 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Robustness in Machine Learning: A Posterior Agreement Approach
Mar 20, 2025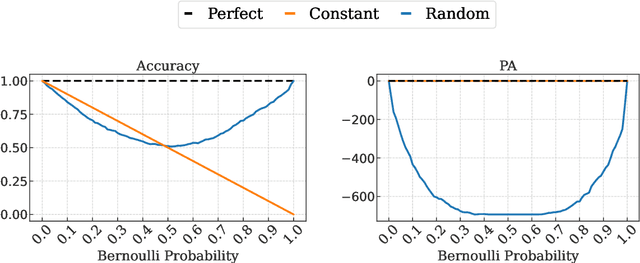

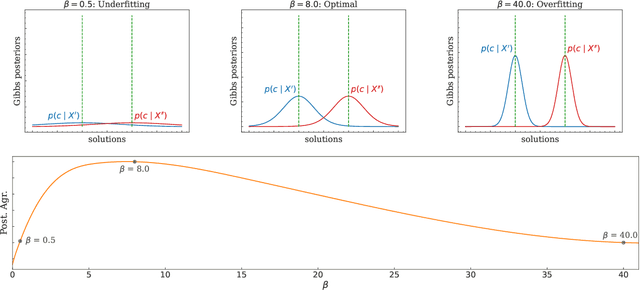

The robustness of algorithms against covariate shifts is a fundamental problem with critical implications for the deployment of machine learning algorithms in the real world. Current evaluation methods predominantly match the robustness definition to that of standard generalization, relying on standard metrics like accuracy-based scores, which, while designed for performance assessment, lack a theoretical foundation encompassing their application in estimating robustness to distribution shifts. In this work, we set the desiderata for a robustness metric, and we propose a novel principled framework for the robustness assessment problem that directly follows the Posterior Agreement (PA) theory of model validation. Specifically, we extend the PA framework to the covariate shift setting by proposing a PA metric for robustness evaluation in supervised classification tasks. We assess the soundness of our metric in controlled environments and through an empirical robustness analysis in two different covariate shift scenarios: adversarial learning and domain generalization. We illustrate the suitability of PA by evaluating several models under different nature and magnitudes of shift, and proportion of affected observations. The results show that the PA metric provides a sensible and consistent analysis of the vulnerabilities in learning algorithms, even in the presence of few perturbed observations.
Invariant Anomaly Detection under Distribution Shifts: A Causal Perspective
Dec 21, 2023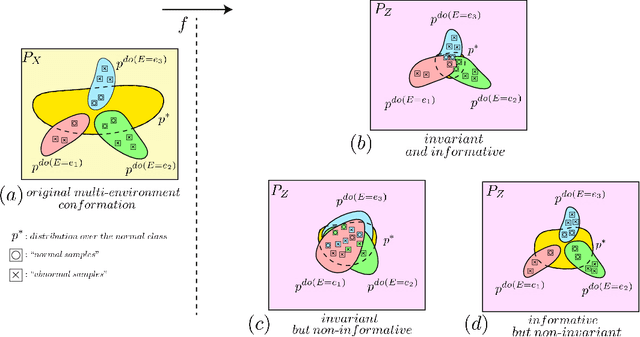
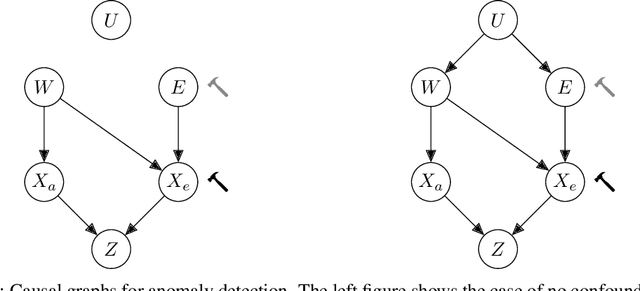
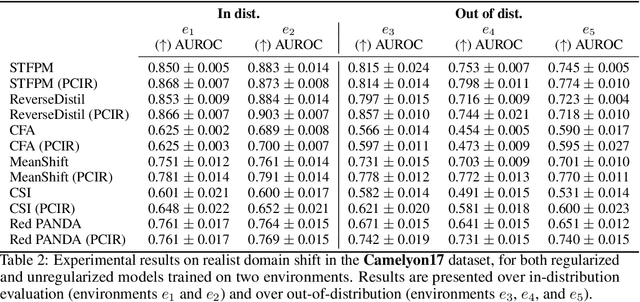
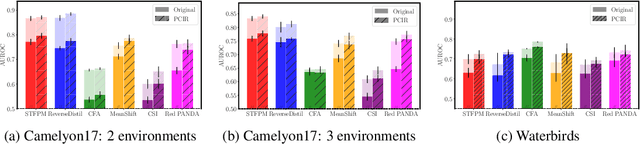
Anomaly detection (AD) is the machine learning task of identifying highly discrepant abnormal samples by solely relying on the consistency of the normal training samples. Under the constraints of a distribution shift, the assumption that training samples and test samples are drawn from the same distribution breaks down. In this work, by leveraging tools from causal inference we attempt to increase the resilience of anomaly detection models to different kinds of distribution shifts. We begin by elucidating a simple yet necessary statistical property that ensures invariant representations, which is critical for robust AD under both domain and covariate shifts. From this property, we derive a regularization term which, when minimized, leads to partial distribution invariance across environments. Through extensive experimental evaluation on both synthetic and real-world tasks, covering a range of six different AD methods, we demonstrated significant improvements in out-of-distribution performance. Under both covariate and domain shift, models regularized with our proposed term showed marked increased robustness. Code is available at: https://github.com/JoaoCarv/invariant-anomaly-detection.
S-GBDT: Frugal Differentially Private Gradient Boosting Decision Trees
Sep 28, 2023Privacy-preserving learning of gradient boosting decision trees (GBDT) has the potential for strong utility-privacy tradeoffs for tabular data, such as census data or medical meta data: classical GBDT learners can extract non-linear patterns from small sized datasets. The state-of-the-art notion for provable privacy-properties is differential privacy, which requires that the impact of single data points is limited and deniable. We introduce a novel differentially private GBDT learner and utilize four main techniques to improve the utility-privacy tradeoff. (1) We use an improved noise scaling approach with tighter accounting of privacy leakage of a decision tree leaf compared to prior work, resulting in noise that in expectation scales with $O(1/n)$, for $n$ data points. (2) We integrate individual R\'enyi filters to our method to learn from data points that have been underutilized during an iterative training process, which -- potentially of independent interest -- results in a natural yet effective insight to learning streams of non-i.i.d. data. (3) We incorporate the concept of random decision tree splits to concentrate privacy budget on learning leaves. (4) We deploy subsampling for privacy amplification. Our evaluation shows for the Abalone dataset ($<4k$ training data points) a $R^2$-score of $0.39$ for $\varepsilon=0.15$, which the closest prior work only achieved for $\varepsilon=10.0$. On the Adult dataset ($50k$ training data points) we achieve test error of $18.7\,\%$ for $\varepsilon=0.07$ which the closest prior work only achieved for $\varepsilon=1.0$. For the Abalone dataset for $\varepsilon=0.54$ we achieve $R^2$-score of $0.47$ which is very close to the $R^2$-score of $0.54$ for the nonprivate version of GBDT. For the Adult dataset for $\varepsilon=0.54$ we achieve test error $17.1\,\%$ which is very close to the test error $13.7\,\%$ of the nonprivate version of GBDT.