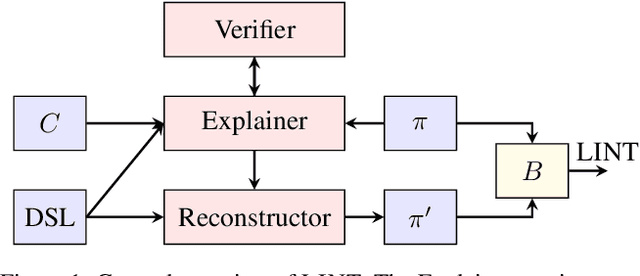


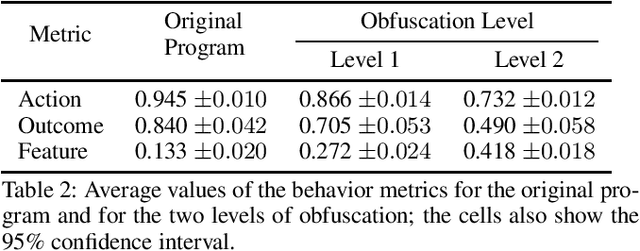
Although the synthesis of programs encoding policies often carries the promise of interpretability, systematic evaluations to assess the interpretability of these policies were never performed, likely because of the complexity of such an evaluation. In this paper, we introduce a novel metric that uses large-language models (LLM) to assess the interpretability of programmatic policies. For our metric, an LLM is given both a program and a description of its associated programming language. The LLM then formulates a natural language explanation of the program. This explanation is subsequently fed into a second LLM, which tries to reconstruct the program from the natural language explanation. Our metric measures the behavioral similarity between the reconstructed program and the original. We validate our approach using obfuscated programs that are used to solve classic programming problems. We also assess our metric with programmatic policies synthesized for playing a real-time strategy game, comparing the interpretability scores of programmatic policies synthesized by an existing system to lightly obfuscated versions of the same programs. Our LLM-based interpretability score consistently ranks less interpretable programs lower and more interpretable ones higher. These findings suggest that our metric could serve as a reliable and inexpensive tool for evaluating the interpretability of programmatic policies.
An Automatic Guidance and Quality Assessment System for Doppler Imaging of Umbilical Artery
Apr 11, 2023In fetal ultrasound screening, Doppler images on the umbilical artery (UA) are important for monitoring blood supply through the umbilical cord. However, to capture UA Doppler images, a number of steps need to be done correctly: placing the gate at a proper location in the ultrasound image to obtain blood flow waveforms, and judging the Doppler waveform quality. Both of these rely on the operator's experience. The shortage of experienced sonographers thus creates a demand for machine assistance. We propose an automatic system to fill this gap. Using a modified Faster R-CNN we obtain an algorithm that suggests Doppler flow gate locations. We subsequently assess the Doppler waveform quality. We validate the proposed system on 657 scans from a national ultrasound screening database. The experimental results demonstrate that our system is useful in guiding operators for UA Doppler image capture and quality assessment.
Removing confounding information from fetal ultrasound images
Mar 24, 2023


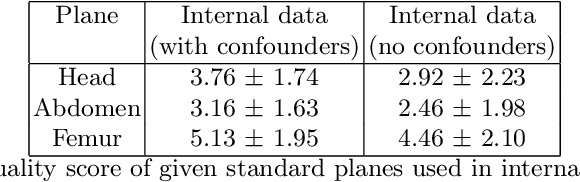
Confounding information in the form of text or markings embedded in medical images can severely affect the training of diagnostic deep learning algorithms. However, data collected for clinical purposes often have such markings embedded in them. In dermatology, known examples include drawings or rulers that are overrepresented in images of malignant lesions. In this paper, we encounter text and calipers placed on the images found in national databases containing fetal screening ultrasound scans, which correlate with standard planes to be predicted. In order to utilize the vast amounts of data available in these databases, we develop and validate a series of methods for minimizing the confounding effects of embedded text and calipers on deep learning algorithms designed for ultrasound, using standard plane classification as a test case.
I saw, I conceived, I concluded: Progressive Concepts as Bottlenecks
Nov 19, 2022



Concept bottleneck models (CBMs) include a bottleneck of human-interpretable concepts providing explainability and intervention during inference by correcting the predicted, intermediate concepts. This makes CBMs attractive for high-stakes decision-making. In this paper, we take the quality assessment of fetal ultrasound scans as a real-life use case for CBM decision support in healthcare. For this case, simple binary concepts are not sufficiently reliable, as they are mapped directly from images of highly variable quality, for which variable model calibration might lead to unstable binarized concepts. Moreover, scalar concepts do not provide the intuitive spatial feedback requested by users. To address this, we design a hierarchical CBM imitating the sequential expert decision-making process of "seeing", "conceiving" and "concluding". Our model first passes through a layer of visual, segmentation-based concepts, and next a second layer of property concepts directly associated with the decision-making task. We note that experts can intervene on both the visual and property concepts during inference. Additionally, we increase the bottleneck capacity by considering task-relevant concept interaction. Our application of ultrasound scan quality assessment is challenging, as it relies on balancing the (often poor) image quality against an assessment of the visibility and geometric properties of standardized image content. Our validation shows that -- in contrast with previous CBM models -- our CBM models actually outperform equivalent concept-free models in terms of predictive performance. Moreover, we illustrate how interventions can further improve our performance over the state-of-the-art.
DTU-Net: Learning Topological Similarity for Curvilinear Structure Segmentation
May 23, 2022
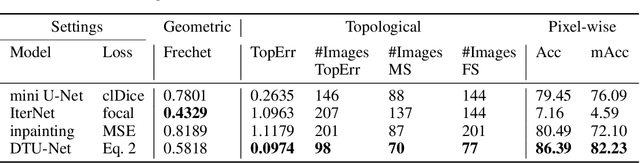
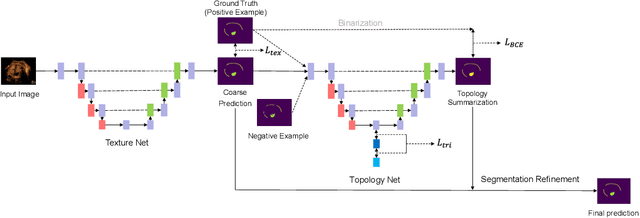
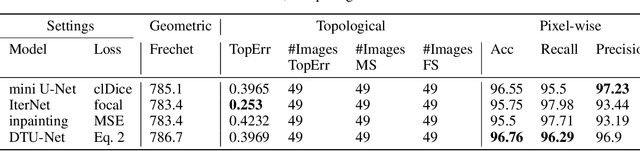
Curvilinear structure segmentation plays an important role in many applications. The standard formulation of segmentation as pixel-wise classification often fails to capture these structures due to the small size and low contrast. Some works introduce prior topological information to address this problem with the cost of expensive computations and the need for extra labels. Moreover, prior work primarily focuses on avoiding false splits by encouraging the connection of small gaps. Less attention has been given to avoiding missed splits, namely the incorrect inference of structures that are not visible in the image. In this paper, we present DTU-Net, a dual-decoder and topology-aware deep neural network consisting of two sequential light-weight U-Nets, namely a texture net, and a topology net. The texture net makes a coarse prediction using image texture information. The topology net learns topological information from the coarse prediction by employing a triplet loss trained to recognize false and missed splits, and provides a topology-aware separation of the foreground and background. The separation is further utilized to correct the coarse prediction. We conducted experiments on a challenging multi-class ultrasound scan segmentation dataset and an open dataset for road extraction. Results show that our model achieves state-of-the-art results in both segmentation accuracy and continuity. Compared to existing methods, our model corrects both false positive and false negative examples more effectively with no need for prior knowledge.