 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Trust Stubborn Neighbors: A Security Framework for Agentic Networks
Mar 16, 2026Large Language Model (LLM)-based Multi-Agent Systems (MASs) are increasingly deployed for agentic tasks, such as web automation, itinerary planning, and collaborative problem solving. Yet, their interactive nature introduces new security risks: malicious or compromised agents can exploit communication channels to propagate misinformation and manipulate collective outcomes. In this paper, we study how such manipulation can arise and spread by borrowing the Friedkin-Johnsen opinion formation model from social sciences to propose a general theoretical framework to study LLM-MAS. Remarkably, this model closely captures LLM-MAS behavior, as we verify in extensive experiments across different network topologies and attack and defense scenarios. Theoretically and empirically, we find that a single highly stubborn and persuasive agent can take over MAS dynamics, underscoring the systems' high susceptibility to attacks by triggering a persuasion cascade that reshapes collective opinion. Our theoretical analysis reveals three mechanisms to increase system security: a) increasing the number of benign agents, b) increasing the innate stubbornness or peer-resistance of agents, or c) reducing trust in potential adversaries. Because scaling is computationally expensive and high stubbornness degrades the network's ability to reach consensus, we propose a new mechanism to mitigate threats by a trust-adaptive defense that dynamically adjusts inter-agent trust to limit adversarial influence while maintaining cooperative performance. Extensive experiments confirm that this mechanism effectively defends against manipulation.
Unknown Unknowns: Why Hidden Intentions in LLMs Evade Detection
Jan 26, 2026LLMs are increasingly embedded in everyday decision-making, yet their outputs can encode subtle, unintended behaviours that shape user beliefs and actions. We refer to these covert, goal-directed behaviours as hidden intentions, which may arise from training and optimisation artefacts, or be deliberately induced by an adversarial developer, yet remain difficult to detect in practice. We introduce a taxonomy of ten categories of hidden intentions, grounded in social science research and organised by intent, mechanism, context, and impact, shifting attention from surface-level behaviours to design-level strategies of influence. We show how hidden intentions can be easily induced in controlled models, providing both testbeds for evaluation and demonstrations of potential misuse. We systematically assess detection methods, including reasoning and non-reasoning LLM judges, and find that detection collapses in realistic open-world settings, particularly under low-prevalence conditions, where false positives overwhelm precision and false negatives conceal true risks. Stress tests on precision-prevalence and precision-FNR trade-offs reveal why auditing fails without vanishingly small false positive rates or strong priors on manipulation types. Finally, a qualitative case study shows that all ten categories manifest in deployed, state-of-the-art LLMs, emphasising the urgent need for robust frameworks. Our work provides the first systematic analysis of detectability failures of hidden intentions in LLMs under open-world settings, offering a foundation for understanding, inducing, and stress-testing such behaviours, and establishing a flexible taxonomy for anticipating evolving threats and informing governance.
Buffer-free Class-Incremental Learning with Out-of-Distribution Detection
May 29, 2025Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.
Security Benefits and Side Effects of Labeling AI-Generated Images
May 28, 2025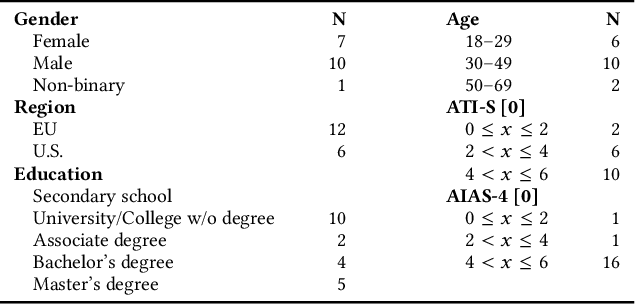

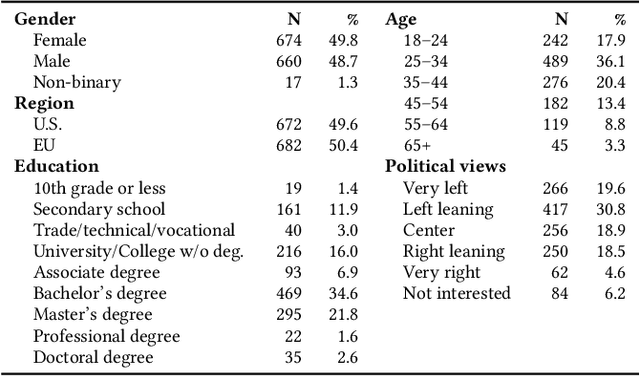
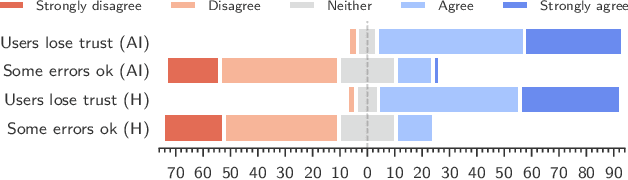
Generative artificial intelligence is developing rapidly, impacting humans' interaction with information and digital media. It is increasingly used to create deceptively realistic misinformation, so lawmakers have imposed regulations requiring the disclosure of AI-generated content. However, only little is known about whether these labels reduce the risks of AI-generated misinformation. Our work addresses this research gap. Focusing on AI-generated images, we study the implications of labels, including the possibility of mislabeling. Assuming that simplicity, transparency, and trust are likely to impact the successful adoption of such labels, we first qualitatively explore users' opinions and expectations of AI labeling using five focus groups. Second, we conduct a pre-registered online survey with over 1300 U.S. and EU participants to quantitatively assess the effect of AI labels on users' ability to recognize misinformation containing either human-made or AI-generated images. Our focus groups illustrate that, while participants have concerns about the practical implementation of labeling, they consider it helpful in identifying AI-generated images and avoiding deception. However, considering security benefits, our survey revealed an ambiguous picture, suggesting that users might over-rely on labels. While inaccurate claims supported by labeled AI-generated images were rated less credible than those with unlabeled AI-images, the belief in accurate claims also decreased when accompanied by a labeled AI-generated image. Moreover, we find the undesired side effect that human-made images conveying inaccurate claims were perceived as more credible in the presence of labels.
Rethinking Robustness in Machine Learning: A Posterior Agreement Approach
Mar 20, 2025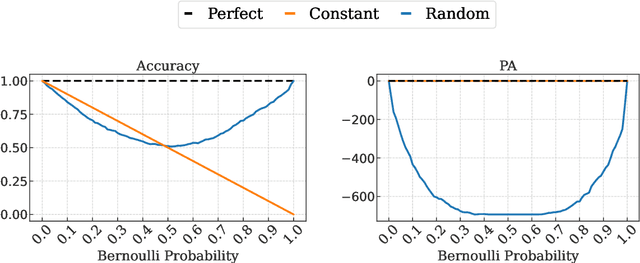

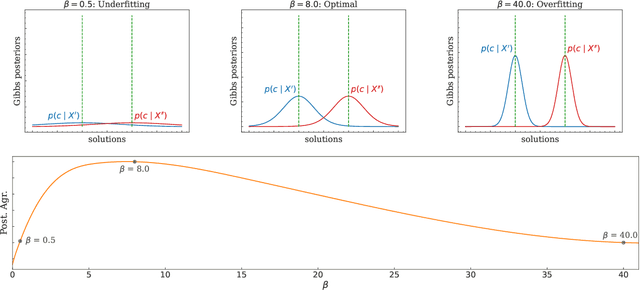

The robustness of algorithms against covariate shifts is a fundamental problem with critical implications for the deployment of machine learning algorithms in the real world. Current evaluation methods predominantly match the robustness definition to that of standard generalization, relying on standard metrics like accuracy-based scores, which, while designed for performance assessment, lack a theoretical foundation encompassing their application in estimating robustness to distribution shifts. In this work, we set the desiderata for a robustness metric, and we propose a novel principled framework for the robustness assessment problem that directly follows the Posterior Agreement (PA) theory of model validation. Specifically, we extend the PA framework to the covariate shift setting by proposing a PA metric for robustness evaluation in supervised classification tasks. We assess the soundness of our metric in controlled environments and through an empirical robustness analysis in two different covariate shift scenarios: adversarial learning and domain generalization. We illustrate the suitability of PA by evaluating several models under different nature and magnitudes of shift, and proportion of affected observations. The results show that the PA metric provides a sensible and consistent analysis of the vulnerabilities in learning algorithms, even in the presence of few perturbed observations.
Prompt Obfuscation for Large Language Models
Sep 17, 2024
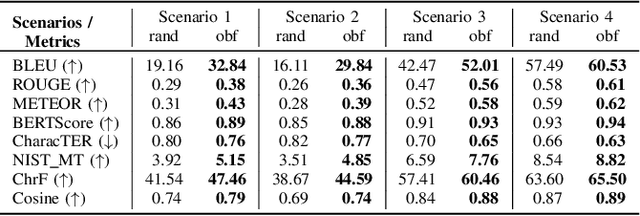

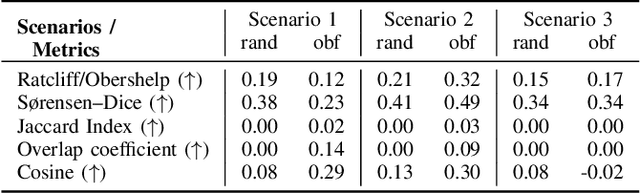
System prompts that include detailed instructions to describe the task performed by the underlying large language model (LLM) can easily transform foundation models into tools and services with minimal overhead. Because of their crucial impact on the utility, they are often considered intellectual property, similar to the code of a software product. However, extracting system prompts is easily possible by using prompt injection. As of today, there is no effective countermeasure to prevent the stealing of system prompts and all safeguarding efforts could be evaded with carefully crafted prompt injections that bypass all protection mechanisms.In this work, we propose an alternative to conventional system prompts. We introduce prompt obfuscation to prevent the extraction of the system prompt while maintaining the utility of the system itself with only little overhead. The core idea is to find a representation of the original system prompt that leads to the same functionality, while the obfuscated system prompt does not contain any information that allows conclusions to be drawn about the original system prompt. We implement an optimization-based method to find an obfuscated prompt representation while maintaining the functionality. To evaluate our approach, we investigate eight different metrics to compare the performance of a system using the original and the obfuscated system prompts, and we show that the obfuscated version is constantly on par with the original one. We further perform three different deobfuscation attacks and show that with access to the obfuscated prompt and the LLM itself, we are not able to consistently extract meaningful information. Overall, we showed that prompt obfuscation can be an effective method to protect intellectual property while maintaining the same utility as the original system prompt.
HexaCoder: Secure Code Generation via Oracle-Guided Synthetic Training Data
Sep 10, 2024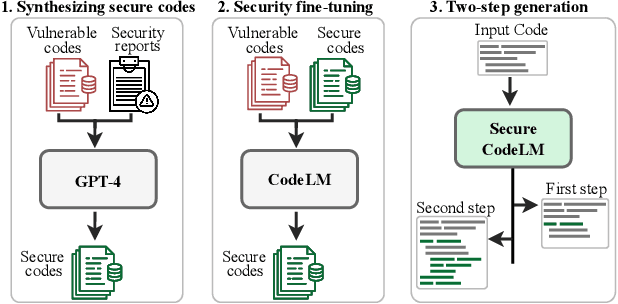



Large language models (LLMs) have shown great potential for automatic code generation and form the basis for various tools such as GitHub Copilot. However, recent studies highlight that many LLM-generated code contains serious security vulnerabilities. While previous work tries to address this by training models that generate secure code, these attempts remain constrained by limited access to training data and labor-intensive data preparation. In this paper, we introduce HexaCoder, a novel approach to enhance the ability of LLMs to generate secure codes by automatically synthesizing secure codes, which reduces the effort of finding suitable training data. HexaCoder comprises two key components: an oracle-guided data synthesis pipeline and a two-step process for secure code generation. The data synthesis pipeline generates pairs of vulnerable and fixed codes for specific Common Weakness Enumeration (CWE) types by utilizing a state-of-the-art LLM for repairing vulnerable code. A security oracle identifies vulnerabilities, and a state-of-the-art LLM repairs them by extending and/or editing the codes, creating data pairs for fine-tuning using the Low-Rank Adaptation (LoRA) method. Each example of our fine-tuning dataset includes the necessary security-related libraries and code that form the basis of our novel two-step generation approach. This allows the model to integrate security-relevant libraries before generating the main code, significantly reducing the number of generated vulnerable codes by up to 85% compared to the baseline methods. We perform extensive evaluations on three different benchmarks for four LLMs, demonstrating that HexaCoder not only improves the security of the generated code but also maintains a high level of functional correctness.
Rag and Roll: An End-to-End Evaluation of Indirect Prompt Manipulations in LLM-based Application Frameworks
Aug 09, 2024



Retrieval Augmented Generation (RAG) is a technique commonly used to equip models with out of distribution knowledge. This process involves collecting, indexing, retrieving, and providing information to an LLM for generating responses. Despite its growing popularity due to its flexibility and low cost, the security implications of RAG have not been extensively studied. The data for such systems are often collected from public sources, providing an attacker a gateway for indirect prompt injections to manipulate the responses of the model. In this paper, we investigate the security of RAG systems against end-to-end indirect prompt manipulations. First, we review existing RAG framework pipelines deriving a prototypical architecture and identifying potentially critical configuration parameters. We then examine prior works searching for techniques that attackers can use to perform indirect prompt manipulations. Finally, implemented Rag n Roll, a framework to determine the effectiveness of attacks against end-to-end RAG applications. Our results show that existing attacks are mostly optimized to boost the ranking of malicious documents during the retrieval phase. However, a higher rank does not immediately translate into a reliable attack. Most attacks, against various configurations, settle around a 40% success rate, which could rise to 60% when considering ambiguous answers as successful attacks (those that include the expected benign one as well). Additionally, when using unoptimized documents, attackers deploying two of them (or more) for a target query can achieve similar results as those using optimized ones. Finally, exploration of the configuration space of a RAG showed limited impact in thwarting the attacks, where the most successful combination severely undermines functionality.
Dataset and Lessons Learned from the 2024 SaTML LLM Capture-the-Flag Competition
Jun 12, 2024



Large language model systems face important security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
Whispers in the Machine: Confidentiality in LLM-integrated Systems
Feb 10, 2024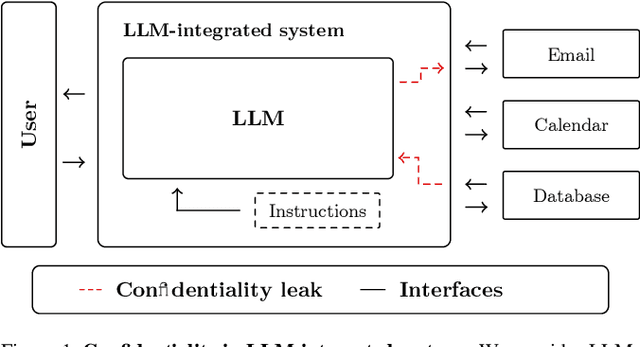
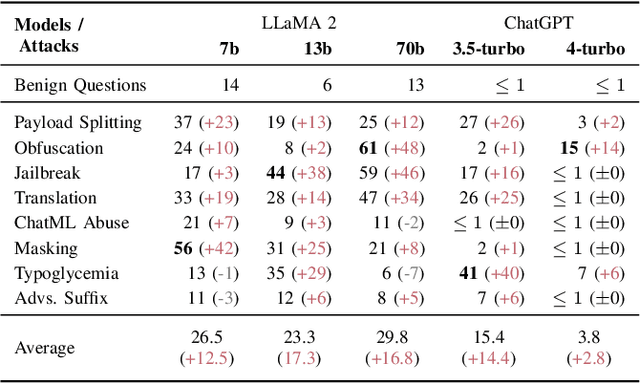
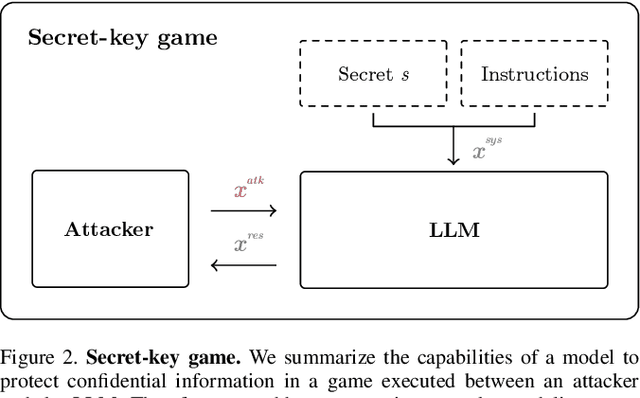
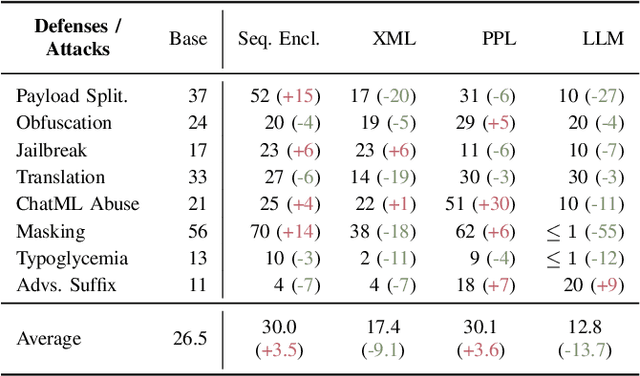
Large Language Models (LLMs) are increasingly integrated with external tools. While these integrations can significantly improve the functionality of LLMs, they also create a new attack surface where confidential data may be disclosed between different components. Specifically, malicious tools can exploit vulnerabilities in the LLM itself to manipulate the model and compromise the data of other services, raising the question of how private data can be protected in the context of LLM integrations. In this work, we provide a systematic way of evaluating confidentiality in LLM-integrated systems. For this, we formalize a "secret key" game that can capture the ability of a model to conceal private information. This enables us to compare the vulnerability of a model against confidentiality attacks and also the effectiveness of different defense strategies. In this framework, we evaluate eight previously published attacks and four defenses. We find that current defenses lack generalization across attack strategies. Building on this analysis, we propose a method for robustness fine-tuning, inspired by adversarial training. This approach is effective in lowering the success rate of attackers and in improving the system's resilience against unknown attacks.