 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection for Continual Learning: Design Principles and Benchmarking
Dec 16, 2025



Recent years have witnessed significant progress in the development of machine learning models across a wide range of fields, fueled by increased computational resources, large-scale datasets, and the rise of deep learning architectures. From malware detection to enabling autonomous navigation, modern machine learning systems have demonstrated remarkable capabilities. However, as these models are deployed in ever-changing real-world scenarios, their ability to remain reliable and adaptive over time becomes increasingly important. For example, in the real world, new malware families are continuously developed, whereas autonomous driving cars are employed in many different cities and weather conditions. Models trained in fixed settings can not respond effectively to novel conditions encountered post-deployment. In fact, most machine learning models are still developed under the assumption that training and test data are independent and identically distributed (i.i.d.), i.e., sampled from the same underlying (unknown) distribution. While this assumption simplifies model development and evaluation, it does not hold in many real-world applications, where data changes over time and unexpected inputs frequently occur. Retraining models from scratch whenever new data appears is computationally expensive, time-consuming, and impractical in resource-constrained environments. These limitations underscore the need for Continual Learning (CL), which enables models to incrementally learn from evolving data streams without forgetting past knowledge, and Out-of-Distribution (OOD) detection, which allows systems to identify and respond to novel or anomalous inputs. Jointly addressing both challenges is critical to developing robust, efficient, and adaptive AI systems.
Buffer-free Class-Incremental Learning with Out-of-Distribution Detection
May 29, 2025Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.
On the Robustness of Adversarial Training Against Uncertainty Attacks
Oct 29, 2024


In learning problems, the noise inherent to the task at hand hinders the possibility to infer without a certain degree of uncertainty. Quantifying this uncertainty, regardless of its wide use, assumes high relevance for security-sensitive applications. Within these scenarios, it becomes fundamental to guarantee good (i.e., trustworthy) uncertainty measures, which downstream modules can securely employ to drive the final decision-making process. However, an attacker may be interested in forcing the system to produce either (i) highly uncertain outputs jeopardizing the system's availability or (ii) low uncertainty estimates, making the system accept uncertain samples that would instead require a careful inspection (e.g., human intervention). Therefore, it becomes fundamental to understand how to obtain robust uncertainty estimates against these kinds of attacks. In this work, we reveal both empirically and theoretically that defending against adversarial examples, i.e., carefully perturbed samples that cause misclassification, additionally guarantees a more secure, trustworthy uncertainty estimate under common attack scenarios without the need for an ad-hoc defense strategy. To support our claims, we evaluate multiple adversarial-robust models from the publicly available benchmark RobustBench on the CIFAR-10 and ImageNet datasets.
Robustness-Congruent Adversarial Training for Secure Machine Learning Model Updates
Feb 27, 2024



Machine-learning models demand for periodic updates to improve their average accuracy, exploiting novel architectures and additional data. However, a newly-updated model may commit mistakes that the previous model did not make. Such misclassifications are referred to as negative flips, and experienced by users as a regression of performance. In this work, we show that this problem also affects robustness to adversarial examples, thereby hindering the development of secure model update practices. In particular, when updating a model to improve its adversarial robustness, some previously-ineffective adversarial examples may become misclassified, causing a regression in the perceived security of the system. We propose a novel technique, named robustness-congruent adversarial training, to address this issue. It amounts to fine-tuning a model with adversarial training, while constraining it to retain higher robustness on the adversarial examples that were correctly classified before the update. We show that our algorithm and, more generally, learning with non-regression constraints, provides a theoretically-grounded framework to train consistent estimators. Our experiments on robust models for computer vision confirm that (i) both accuracy and robustness, even if improved after model update, can be affected by negative flips, and (ii) our robustness-congruent adversarial training can mitigate the problem, outperforming competing baseline methods.
Adversarial Attacks Against Uncertainty Quantification
Sep 19, 2023Machine-learning models can be fooled by adversarial examples, i.e., carefully-crafted input perturbations that force models to output wrong predictions. While uncertainty quantification has been recently proposed to detect adversarial inputs, under the assumption that such attacks exhibit a higher prediction uncertainty than pristine data, it has been shown that adaptive attacks specifically aimed at reducing also the uncertainty estimate can easily bypass this defense mechanism. In this work, we focus on a different adversarial scenario in which the attacker is still interested in manipulating the uncertainty estimate, but regardless of the correctness of the prediction; in particular, the goal is to undermine the use of machine-learning models when their outputs are consumed by a downstream module or by a human operator. Following such direction, we: \textit{(i)} design a threat model for attacks targeting uncertainty quantification; \textit{(ii)} devise different attack strategies on conceptually different UQ techniques spanning for both classification and semantic segmentation problems; \textit{(iii)} conduct a first complete and extensive analysis to compare the differences between some of the most employed UQ approaches under attack. Our extensive experimental analysis shows that our attacks are more effective in manipulating uncertainty quantification measures than attacks aimed to also induce misclassifications.
ImageNet-Patch: A Dataset for Benchmarking Machine Learning Robustness against Adversarial Patches
Mar 07, 2022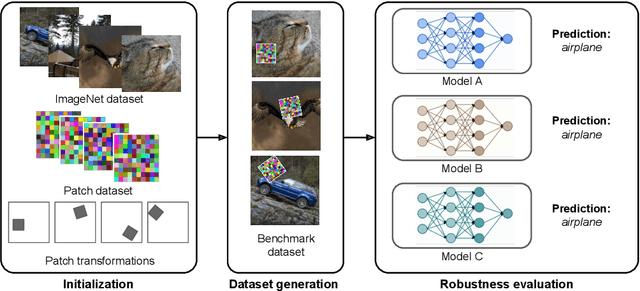
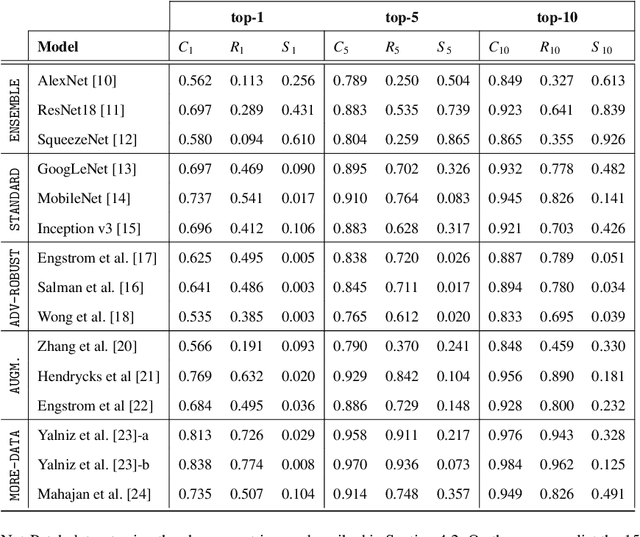
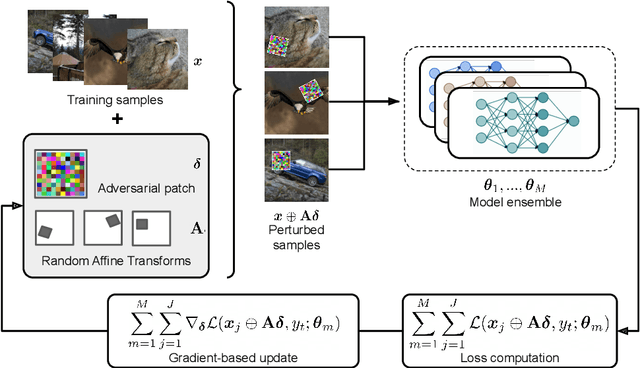
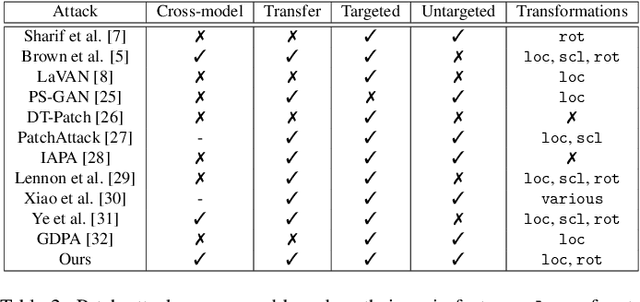
Adversarial patches are optimized contiguous pixel blocks in an input image that cause a machine-learning model to misclassify it. However, their optimization is computationally demanding, and requires careful hyperparameter tuning, potentially leading to suboptimal robustness evaluations. To overcome these issues, we propose ImageNet-Patch, a dataset to benchmark machine-learning models against adversarial patches. It consists of a set of patches, optimized to generalize across different models, and readily applicable to ImageNet data after preprocessing them with affine transformations. This process enables an approximate yet faster robustness evaluation, leveraging the transferability of adversarial perturbations. We showcase the usefulness of this dataset by testing the effectiveness of the computed patches against 127 models. We conclude by discussing how our dataset could be used as a benchmark for robustness, and how our methodology can be generalized to other domains. We open source our dataset and evaluation code at https://github.com/pralab/ImageNet-Patch.
Are spoofs from latent fingerprints a real threat for the best state-of-art liveness detectors?
Jul 07, 2020
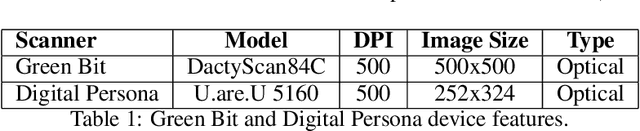


We investigated the threat level of realistic attacks using latent fingerprints against sensors equipped with state-of-art liveness detectors and fingerprint verification systems which integrate such liveness algorithms. To the best of our knowledge, only a previous investigation was done with spoofs from latent prints. In this paper, we focus on using snapshot pictures of latent fingerprints. These pictures provide molds, that allows, after some digital processing, to fabricate high-quality spoofs. Taking a snapshot picture is much simpler than developing fingerprints left on a surface by magnetic powders and lifting the trace by a tape. What we are interested here is to evaluate preliminary at which extent attacks of the kind can be considered a real threat for state-of-art fingerprint liveness detectors and verification systems. To this aim, we collected a novel data set of live and spoof images fabricated with snapshot pictures of latent fingerprints. This data set provide a set of attacks at the most favourable conditions. We refer to this method and the related data set as "ScreenSpoof". Then, we tested with it the performances of the best liveness detection algorithms, namely, the three winners of the LivDet competition. Reported results point out that the ScreenSpoof method is a threat of the same level, in terms of detection and verification errors, than that of attacks using spoofs fabricated with the full consensus of the victim. We think that this is a notable result, never reported in previous work.