 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-HYPE: Distributed Differentially Private Hyperparameter Search
Oct 06, 2025The tuning of hyperparameters in distributed machine learning can substantially impact model performance. When the hyperparameters are tuned on sensitive data, privacy becomes an important challenge and to this end, differential privacy has emerged as the de facto standard for provable privacy. A standard setting when performing distributed learning tasks is that clients agree on a shared setup, i.e., find a compromise from a set of hyperparameters, like the learning rate of the model to be trained. Yet, prior work on differentially private hyperparameter tuning either uses computationally expensive cryptographic protocols, determines hyperparameters separately for each client, or applies differential privacy locally, which can lead to undesirable utility-privacy trade-offs. In this work, we present our algorithm DP-HYPE, which performs a distributed and privacy-preserving hyperparameter search by conducting a distributed voting based on local hyperparameter evaluations of clients. In this way, DP-HYPE selects hyperparameters that lead to a compromise supported by the majority of clients, while maintaining scalability and independence from specific learning tasks. We prove that DP-HYPE preserves the strong notion of differential privacy called client-level differential privacy and, importantly, show that its privacy guarantees do not depend on the number of hyperparameters. We also provide bounds on its utility guarantees, that is, the probability of reaching a compromise, and implement DP-HYPE as a submodule in the popular Flower framework for distributed machine learning. In addition, we evaluate performance on multiple benchmark data sets in iid as well as multiple non-iid settings and demonstrate high utility of DP-HYPE even under small privacy budgets.
Non-omniscient backdoor injection with a single poison sample: Proving the one-poison hypothesis for linear regression and linear classification
Aug 07, 2025Backdoor injection attacks are a threat to machine learning models that are trained on large data collected from untrusted sources; these attacks enable attackers to inject malicious behavior into the model that can be triggered by specially crafted inputs. Prior work has established bounds on the success of backdoor attacks and their impact on the benign learning task, however, an open question is what amount of poison data is needed for a successful backdoor attack. Typical attacks either use few samples, but need much information about the data points or need to poison many data points. In this paper, we formulate the one-poison hypothesis: An adversary with one poison sample and limited background knowledge can inject a backdoor with zero backdooring-error and without significantly impacting the benign learning task performance. Moreover, we prove the one-poison hypothesis for linear regression and linear classification. For adversaries that utilize a direction that is unused by the benign data distribution for the poison sample, we show that the resulting model is functionally equivalent to a model where the poison was excluded from training. We build on prior work on statistical backdoor learning to show that in all other cases, the impact on the benign learning task is still limited. We also validate our theoretical results experimentally with realistic benchmark data sets.
S-GBDT: Frugal Differentially Private Gradient Boosting Decision Trees
Sep 28, 2023Privacy-preserving learning of gradient boosting decision trees (GBDT) has the potential for strong utility-privacy tradeoffs for tabular data, such as census data or medical meta data: classical GBDT learners can extract non-linear patterns from small sized datasets. The state-of-the-art notion for provable privacy-properties is differential privacy, which requires that the impact of single data points is limited and deniable. We introduce a novel differentially private GBDT learner and utilize four main techniques to improve the utility-privacy tradeoff. (1) We use an improved noise scaling approach with tighter accounting of privacy leakage of a decision tree leaf compared to prior work, resulting in noise that in expectation scales with $O(1/n)$, for $n$ data points. (2) We integrate individual R\'enyi filters to our method to learn from data points that have been underutilized during an iterative training process, which -- potentially of independent interest -- results in a natural yet effective insight to learning streams of non-i.i.d. data. (3) We incorporate the concept of random decision tree splits to concentrate privacy budget on learning leaves. (4) We deploy subsampling for privacy amplification. Our evaluation shows for the Abalone dataset ($<4k$ training data points) a $R^2$-score of $0.39$ for $\varepsilon=0.15$, which the closest prior work only achieved for $\varepsilon=10.0$. On the Adult dataset ($50k$ training data points) we achieve test error of $18.7\,\%$ for $\varepsilon=0.07$ which the closest prior work only achieved for $\varepsilon=1.0$. For the Abalone dataset for $\varepsilon=0.54$ we achieve $R^2$-score of $0.47$ which is very close to the $R^2$-score of $0.54$ for the nonprivate version of GBDT. For the Adult dataset for $\varepsilon=0.54$ we achieve test error $17.1\,\%$ which is very close to the test error $13.7\,\%$ of the nonprivate version of GBDT.
DPM: Clustering Sensitive Data through Separation
Jul 06, 2023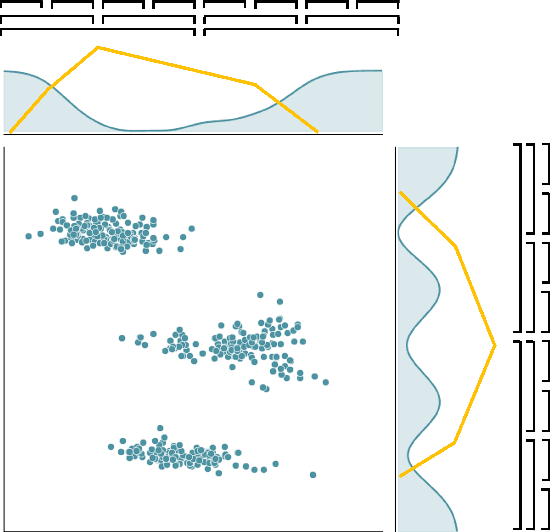
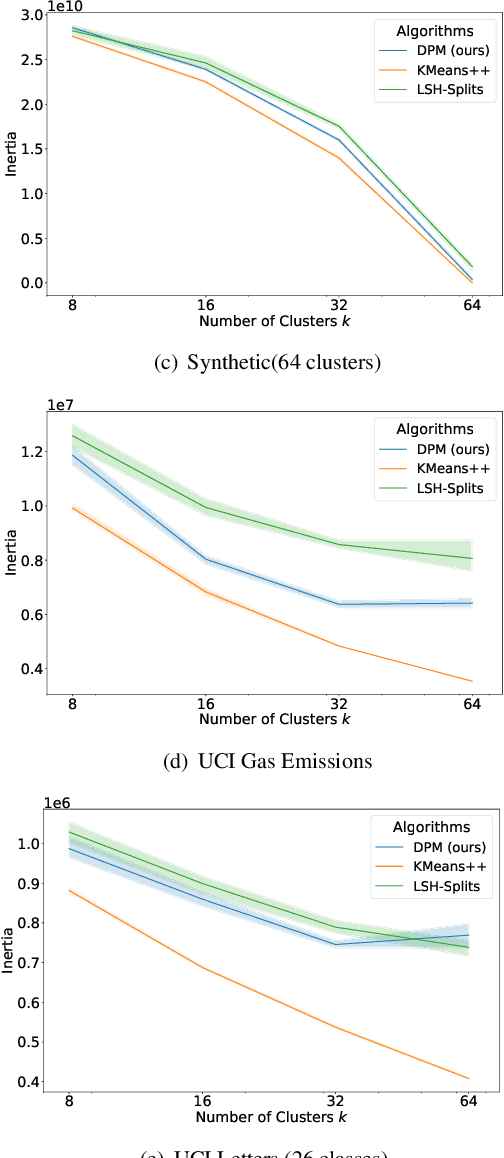
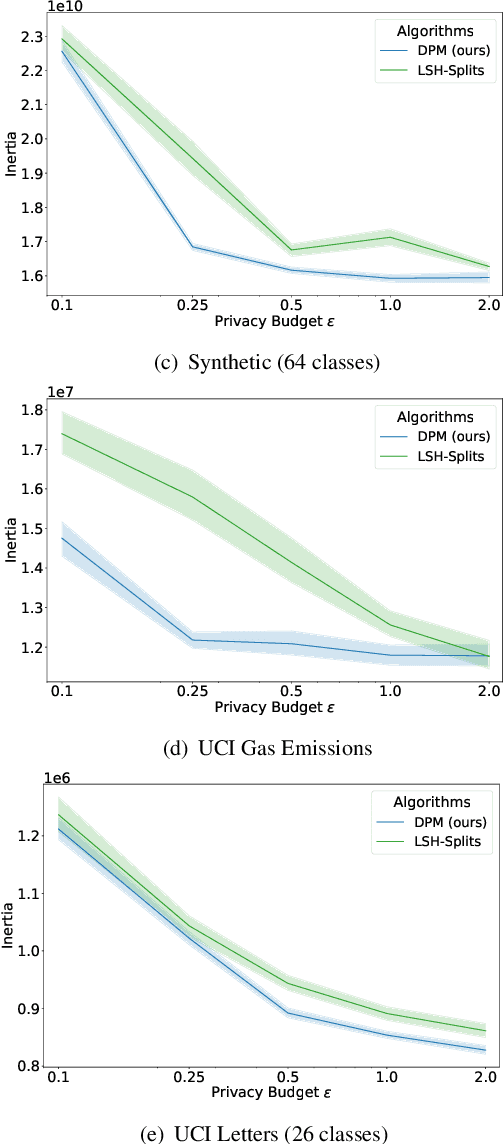
Privacy-preserving clustering groups data points in an unsupervised manner whilst ensuring that sensitive information remains protected. Previous privacy-preserving clustering focused on identifying concentration of point clouds. In this paper, we take another path and focus on identifying appropriate separators that split a data set. We introduce the novel differentially private clustering algorithm DPM that searches for accurate data point separators in a differentially private manner. DPM addresses two key challenges for finding accurate separators: identifying separators that are large gaps between clusters instead of small gaps within a cluster and, to efficiently spend the privacy budget, prioritising separators that split the data into large subparts. Using the differentially private Exponential Mechanism, DPM randomly chooses cluster separators with provably high utility: For a data set $D$, if there is a wide low-density separator in the central $60\%$ quantile, DPM finds that separator with probability $1 - \exp(-\sqrt{|D|})$. Our experimental evaluation demonstrates that DPM achieves significant improvements in terms of the clustering metric inertia. With the inertia results of the non-private KMeans++ as a baseline, for $\varepsilon = 1$ and $\delta=10^{-5}$ DPM improves upon the difference to the baseline by up to $50\%$ for a synthetic data set and by up to $62\%$ for a real-world data set compared to a state-of-the-art clustering algorithm by Chang and Kamath.
Single SMPC Invocation DPHelmet: Differentially Private Distributed Learning on a Large Scale
Nov 03, 2022Distributing machine learning predictors enables the collection of large-scale datasets while leaving sensitive raw data at trustworthy sites. We show that locally training support vector machines (SVMs) and computing their averages leads to a learning technique that is scalable to a large number of users, satisfies differential privacy, and is applicable to non-trivial tasks, such as CIFAR-10. For a large number of participants, communication cost is one of the main challenges. We achieve a low communication cost by requiring only a single invocation of an efficient secure multiparty summation protocol. By relying on state-of-the-art feature extractors (SimCLR), we are able to utilize differentially private convex learners for non-trivial tasks such as CIFAR-10. Our experimental results illustrate that for $1{,}000$ users with $50$ data points each, our scheme outperforms state-of-the-art scalable distributed learning methods (differentially private federated learning, short DP-FL) while requiring around $500$ times fewer communication costs: For CIFAR-10, we achieve a classification accuracy of $79.7\,\%$ for an $\varepsilon = 0.59$ while DP-FL achieves $57.6\,\%$. More generally, we prove learnability properties for the average of such locally trained models: convergence and uniform stability. By only requiring strongly convex, smooth, and Lipschitz-continuous objective functions, locally trained via stochastic gradient descent (SGD), we achieve a strong utility-privacy tradeoff.
Learning Numeric Optimal Differentially Private Truncated Additive Mechanisms
Jul 27, 2021
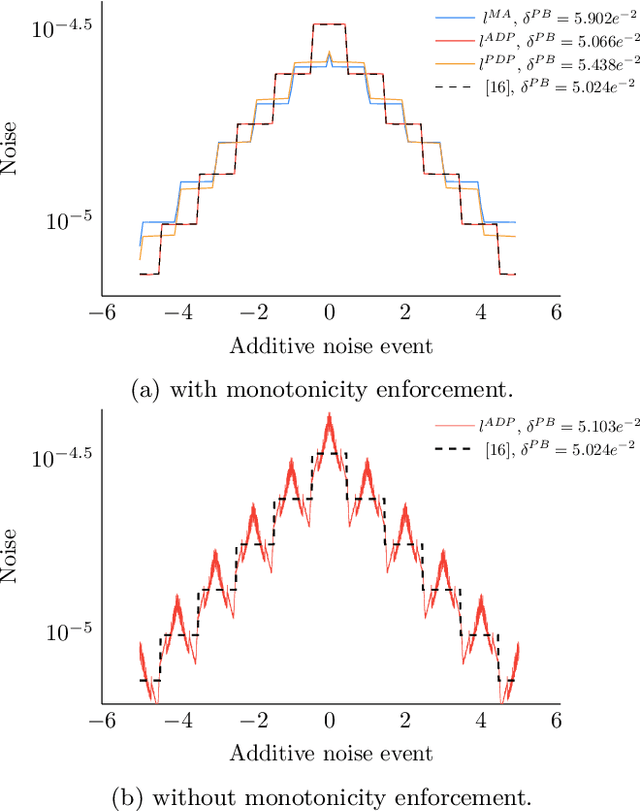
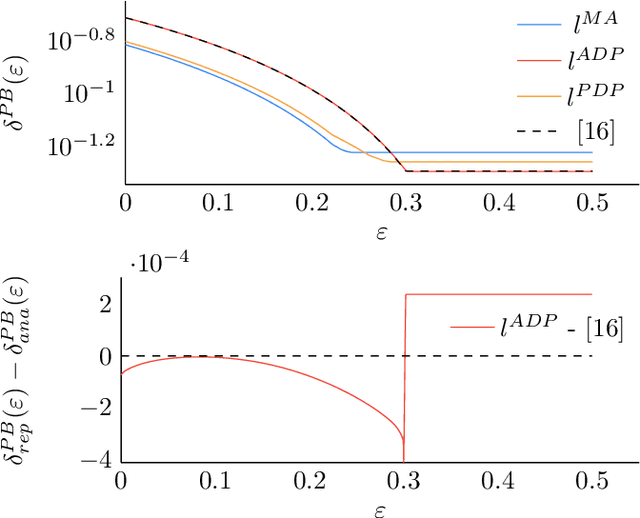
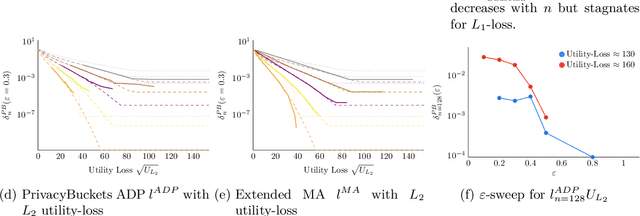
Differentially private (DP) mechanisms face the challenge of providing accurate results while protecting their inputs: the privacy-utility trade-off. A simple but powerful technique for DP adds noise to sensitivity-bounded query outputs to blur the exact query output: additive mechanisms. While a vast body of work considers infinitely wide noise distributions, some applications (e.g., real-time operating systems) require hard bounds on the deviations from the real query, and only limited work on such mechanisms exist. An additive mechanism with truncated noise (i.e., with bounded range) can offer such hard bounds. We introduce a gradient-descent-based tool to learn truncated noise for additive mechanisms with strong utility bounds while simultaneously optimizing for differential privacy under sequential composition, i.e., scenarios where multiple noisy queries on the same data are revealed. Our method can learn discrete noise patterns and not only hyper-parameters of a predefined probability distribution. For sensitivity bounded mechanisms, we show that it is sufficient to consider symmetric and that\new{, for from the mean monotonically falling noise,} ensuring privacy for a pair of representative query outputs guarantees privacy for all pairs of inputs (that differ in one element). We find that the utility-privacy trade-off curves of our generated noise are remarkably close to truncated Gaussians and even replicate their shape for $l_2$ utility-loss. For a low number of compositions, we also improved DP-SGD (sub-sampling). Moreover, we extend Moments Accountant to truncated distributions, allowing to incorporate mechanism output events with varying input-dependent zero occurrence probability.
Responsible and Regulatory Conform Machine Learning for Medicine: A Survey of Technical Challenges and Solutions
Jul 20, 2021

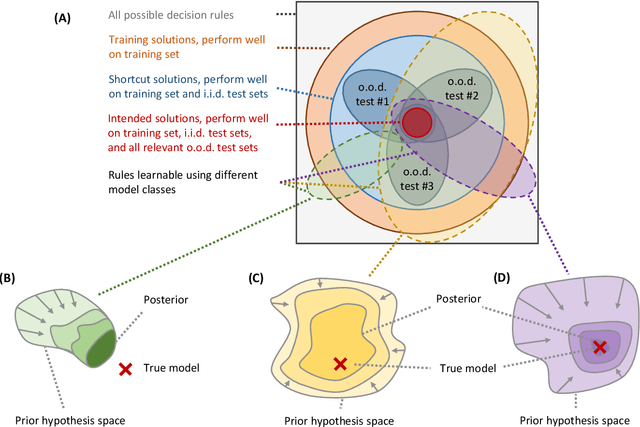

Machine learning is expected to fuel significant improvements in medical care. To ensure that fundamental principles such as beneficence, respect for human autonomy, prevention of harm, justice, privacy, and transparency are respected, medical machine learning applications must be developed responsibly. In this paper, we survey the technical challenges involved in creating medical machine learning systems responsibly and in conformity with existing regulations, as well as possible solutions to address these challenges. We begin by providing a brief overview of existing regulations affecting medical machine learning, showing that properties such as safety, robustness, reliability, privacy, security, transparency, explainability, and nondiscrimination are all demanded already by existing law and regulations - albeit, in many cases, to an uncertain degree. Next, we discuss the underlying technical challenges, possible ways for addressing them, and their respective merits and drawbacks. We notice that distribution shift, spurious correlations, model underspecification, and data scarcity represent severe challenges in the medical context (and others) that are very difficult to solve with classical black-box deep neural networks. Important measures that may help to address these challenges include the use of large and representative datasets and federated learning as a means to that end, the careful exploitation of domain knowledge wherever feasible, the use of inherently transparent models, comprehensive model testing and verification, as well as stakeholder inclusion.