 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Robustness of Angluin's L* Algorithm in Presence of Noise
Sep 21, 2022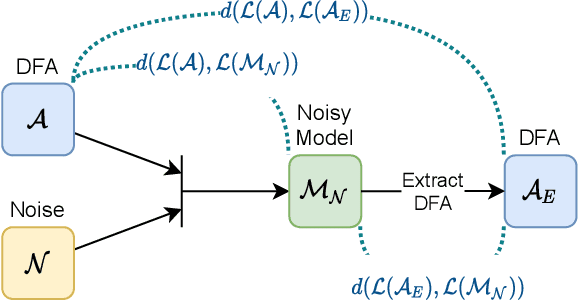
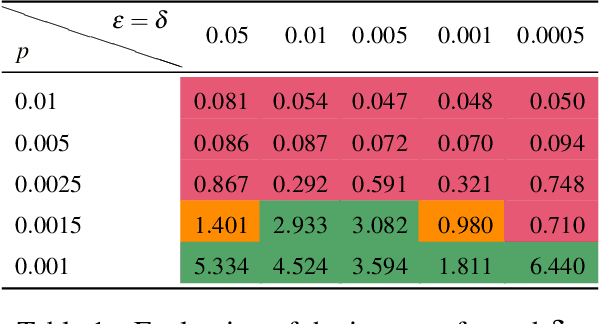
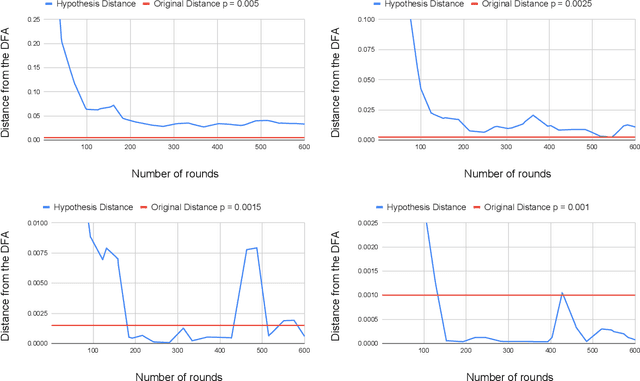
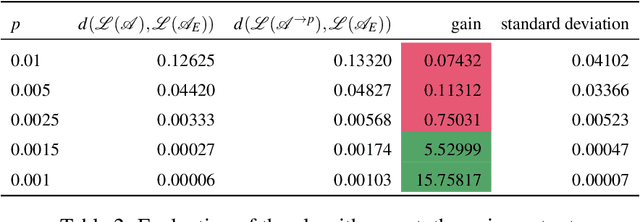
Angluin's L* algorithm learns the minimal (complete) deterministic finite automaton (DFA) of a regular language using membership and equivalence queries. Its probabilistic approximatively correct (PAC) version substitutes an equivalence query by a large enough set of random membership queries to get a high level confidence to the answer. Thus it can be applied to any kind of (also non-regular) device and may be viewed as an algorithm for synthesizing an automaton abstracting the behavior of the device based on observations. Here we are interested on how Angluin's PAC learning algorithm behaves for devices which are obtained from a DFA by introducing some noise. More precisely we study whether Angluin's algorithm reduces the noise and produces a DFA closer to the original one than the noisy device. We propose several ways to introduce the noise: (1) the noisy device inverts the classification of words w.r.t. the DFA with a small probability, (2) the noisy device modifies with a small probability the letters of the word before asking its classification w.r.t. the DFA, and (3) the noisy device combines the classification of a word w.r.t. the DFA and its classification w.r.t. a counter automaton. Our experiments were performed on several hundred DFAs. Our main contributions, bluntly stated, consist in showing that: (1) Angluin's algorithm behaves well whenever the noisy device is produced by a random process, (2) but poorly with a structured noise, and, that (3) almost surely randomness yields systems with non-recursively enumerable languages.
* In Proceedings GandALF 2022, arXiv:2209.09333
Responsible and Regulatory Conform Machine Learning for Medicine: A Survey of Technical Challenges and Solutions
Jul 20, 2021

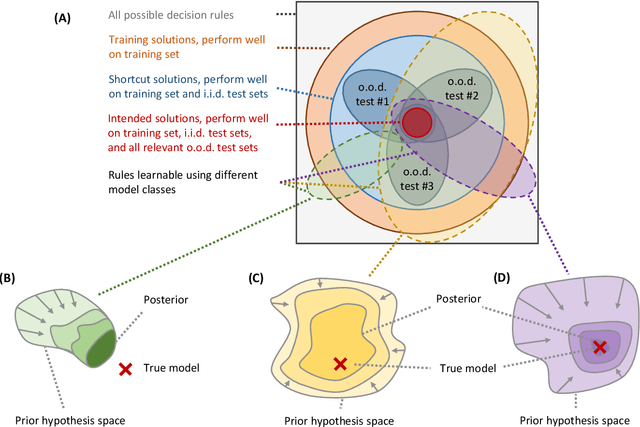

Machine learning is expected to fuel significant improvements in medical care. To ensure that fundamental principles such as beneficence, respect for human autonomy, prevention of harm, justice, privacy, and transparency are respected, medical machine learning applications must be developed responsibly. In this paper, we survey the technical challenges involved in creating medical machine learning systems responsibly and in conformity with existing regulations, as well as possible solutions to address these challenges. We begin by providing a brief overview of existing regulations affecting medical machine learning, showing that properties such as safety, robustness, reliability, privacy, security, transparency, explainability, and nondiscrimination are all demanded already by existing law and regulations - albeit, in many cases, to an uncertain degree. Next, we discuss the underlying technical challenges, possible ways for addressing them, and their respective merits and drawbacks. We notice that distribution shift, spurious correlations, model underspecification, and data scarcity represent severe challenges in the medical context (and others) that are very difficult to solve with classical black-box deep neural networks. Important measures that may help to address these challenges include the use of large and representative datasets and federated learning as a means to that end, the careful exploitation of domain knowledge wherever feasible, the use of inherently transparent models, comprehensive model testing and verification, as well as stakeholder inclusion.
Property-Directed Verification of Recurrent Neural Networks
Sep 22, 2020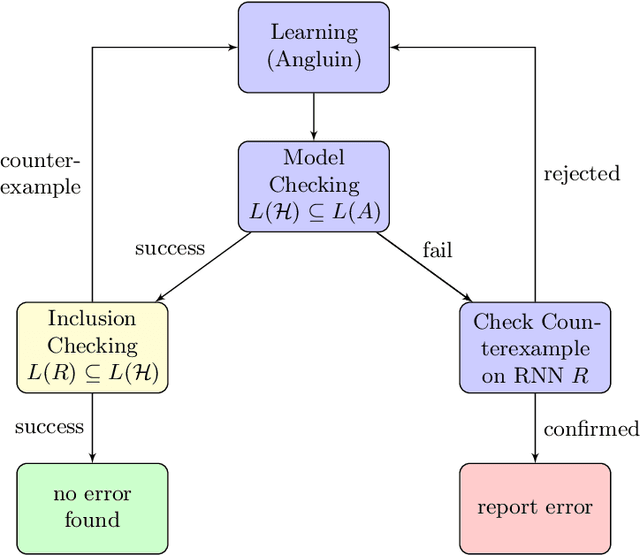
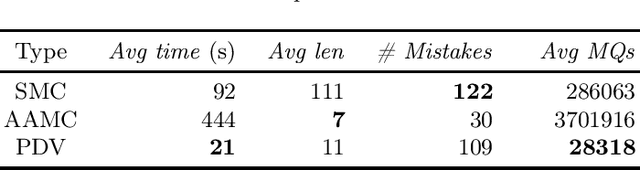
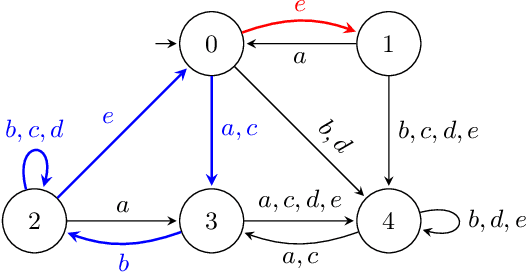
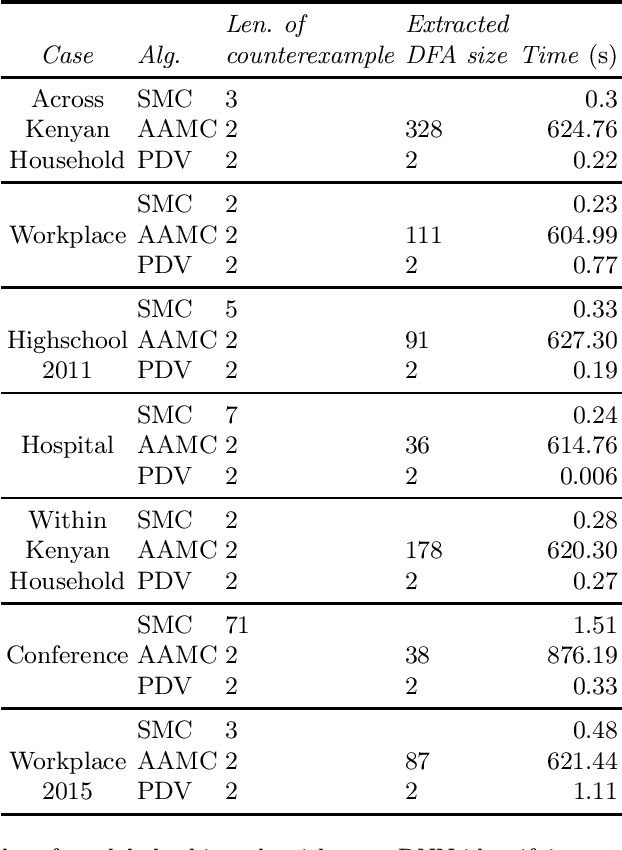
This paper presents a property-directed approach to verifying recurrent neural networks (RNNs). To this end, we learn a deterministic finite automaton as a surrogate model from a given RNN using active automata learning. This model may then be analyzed using model checking as verification technique. The term property-directed reflects the idea that our procedure is guided and controlled by the given property rather than performing the two steps separately. We show that this not only allows us to discover small counterexamples fast, but also to generalize them by pumping towards faulty flows hinting at the underlying error in the RNN.