 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Preprocessing Methods on Racial Encoding and Model Robustness in CXR Diagnosis
Mar 05, 2026Deep learning models can identify racial identity with high accuracy from chest X-ray (CXR) recordings. Thus, there is widespread concern about the potential for racial shortcut learning, where a model inadvertently learns to systematically bias its diagnostic predictions as a function of racial identity. Such racial biases threaten healthcare equity and model reliability, as models may systematically misdiagnose certain demographic groups. Since racial shortcuts are diffuse - non-localized and distributed throughout the whole CXR recording - image preprocessing methods may influence racial shortcut learning, yet the potential of such methods for reducing biases remains underexplored. Here, we investigate the effects of image preprocessing methods including lung masking, lung cropping, and Contrast Limited Adaptive Histogram Equalization (CLAHE). These approaches aim to suppress spurious cues encoding racial information while preserving diagnostic accuracy. Our experiments reveal that simple bounding box-based lung cropping can be an effective strategy for reducing racial shortcut learning while maintaining diagnostic model performance, bypassing frequently postulated fairness-accuracy trade-offs.
meval: A Statistical Toolbox for Fine-Grained Model Performance Analysis
Dec 19, 2025Analyzing machine learning model performance stratified by patient and recording properties is becoming the accepted norm and often yields crucial insights about important model failure modes. Performing such analyses in a statistically rigorous manner is non-trivial, however. Appropriate performance metrics must be selected that allow for valid comparisons between groups of different sample sizes and base rates; metric uncertainty must be determined and multiple comparisons be corrected for, in order to assess whether any observed differences may be purely due to chance; and in the case of intersectional analyses, mechanisms must be implemented to find the most `interesting' subgroups within combinatorially many subgroup combinations. We here present a statistical toolbox that addresses these challenges and enables practitioners to easily yet rigorously assess their models for potential subgroup performance disparities. While broadly applicable, the toolbox is specifically designed for medical imaging applications. The analyses provided by the toolbox are illustrated in two case studies, one in skin lesion malignancy classification on the ISIC2020 dataset and one in chest X-ray-based disease classification on the MIMIC-CXR dataset.
Robustness and sex differences in skin cancer detection: logistic regression vs CNNs
Apr 15, 2025
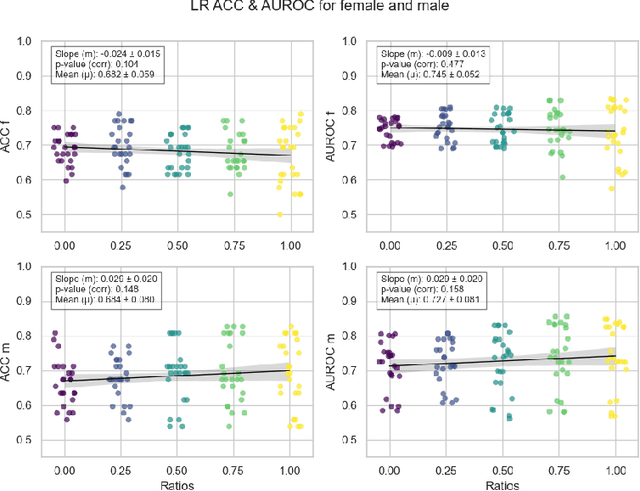
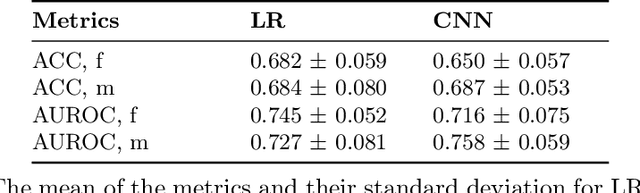
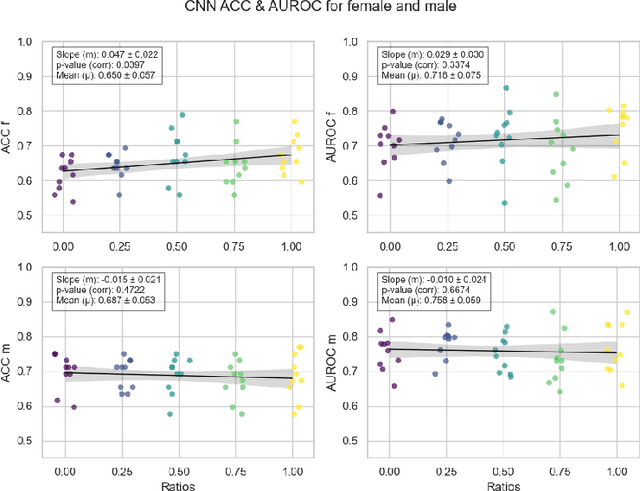
Deep learning has been reported to achieve high performances in the detection of skin cancer, yet many challenges regarding the reproducibility of results and biases remain. This study is a replication (different data, same analysis) of a study on Alzheimer's disease [28] which studied robustness of logistic regression (LR) and convolutional neural networks (CNN) across patient sexes. We explore sex bias in skin cancer detection, using the PAD-UFES-20 dataset with LR trained on handcrafted features reflecting dermatological guidelines (ABCDE and the 7-point checklist), and a pre-trained ResNet-50 model. We evaluate these models in alignment with [28]: across multiple training datasets with varied sex composition to determine their robustness. Our results show that both the LR and the CNN were robust to the sex distributions, but the results also revealed that the CNN had a significantly higher accuracy (ACC) and area under the receiver operating characteristics (AUROC) for male patients than for female patients. We hope these findings to contribute to the growing field of investigating potential bias in popular medical machine learning methods. The data and relevant scripts to reproduce our results can be found in our Github.
Slicing Through Bias: Explaining Performance Gaps in Medical Image Analysis using Slice Discovery Methods
Jun 17, 2024Machine learning models have achieved high overall accuracy in medical image analysis. However, performance disparities on specific patient groups pose challenges to their clinical utility, safety, and fairness. This can affect known patient groups - such as those based on sex, age, or disease subtype - as well as previously unknown and unlabeled groups. Furthermore, the root cause of such observed performance disparities is often challenging to uncover, hindering mitigation efforts. In this paper, to address these issues, we leverage Slice Discovery Methods (SDMs) to identify interpretable underperforming subsets of data and formulate hypotheses regarding the cause of observed performance disparities. We introduce a novel SDM and apply it in a case study on the classification of pneumothorax and atelectasis from chest x-rays. Our study demonstrates the effectiveness of SDMs in hypothesis formulation and yields an explanation of previously observed but unexplained performance disparities between male and female patients in widely used chest X-ray datasets and models. Our findings indicate shortcut learning in both classification tasks, through the presence of chest drains and ECG wires, respectively. Sex-based differences in the prevalence of these shortcut features appear to cause the observed classification performance gap, representing a previously underappreciated interaction between shortcut learning and model fairness analyses.
Fast Diffusion-Based Counterfactuals for Shortcut Removal and Generation
Dec 21, 2023Shortcut learning is when a model -- e.g. a cardiac disease classifier -- exploits correlations between the target label and a spurious shortcut feature, e.g. a pacemaker, to predict the target label based on the shortcut rather than real discriminative features. This is common in medical imaging, where treatment and clinical annotations correlate with disease labels, making them easy shortcuts to predict disease. We propose a novel detection and quantification of the impact of potential shortcut features via a fast diffusion-based counterfactual image generation that can synthetically remove or add shortcuts. Via a novel inpainting-based modification we spatially limit the changes made with no extra inference step, encouraging the removal of spatially constrained shortcut features while ensuring that the shortcut-free counterfactuals preserve their remaining image features to a high degree. Using these, we assess how shortcut features influence model predictions. This is enabled by our second contribution: An efficient diffusion-based counterfactual explanation method with significant inference speed-up at comparable image quality as state-of-the-art. We confirm this on two large chest X-ray datasets, a skin lesion dataset, and CelebA.
Are Sex-based Physiological Differences the Cause of Gender Bias for Chest X-ray Diagnosis?
Aug 09, 2023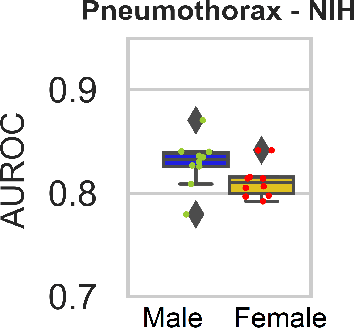
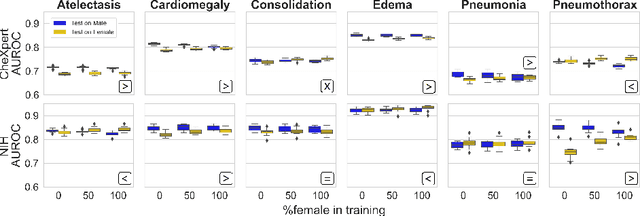
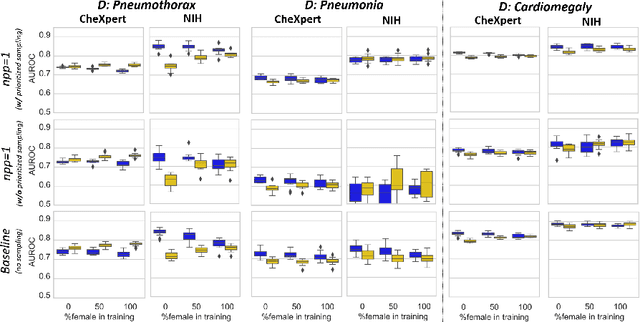
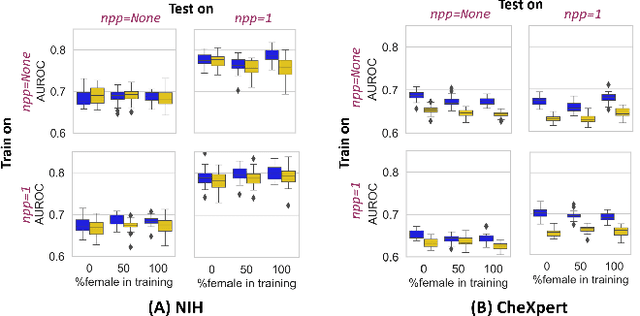
While many studies have assessed the fairness of AI algorithms in the medical field, the causes of differences in prediction performance are often unknown. This lack of knowledge about the causes of bias hampers the efficacy of bias mitigation, as evidenced by the fact that simple dataset balancing still often performs best in reducing performance gaps but is unable to resolve all performance differences. In this work, we investigate the causes of gender bias in machine learning-based chest X-ray diagnosis. In particular, we explore the hypothesis that breast tissue leads to underexposure of the lungs and causes lower model performance. Methodologically, we propose a new sampling method which addresses the highly skewed distribution of recordings per patient in two widely used public datasets, while at the same time reducing the impact of label errors. Our comprehensive analysis of gender differences across diseases, datasets, and gender representations in the training set shows that dataset imbalance is not the sole cause of performance differences. Moreover, relative group performance differs strongly between datasets, indicating important dataset-specific factors influencing male/female group performance. Finally, we investigate the effect of breast tissue more specifically, by cropping out the breasts from recordings, finding that this does not resolve the observed performance gaps. In conclusion, our results indicate that dataset-specific factors, not fundamental physiological differences, are the main drivers of male--female performance gaps in chest X-ray analyses on widely used NIH and CheXpert Dataset.
Are demographically invariant models and representations in medical imaging fair?
May 02, 2023

Medical imaging models have been shown to encode information about patient demographics (age, race, sex) in their latent representation, raising concerns about their potential for discrimination. Here, we ask whether it is feasible and desirable to train models that do not encode demographic attributes. We consider different types of invariance with respect to demographic attributes - marginal, class-conditional, and counterfactual model invariance - and lay out their equivalence to standard notions of algorithmic fairness. Drawing on existing theory, we find that marginal and class-conditional invariance can be considered overly restrictive approaches for achieving certain fairness notions, resulting in significant predictive performance losses. Concerning counterfactual model invariance, we note that defining medical image counterfactuals with respect to demographic attributes is fraught with complexities. Finally, we posit that demographic encoding may even be considered advantageous if it enables learning a task-specific encoding of demographic features that does not rely on human-constructed categories such as 'race' and 'gender'. We conclude that medical imaging models may need to encode demographic attributes, lending further urgency to calls for comprehensive model fairness assessments in terms of predictive performance.
That Label's Got Style: Handling Label Style Bias for Uncertain Image Segmentation
Mar 28, 2023
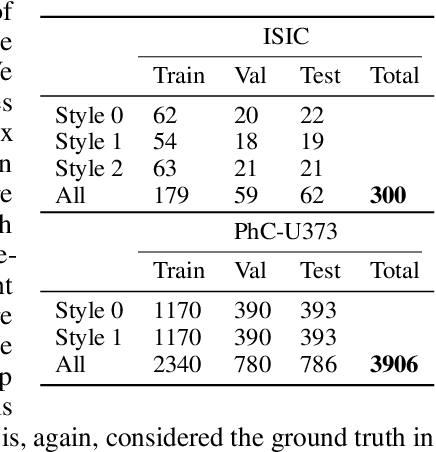

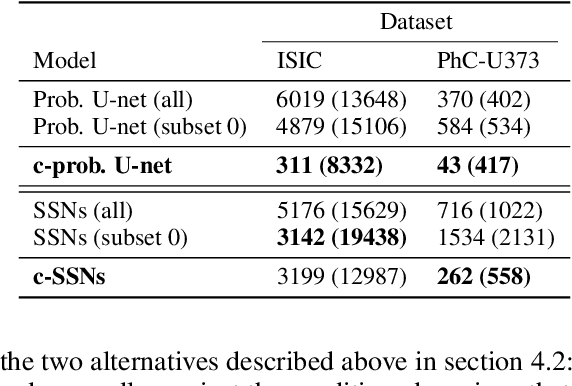
Segmentation uncertainty models predict a distribution over plausible segmentations for a given input, which they learn from the annotator variation in the training set. However, in practice these annotations can differ systematically in the way they are generated, for example through the use of different labeling tools. This results in datasets that contain both data variability and differing label styles. In this paper, we demonstrate that applying state-of-the-art segmentation uncertainty models on such datasets can lead to model bias caused by the different label styles. We present an updated modelling objective conditioning on labeling style for aleatoric uncertainty estimation, and modify two state-of-the-art-architectures for segmentation uncertainty accordingly. We show with extensive experiments that this method reduces label style bias, while improving segmentation performance, increasing the applicability of segmentation uncertainty models in the wild. We curate two datasets, with annotations in different label styles, which we will make publicly available along with our code upon publication.
On the fairness of risk score models
Feb 22, 2023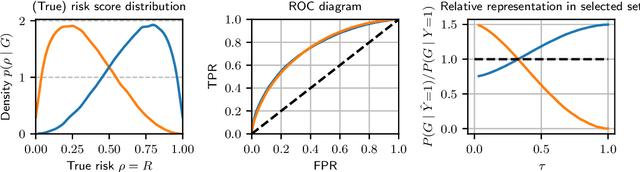
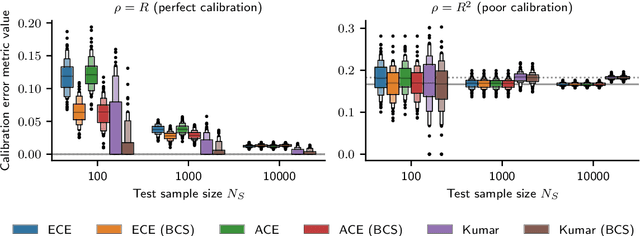
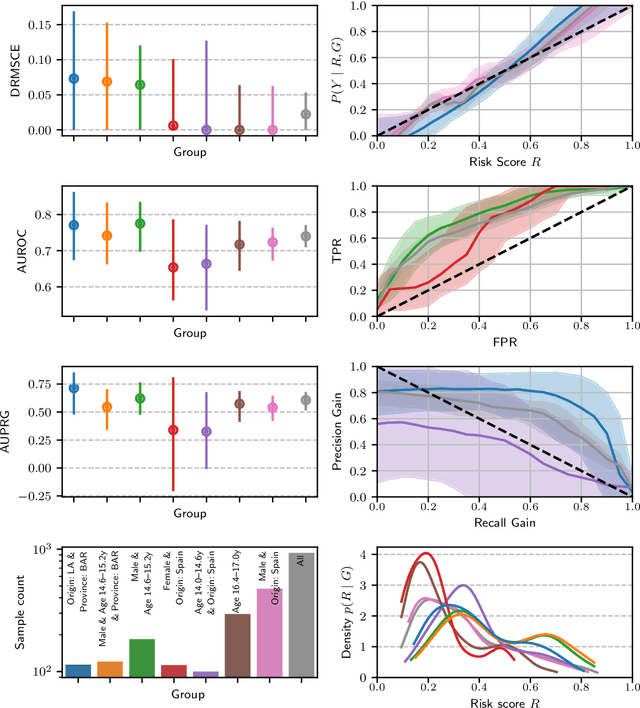
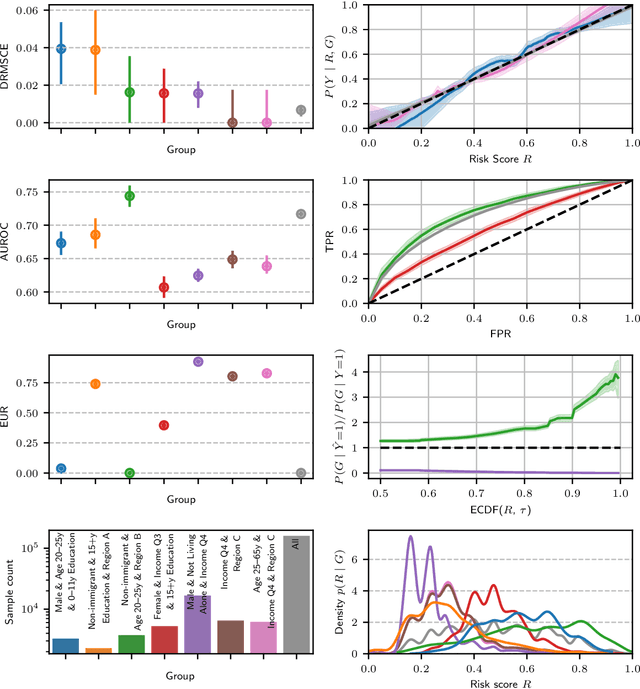
Recent work on algorithmic fairness has largely focused on the fairness of discrete decisions, or classifications. While such decisions are often based on risk score models, the fairness of the risk models themselves has received considerably less attention. Risk models are of interest for a number of reasons, including the fact that they communicate uncertainty about the potential outcomes to users, thus representing a way to enable meaningful human oversight. Here, we address fairness desiderata for risk score models. We identify the provision of similar epistemic value to different groups as a key desideratum for risk score fairness. Further, we address how to assess the fairness of risk score models quantitatively, including a discussion of metric choices and meaningful statistical comparisons between groups. In this context, we also introduce a novel calibration error metric that is less sample size-biased than previously proposed metrics, enabling meaningful comparisons between groups of different sizes. We illustrate our methodology - which is widely applicable in many other settings - in two case studies, one in recidivism risk prediction, and one in risk of major depressive disorder (MDD) prediction.
Feature robustness and sex differences in medical imaging: a case study in MRI-based Alzheimer's disease detection
Apr 12, 2022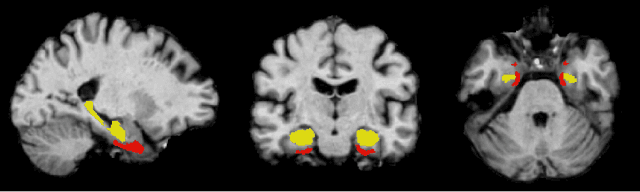

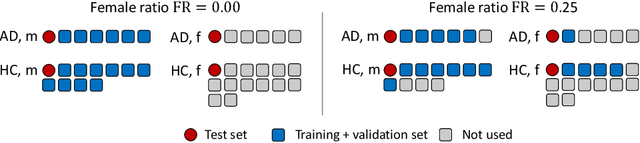
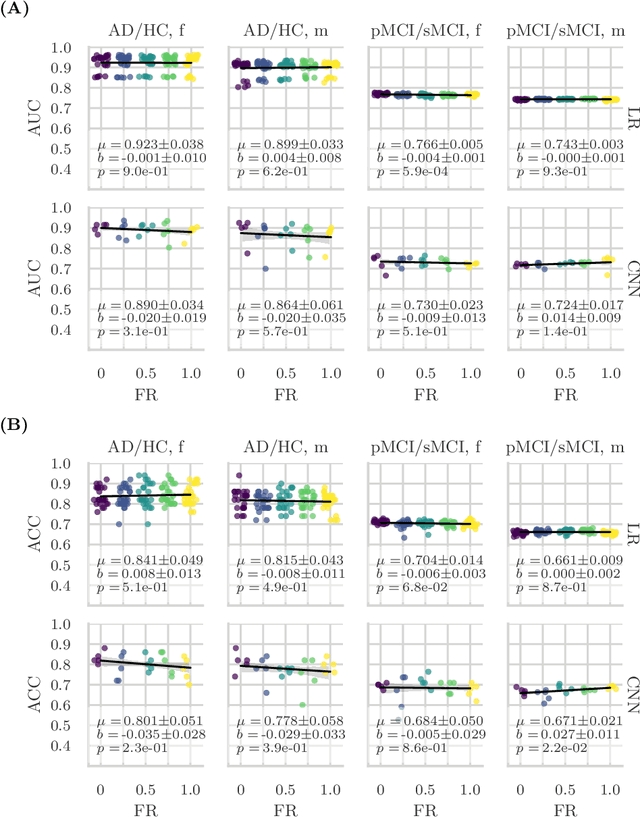
Convolutional neural networks have enabled significant improvements in medical image-based disease classification. It has, however, become increasingly clear that these models are susceptible to performance degradation due to spurious correlations and dataset shifts, which may lead to underperformance on underrepresented patient groups, among other problems. In this paper, we compare two classification schemes on the ADNI MRI dataset: a very simple logistic regression model that uses manually selected volumetric features as inputs, and a convolutional neural network trained on 3D MRI data. We assess the robustness of the trained models in the face of varying dataset splits, training set sex composition, and stage of disease. In contrast to earlier work on diagnosing lung diseases based on chest x-ray data, we do not find a strong dependence of model performance for male and female test subjects on the sex composition of the training dataset. Moreover, in our analysis, the low-dimensional model with manually selected features outperforms the 3D CNN, thus emphasizing the need for automatic robust feature extraction methods and the value of manual feature specification (based on prior knowledge) for robustness.