 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatronus: Bringing Transparency to Diffusion Models with Prototypes
Mar 28, 2025Diffusion-based generative models, such as Denoising Diffusion Probabilistic Models (DDPMs), have achieved remarkable success in image generation, but their step-by-step denoising process remains opaque, leaving critical aspects of the generation mechanism unexplained. To address this, we introduce \emph{Patronus}, an interpretable diffusion model inspired by ProtoPNet. Patronus integrates a prototypical network into DDPMs, enabling the extraction of prototypes and conditioning of the generation process on their prototype activation vector. This design enhances interpretability by showing the learned prototypes and how they influence the generation process. Additionally, the model supports downstream tasks like image manipulation, enabling more transparent and controlled modifications. Moreover, Patronus could reveal shortcut learning in the generation process by detecting unwanted correlations between learned prototypes. Notably, Patronus operates entirely without any annotations or text prompts. This work opens new avenues for understanding and controlling diffusion models through prototype-based interpretability. Our code is available at \href{https://github.com/nina-weng/patronus}{https://github.com/nina-weng/patronus}.
Diffusion-based Iterative Counterfactual Explanations for Fetal Ultrasound Image Quality Assessment
Mar 13, 2024



Obstetric ultrasound image quality is crucial for accurate diagnosis and monitoring of fetal health. However, producing high-quality standard planes is difficult, influenced by the sonographer's expertise and factors like the maternal BMI or the fetus dynamics. In this work, we propose using diffusion-based counterfactual explainable AI to generate realistic high-quality standard planes from low-quality non-standard ones. Through quantitative and qualitative evaluation, we demonstrate the effectiveness of our method in producing plausible counterfactuals of increased quality. This shows future promise both for enhancing training of clinicians by providing visual feedback, as well as for improving image quality and, consequently, downstream diagnosis and monitoring.
Fast Diffusion-Based Counterfactuals for Shortcut Removal and Generation
Dec 21, 2023Shortcut learning is when a model -- e.g. a cardiac disease classifier -- exploits correlations between the target label and a spurious shortcut feature, e.g. a pacemaker, to predict the target label based on the shortcut rather than real discriminative features. This is common in medical imaging, where treatment and clinical annotations correlate with disease labels, making them easy shortcuts to predict disease. We propose a novel detection and quantification of the impact of potential shortcut features via a fast diffusion-based counterfactual image generation that can synthetically remove or add shortcuts. Via a novel inpainting-based modification we spatially limit the changes made with no extra inference step, encouraging the removal of spatially constrained shortcut features while ensuring that the shortcut-free counterfactuals preserve their remaining image features to a high degree. Using these, we assess how shortcut features influence model predictions. This is enabled by our second contribution: An efficient diffusion-based counterfactual explanation method with significant inference speed-up at comparable image quality as state-of-the-art. We confirm this on two large chest X-ray datasets, a skin lesion dataset, and CelebA.
Are Sex-based Physiological Differences the Cause of Gender Bias for Chest X-ray Diagnosis?
Aug 09, 2023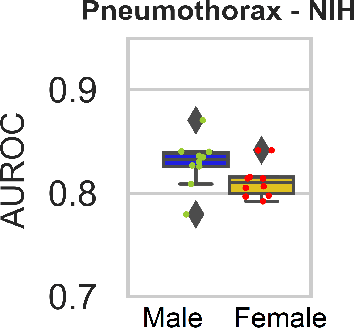
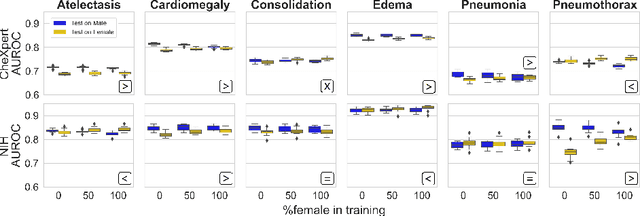
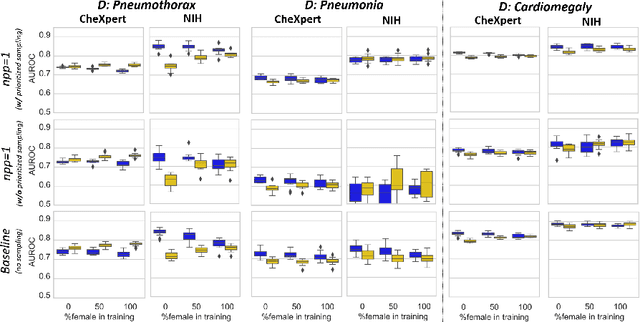
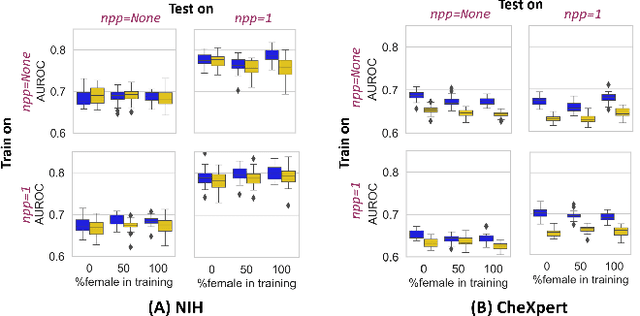
While many studies have assessed the fairness of AI algorithms in the medical field, the causes of differences in prediction performance are often unknown. This lack of knowledge about the causes of bias hampers the efficacy of bias mitigation, as evidenced by the fact that simple dataset balancing still often performs best in reducing performance gaps but is unable to resolve all performance differences. In this work, we investigate the causes of gender bias in machine learning-based chest X-ray diagnosis. In particular, we explore the hypothesis that breast tissue leads to underexposure of the lungs and causes lower model performance. Methodologically, we propose a new sampling method which addresses the highly skewed distribution of recordings per patient in two widely used public datasets, while at the same time reducing the impact of label errors. Our comprehensive analysis of gender differences across diseases, datasets, and gender representations in the training set shows that dataset imbalance is not the sole cause of performance differences. Moreover, relative group performance differs strongly between datasets, indicating important dataset-specific factors influencing male/female group performance. Finally, we investigate the effect of breast tissue more specifically, by cropping out the breasts from recordings, finding that this does not resolve the observed performance gaps. In conclusion, our results indicate that dataset-specific factors, not fundamental physiological differences, are the main drivers of male--female performance gaps in chest X-ray analyses on widely used NIH and CheXpert Dataset.
AIM 2020 Challenge on Image Extreme Inpainting
Oct 02, 2020
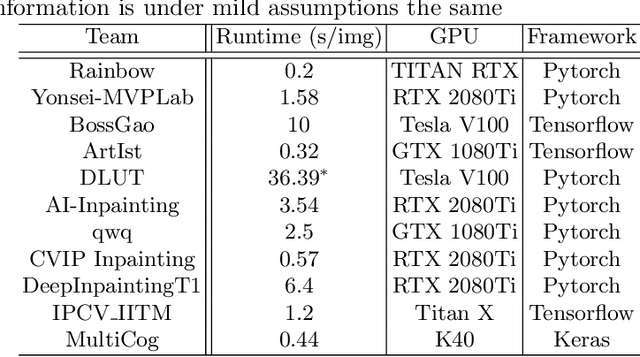
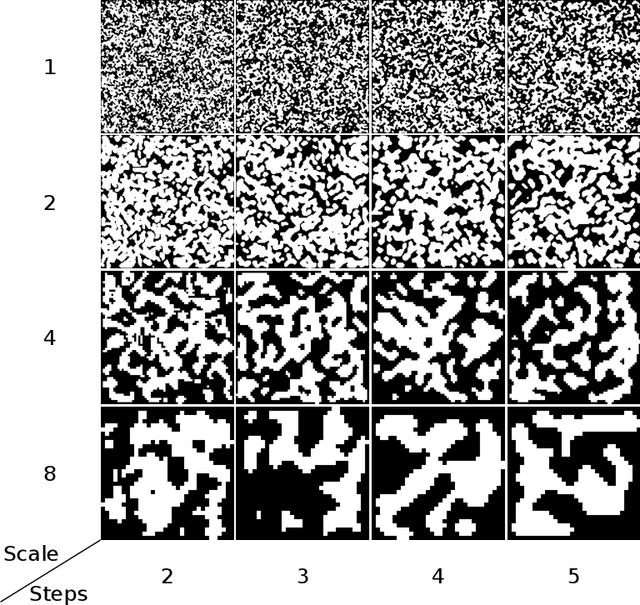
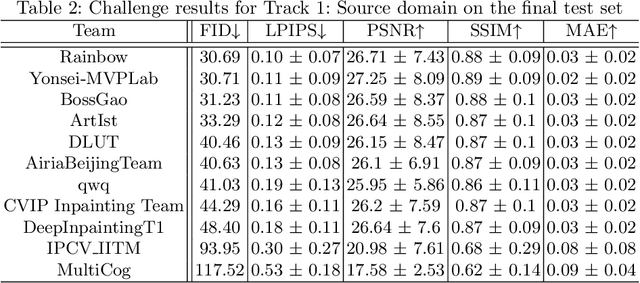
This paper reviews the AIM 2020 challenge on extreme image inpainting. This report focuses on proposed solutions and results for two different tracks on extreme image inpainting: classical image inpainting and semantically guided image inpainting. The goal of track 1 is to inpaint considerably large part of the image using no supervision but the context. Similarly, the goal of track 2 is to inpaint the image by having access to the entire semantic segmentation map of the image to inpaint. The challenge had 88 and 74 participants, respectively. 11 and 6 teams competed in the final phase of the challenge, respectively. This report gauges current solutions and set a benchmark for future extreme image inpainting methods.
GramGAN: Deep 3D Texture Synthesis From 2D Exemplars
Jun 30, 2020

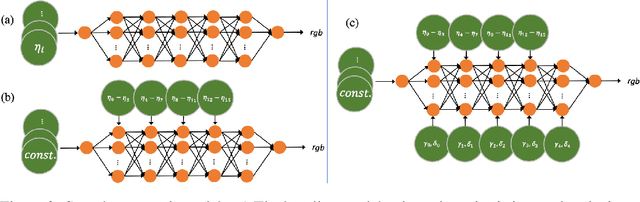

We present a novel texture synthesis framework, enabling the generation of infinite, high-quality 3D textures given a 2D exemplar image. Inspired by recent advances in natural texture synthesis, we train deep neural models to generate textures by non-linearly combining learned noise frequencies. To achieve a highly realistic output conditioned on an exemplar patch, we propose a novel loss function that combines ideas from both style transfer and generative adversarial networks. In particular, we train the synthesis network to match the Gram matrices of deep features from a discriminator network. In addition, we propose two architectural concepts and an extrapolation strategy that significantly improve generalization performance. In particular, we inject both model input and condition into hidden network layers by learning to scale and bias hidden activations. Quantitative and qualitative evaluations on a diverse set of exemplars motivate our design decisions and show that our system performs superior to previous state of the art. Finally, we conduct a user study that confirms the benefits of our framework.
Image Restoration using Plug-and-Play CNN MAP Denoisers
Dec 20, 2019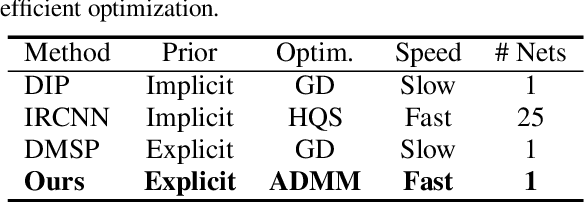
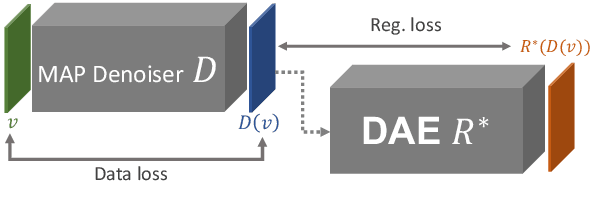

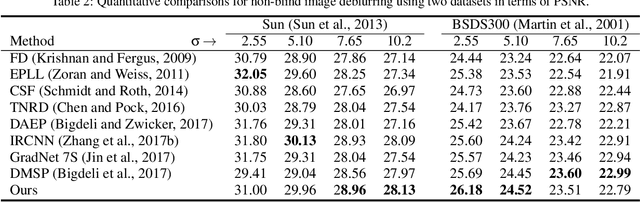
Plug-and-play denoisers can be used to perform generic image restoration tasks independent of the degradation type. These methods build on the fact that the Maximum a Posteriori (MAP) optimization can be solved using smaller sub-problems, including a MAP denoising optimization. We present the first end-to-end approach to MAP estimation for image denoising using deep neural networks. We show that our method is guaranteed to minimize the MAP denoising objective, which is then used in an optimization algorithm for generic image restoration. We provide theoretical analysis of our approach and show the quantitative performance of our method in several experiments. Our experimental results show that the proposed method can achieve 70x faster performance compared to the state-of-the-art, while maintaining the theoretical perspective of MAP.