 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Space Correlation Analysis: Quantifying Feature Utilization in Deep Learning Models
Dec 15, 2025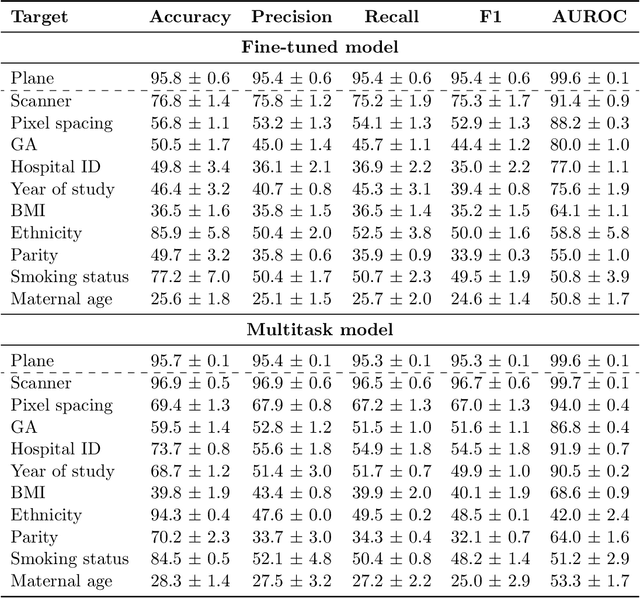
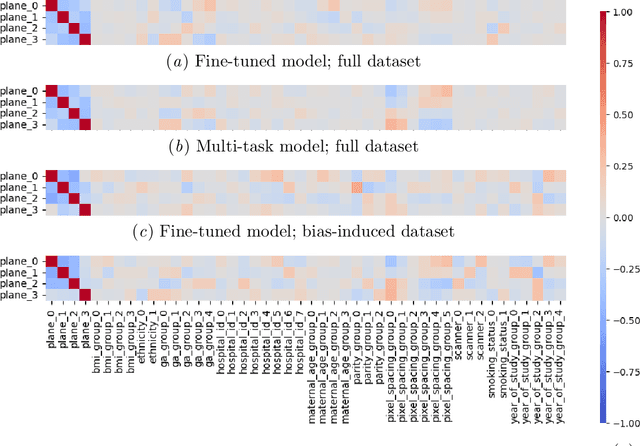
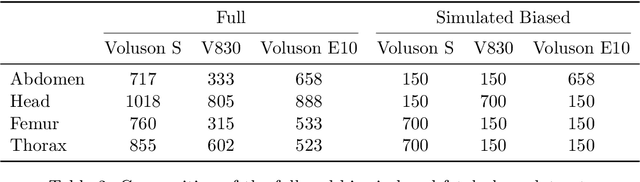

Deep learning models in medical imaging are susceptible to shortcut learning, relying on confounding metadata (e.g., scanner model) that is often encoded in image embeddings. The crucial question is whether the model actively utilizes this encoded information for its final prediction. We introduce Weight Space Correlation Analysis, an interpretable methodology that quantifies feature utilization by measuring the alignment between the classification heads of a primary clinical task and auxiliary metadata tasks. We first validate our method by successfully detecting artificially induced shortcut learning. We then apply it to probe the feature utilization of an SA-SonoNet model trained for Spontaneous Preterm Birth (sPTB) prediction. Our analysis confirmed that while the embeddings contain substantial metadata, the sPTB classifier's weight vectors were highly correlated with clinically relevant factors (e.g., birth weight) but decoupled from clinically irrelevant acquisition factors (e.g. scanner). Our methodology provides a tool to verify model trustworthiness, demonstrating that, in the absence of induced bias, the clinical model selectively utilizes features related to the genuine clinical signal.
Determining Fetal Orientations From Blind Sweep Ultrasound Video
Apr 09, 2025Cognitive demands of fetal ultrasound examinations pose unique challenges among clinicians. With the goal of providing an assistive tool, we developed an automated pipeline for predicting fetal orientation from ultrasound videos acquired following a simple blind sweep protocol. Leveraging on a pre-trained head detection and segmentation model, this is achieved by first determining the fetal presentation (cephalic or breech) with a template matching approach, followed by the fetal lie (facing left or right) by analyzing the spatial distribution of segmented brain anatomies. Evaluation on a dataset of third-trimester ultrasound scans demonstrated the promising accuracy of our pipeline. This work distinguishes itself by introducing automated fetal lie prediction and by proposing an assistive paradigm that augments sonographer expertise rather than replacing it. Future research will focus on enhancing acquisition efficiency, and exploring real-time clinical integration to improve workflow and support for obstetric clinicians.
Unsupervised Detection of Fetal Brain Anomalies using Denoising Diffusion Models
Aug 07, 2024Congenital malformations of the brain are among the most common fetal abnormalities that impact fetal development. Previous anomaly detection methods on ultrasound images are based on supervised learning, rely on manual annotations, and risk missing underrepresented categories. In this work, we frame fetal brain anomaly detection as an unsupervised task using diffusion models. To this end, we employ an inpainting-based Noise Agnostic Anomaly Detection approach that identifies the abnormality using diffusion-reconstructed fetal brain images from multiple noise levels. Our approach only requires normal fetal brain ultrasound images for training, addressing the limited availability of abnormal data. Our experiments on a real-world clinical dataset show the potential of using unsupervised methods for fetal brain anomaly detection. Additionally, we comprehensively evaluate how different noise types affect diffusion models in the fetal anomaly detection domain.
Deployment of Deep Learning Model in Real World Clinical Setting: A Case Study in Obstetric Ultrasound
Mar 22, 2024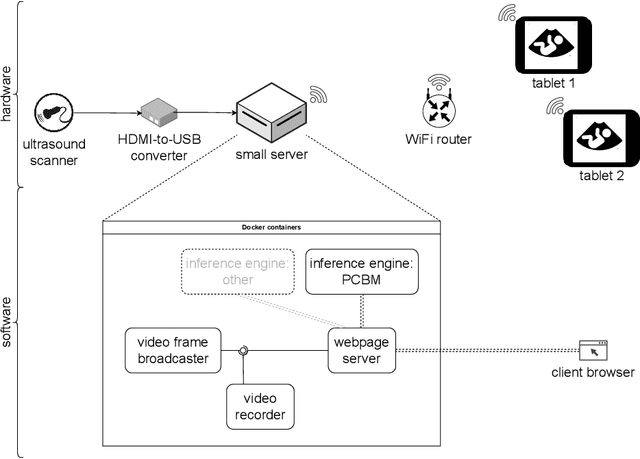

Despite the rapid development of AI models in medical image analysis, their validation in real-world clinical settings remains limited. To address this, we introduce a generic framework designed for deploying image-based AI models in such settings. Using this framework, we deployed a trained model for fetal ultrasound standard plane detection, and evaluated it in real-time sessions with both novice and expert users. Feedback from these sessions revealed that while the model offers potential benefits to medical practitioners, the need for navigational guidance was identified as a key area for improvement. These findings underscore the importance of early deployment of AI models in real-world settings, leading to insights that can guide the refinement of the model and system based on actual user feedback.
Learning semantic image quality for fetal ultrasound from noisy ranking annotation
Feb 13, 2024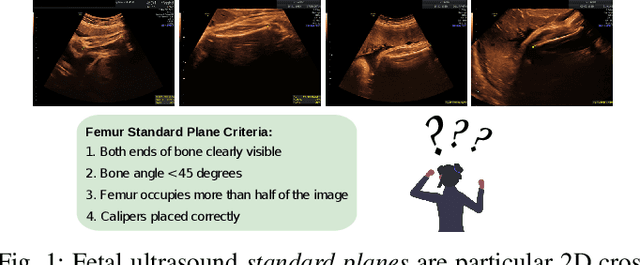
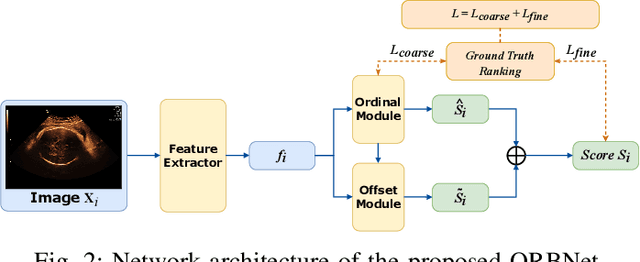
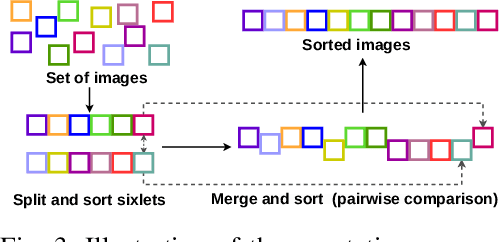

We introduce the notion of semantic image quality for applications where image quality relies on semantic requirements. Working in fetal ultrasound, where ranking is challenging and annotations are noisy, we design a robust coarse-to-fine model that ranks images based on their semantic image quality and endow our predicted rankings with an uncertainty estimate. To annotate rankings on training data, we design an efficient ranking annotation scheme based on the merge sort algorithm. Finally, we compare our ranking algorithm to a number of state-of-the-art ranking algorithms on a challenging fetal ultrasound quality assessment task, showing the superior performance of our method on the majority of rank correlation metrics.
An Automatic Guidance and Quality Assessment System for Doppler Imaging of Umbilical Artery
Apr 11, 2023In fetal ultrasound screening, Doppler images on the umbilical artery (UA) are important for monitoring blood supply through the umbilical cord. However, to capture UA Doppler images, a number of steps need to be done correctly: placing the gate at a proper location in the ultrasound image to obtain blood flow waveforms, and judging the Doppler waveform quality. Both of these rely on the operator's experience. The shortage of experienced sonographers thus creates a demand for machine assistance. We propose an automatic system to fill this gap. Using a modified Faster R-CNN we obtain an algorithm that suggests Doppler flow gate locations. We subsequently assess the Doppler waveform quality. We validate the proposed system on 657 scans from a national ultrasound screening database. The experimental results demonstrate that our system is useful in guiding operators for UA Doppler image capture and quality assessment.
I saw, I conceived, I concluded: Progressive Concepts as Bottlenecks
Nov 19, 2022



Concept bottleneck models (CBMs) include a bottleneck of human-interpretable concepts providing explainability and intervention during inference by correcting the predicted, intermediate concepts. This makes CBMs attractive for high-stakes decision-making. In this paper, we take the quality assessment of fetal ultrasound scans as a real-life use case for CBM decision support in healthcare. For this case, simple binary concepts are not sufficiently reliable, as they are mapped directly from images of highly variable quality, for which variable model calibration might lead to unstable binarized concepts. Moreover, scalar concepts do not provide the intuitive spatial feedback requested by users. To address this, we design a hierarchical CBM imitating the sequential expert decision-making process of "seeing", "conceiving" and "concluding". Our model first passes through a layer of visual, segmentation-based concepts, and next a second layer of property concepts directly associated with the decision-making task. We note that experts can intervene on both the visual and property concepts during inference. Additionally, we increase the bottleneck capacity by considering task-relevant concept interaction. Our application of ultrasound scan quality assessment is challenging, as it relies on balancing the (often poor) image quality against an assessment of the visibility and geometric properties of standardized image content. Our validation shows that -- in contrast with previous CBM models -- our CBM models actually outperform equivalent concept-free models in terms of predictive performance. Moreover, we illustrate how interventions can further improve our performance over the state-of-the-art.
Generalisability of deep learning models in low-resource imaging settings: A fetal ultrasound study in 5 African countries
Sep 20, 2022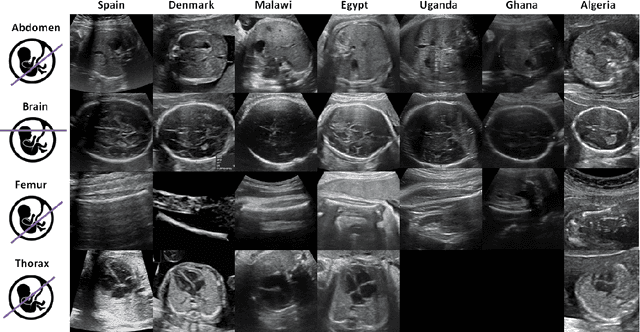
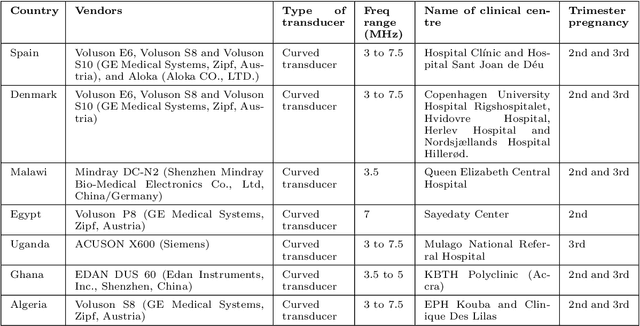
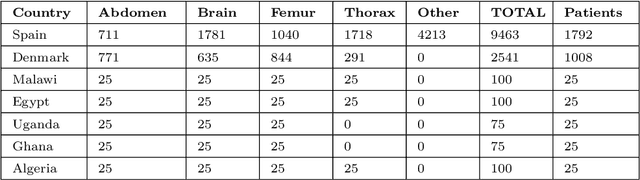
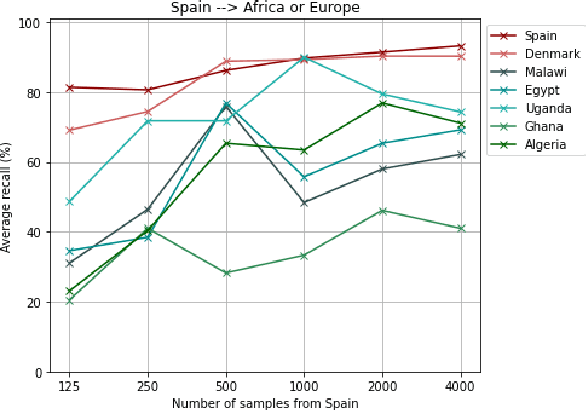
Most artificial intelligence (AI) research have concentrated in high-income countries, where imaging data, IT infrastructures and clinical expertise are plentiful. However, slower progress has been made in limited-resource environments where medical imaging is needed. For example, in Sub-Saharan Africa the rate of perinatal mortality is very high due to limited access to antenatal screening. In these countries, AI models could be implemented to help clinicians acquire fetal ultrasound planes for diagnosis of fetal abnormalities. So far, deep learning models have been proposed to identify standard fetal planes, but there is no evidence of their ability to generalise in centres with limited access to high-end ultrasound equipment and data. This work investigates different strategies to reduce the domain-shift effect for a fetal plane classification model trained on a high-resource clinical centre and transferred to a new low-resource centre. To that end, a classifier trained with 1,792 patients from Spain is first evaluated on a new centre in Denmark in optimal conditions with 1,008 patients and is later optimised to reach the same performance in five African centres (Egypt, Algeria, Uganda, Ghana and Malawi) with 25 patients each. The results show that a transfer learning approach can be a solution to integrate small-size African samples with existing large-scale databases in developed countries. In particular, the model can be re-aligned and optimised to boost the performance on African populations by increasing the recall to $0.92 \pm 0.04$ and at the same time maintaining a high precision across centres. This framework shows promise for building new AI models generalisable across clinical centres with limited data acquired in challenging and heterogeneous conditions and calls for further research to develop new solutions for usability of AI in countries with less resources.
DTU-Net: Learning Topological Similarity for Curvilinear Structure Segmentation
May 23, 2022
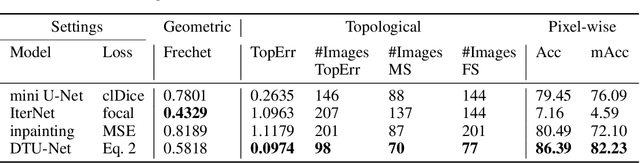
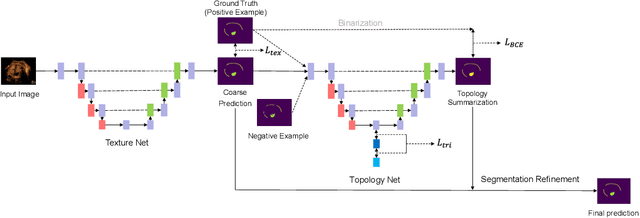
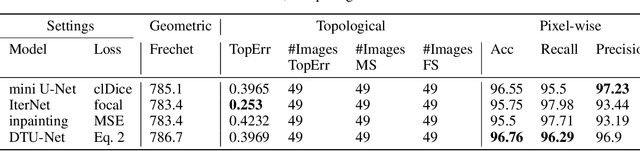
Curvilinear structure segmentation plays an important role in many applications. The standard formulation of segmentation as pixel-wise classification often fails to capture these structures due to the small size and low contrast. Some works introduce prior topological information to address this problem with the cost of expensive computations and the need for extra labels. Moreover, prior work primarily focuses on avoiding false splits by encouraging the connection of small gaps. Less attention has been given to avoiding missed splits, namely the incorrect inference of structures that are not visible in the image. In this paper, we present DTU-Net, a dual-decoder and topology-aware deep neural network consisting of two sequential light-weight U-Nets, namely a texture net, and a topology net. The texture net makes a coarse prediction using image texture information. The topology net learns topological information from the coarse prediction by employing a triplet loss trained to recognize false and missed splits, and provides a topology-aware separation of the foreground and background. The separation is further utilized to correct the coarse prediction. We conducted experiments on a challenging multi-class ultrasound scan segmentation dataset and an open dataset for road extraction. Results show that our model achieves state-of-the-art results in both segmentation accuracy and continuity. Compared to existing methods, our model corrects both false positive and false negative examples more effectively with no need for prior knowledge.