 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Quantification of Spurious Correlations in Malware Detection
Jun 11, 2025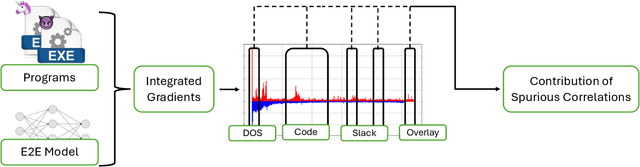
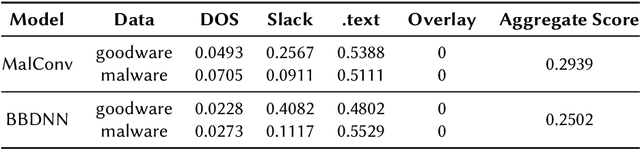
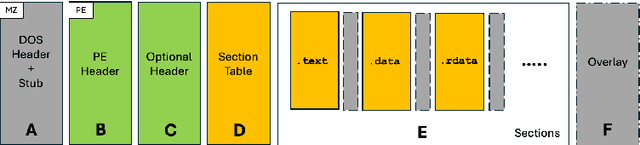
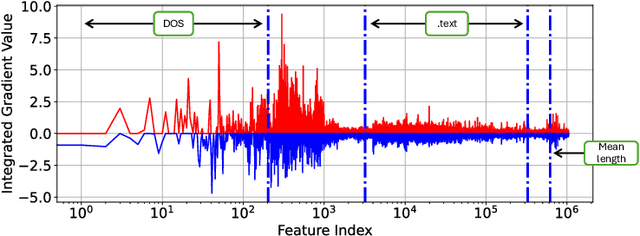
End-to-end deep learning exhibits unmatched performance for detecting malware, but such an achievement is reached by exploiting spurious correlations -- features with high relevance at inference time, but known to be useless through domain knowledge. While previous work highlighted that deep networks mainly focus on metadata, none investigated the phenomenon further, without quantifying their impact on the decision. In this work, we deepen our understanding of how spurious correlation affects deep learning for malware detection by highlighting how much models rely on empty spaces left by the compiler, which diminishes the relevance of the compiled code. Through our seminal analysis on a small-scale balanced dataset, we introduce a ranking of two end-to-end models to better understand which is more suitable to be put in production.
Trust Under Siege: Label Spoofing Attacks against Machine Learning for Android Malware Detection
Mar 14, 2025Machine learning (ML) malware detectors rely heavily on crowd-sourced AntiVirus (AV) labels, with platforms like VirusTotal serving as a trusted source of malware annotations. But what if attackers could manipulate these labels to classify benign software as malicious? We introduce label spoofing attacks, a new threat that contaminates crowd-sourced datasets by embedding minimal and undetectable malicious patterns into benign samples. These patterns coerce AV engines into misclassifying legitimate files as harmful, enabling poisoning attacks against ML-based malware classifiers trained on those data. We demonstrate this scenario by developing AndroVenom, a methodology for polluting realistic data sources, causing consequent poisoning attacks against ML malware detectors. Experiments show that not only state-of-the-art feature extractors are unable to filter such injection, but also various ML models experience Denial of Service already with 1% poisoned samples. Additionally, attackers can flip decisions of specific unaltered benign samples by modifying only 0.015% of the training data, threatening their reputation and market share and being unable to be stopped by anomaly detectors on training data. We conclude our manuscript by raising the alarm on the trustworthiness of the training process based on AV annotations, requiring further investigation on how to produce proper labels for ML malware detectors.
ModSec-Learn: Boosting ModSecurity with Machine Learning
Jun 19, 2024ModSecurity is widely recognized as the standard open-source Web Application Firewall (WAF), maintained by the OWASP Foundation. It detects malicious requests by matching them against the Core Rule Set (CRS), identifying well-known attack patterns. Each rule is manually assigned a weight based on the severity of the corresponding attack, and a request is blocked if the sum of the weights of matched rules exceeds a given threshold. However, we argue that this strategy is largely ineffective against web attacks, as detection is only based on heuristics and not customized on the application to protect. In this work, we overcome this issue by proposing a machine-learning model that uses the CRS rules as input features. Through training, ModSec-Learn is able to tune the contribution of each CRS rule to predictions, thus adapting the severity level to the web applications to protect. Our experiments show that ModSec-Learn achieves a significantly better trade-off between detection and false positive rates. Finally, we analyze how sparse regularization can reduce the number of rules that are relevant at inference time, by discarding more than 30% of the CRS rules. We release our open-source code and the dataset at https://github.com/pralab/modsec-learn and https://github.com/pralab/http-traffic-dataset, respectively.
Over-parameterization and Adversarial Robustness in Neural Networks: An Overview and Empirical Analysis
Jun 14, 2024



Thanks to their extensive capacity, over-parameterized neural networks exhibit superior predictive capabilities and generalization. However, having a large parameter space is considered one of the main suspects of the neural networks' vulnerability to adversarial example -- input samples crafted ad-hoc to induce a desired misclassification. Relevant literature has claimed contradictory remarks in support of and against the robustness of over-parameterized networks. These contradictory findings might be due to the failure of the attack employed to evaluate the networks' robustness. Previous research has demonstrated that depending on the considered model, the algorithm employed to generate adversarial examples may not function properly, leading to overestimating the model's robustness. In this work, we empirically study the robustness of over-parameterized networks against adversarial examples. However, unlike the previous works, we also evaluate the considered attack's reliability to support the results' veracity. Our results show that over-parameterized networks are robust against adversarial attacks as opposed to their under-parameterized counterparts.
SLIFER: Investigating Performance and Robustness of Malware Detection Pipelines
May 23, 2024

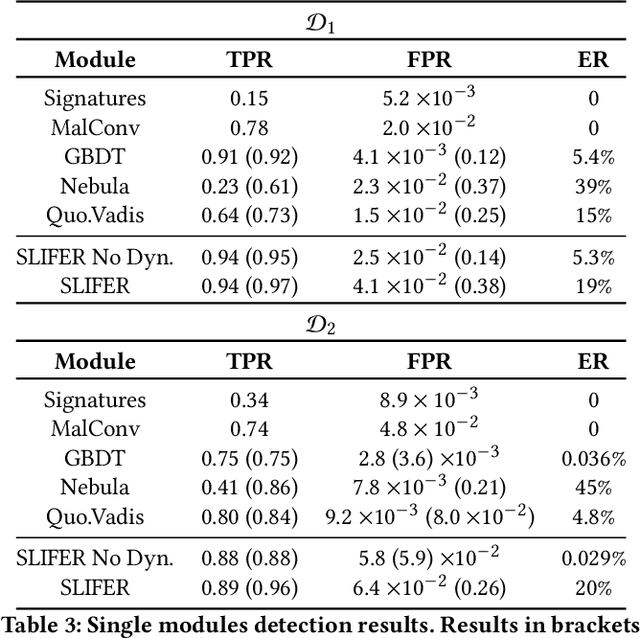

As a result of decades of research, Windows malware detection is approached through a plethora of techniques. However, there is an ongoing mismatch between academia -- which pursues an optimal performances in terms of detection rate and low false alarms -- and the requirements of real-world scenarios. In particular, academia focuses on combining static and dynamic analysis within a single or ensemble of models, falling into several pitfalls like (i) firing dynamic analysis without considering the computational burden it requires; (ii) discarding impossible-to-analyse samples; and (iii) analysing robustness against adversarial attacks without considering that malware detectors are complemented with more non-machine-learning components. Thus, in this paper we propose SLIFER, a novel Windows malware detection pipeline sequentially leveraging both static and dynamic analysis, interrupting computations as soon as one module triggers an alarm, requiring dynamic analysis only when needed. Contrary to the state of the art, we investigate how to deal with samples resistance to analysis, showing how much they impact performances, concluding that it is better to flag them as legitimate to not drastically increase false alarms. Lastly, we perform a robustness evaluation of SLIFER leveraging content-injections attacks, and we show that, counter-intuitively, attacks are blocked more by YARA rules than dynamic analysis due to byte artifacts created while optimizing the adversarial strategy.
A New Formulation for Zeroth-Order Optimization of Adversarial EXEmples in Malware Detection
May 23, 2024
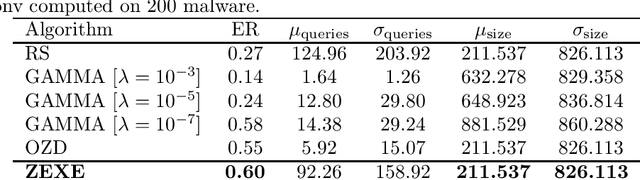
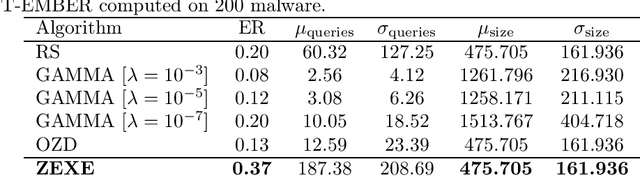
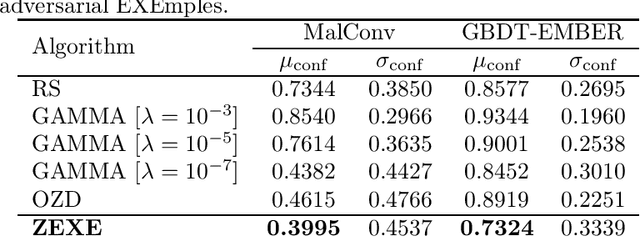
Machine learning malware detectors are vulnerable to adversarial EXEmples, i.e. carefully-crafted Windows programs tailored to evade detection. Unlike other adversarial problems, attacks in this context must be functionality-preserving, a constraint which is challenging to address. As a consequence heuristic algorithms are typically used, that inject new content, either randomly-picked or harvested from legitimate programs. In this paper, we show how learning malware detectors can be cast within a zeroth-order optimization framework which allows to incorporate functionality-preserving manipulations. This permits the deployment of sound and efficient gradient-free optimization algorithms, which come with theoretical guarantees and allow for minimal hyper-parameters tuning. As a by-product, we propose and study ZEXE, a novel zero-order attack against Windows malware detection. Compared to state-of-the-art techniques, ZEXE provides drastic improvement in the evasion rate, while reducing to less than one third the size of the injected content.
Certified Adversarial Robustness of Machine Learning-based Malware Detectors via (De)Randomized Smoothing
May 01, 2024
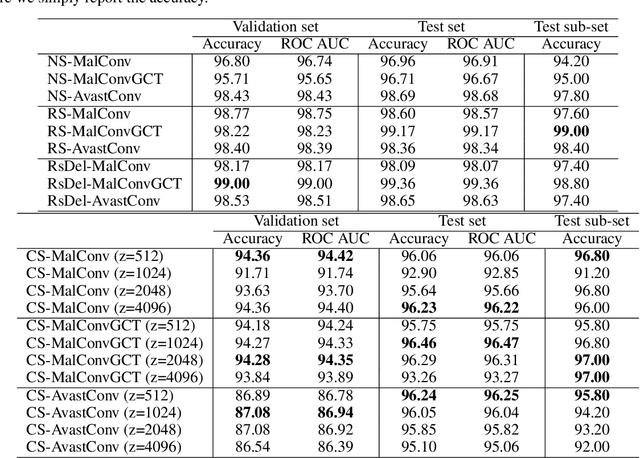


Deep learning-based malware detection systems are vulnerable to adversarial EXEmples - carefully-crafted malicious programs that evade detection with minimal perturbation. As such, the community is dedicating effort to develop mechanisms to defend against adversarial EXEmples. However, current randomized smoothing-based defenses are still vulnerable to attacks that inject blocks of adversarial content. In this paper, we introduce a certifiable defense against patch attacks that guarantees, for a given executable and an adversarial patch size, no adversarial EXEmple exist. Our method is inspired by (de)randomized smoothing which provides deterministic robustness certificates. During training, a base classifier is trained using subsets of continguous bytes. At inference time, our defense splits the executable into non-overlapping chunks, classifies each chunk independently, and computes the final prediction through majority voting to minimize the influence of injected content. Furthermore, we introduce a preprocessing step that fixes the size of the sections and headers to a multiple of the chunk size. As a consequence, the injected content is confined to an integer number of chunks without tampering the other chunks containing the real bytes of the input examples, allowing us to extend our certified robustness guarantees to content insertion attacks. We perform an extensive ablation study, by comparing our defense with randomized smoothing-based defenses against a plethora of content manipulation attacks and neural network architectures. Results show that our method exhibits unmatched robustness against strong content-insertion attacks, outperforming randomized smoothing-based defenses in the literature.
AttackBench: Evaluating Gradient-based Attacks for Adversarial Examples
Apr 30, 2024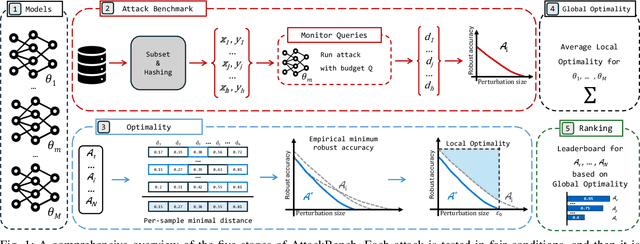
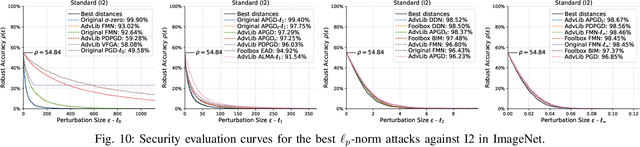
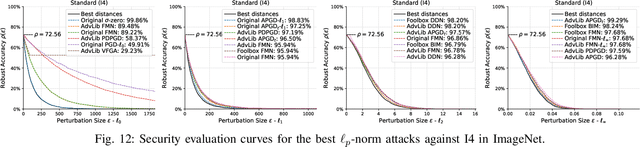
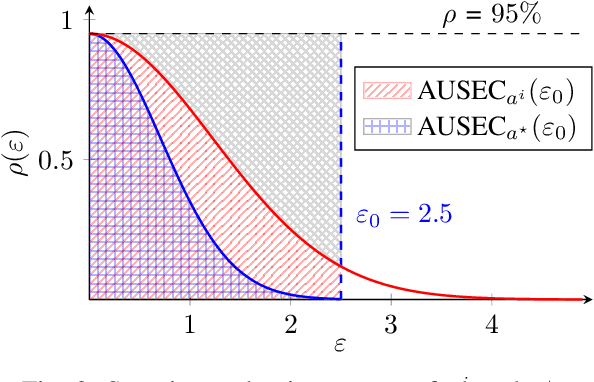
Adversarial examples are typically optimized with gradient-based attacks. While novel attacks are continuously proposed, each is shown to outperform its predecessors using different experimental setups, hyperparameter settings, and number of forward and backward calls to the target models. This provides overly-optimistic and even biased evaluations that may unfairly favor one particular attack over the others. In this work, we aim to overcome these limitations by proposing AttackBench, i.e., the first evaluation framework that enables a fair comparison among different attacks. To this end, we first propose a categorization of gradient-based attacks, identifying their main components and differences. We then introduce our framework, which evaluates their effectiveness and efficiency. We measure these characteristics by (i) defining an optimality metric that quantifies how close an attack is to the optimal solution, and (ii) limiting the number of forward and backward queries to the model, such that all attacks are compared within a given maximum query budget. Our extensive experimental analysis compares more than 100 attack implementations with a total of over 800 different configurations against CIFAR-10 and ImageNet models, highlighting that only very few attacks outperform all the competing approaches. Within this analysis, we shed light on several implementation issues that prevent many attacks from finding better solutions or running at all. We release AttackBench as a publicly available benchmark, aiming to continuously update it to include and evaluate novel gradient-based attacks for optimizing adversarial examples.
Living-off-The-Land Reverse-Shell Detection by Informed Data Augmentation
Feb 28, 2024



The living-off-the-land (LOTL) offensive methodologies rely on the perpetration of malicious actions through chains of commands executed by legitimate applications, identifiable exclusively by analysis of system logs. LOTL techniques are well hidden inside the stream of events generated by common legitimate activities, moreover threat actors often camouflage activity through obfuscation, making them particularly difficult to detect without incurring in plenty of false alarms, even using machine learning. To improve the performance of models in such an harsh environment, we propose an augmentation framework to enhance and diversify the presence of LOTL malicious activity inside legitimate logs. Guided by threat intelligence, we generate a dataset by injecting attack templates known to be employed in the wild, further enriched by malleable patterns of legitimate activities to replicate the behavior of evasive threat actors. We conduct an extensive ablation study to understand which models better handle our augmented dataset, also manipulated to mimic the presence of model-agnostic evasion and poisoning attacks. Our results suggest that augmentation is needed to maintain high-predictive capabilities, robustness to attack is achieved through specific hardening techniques like adversarial training, and it is possible to deploy near-real-time models with almost-zero false alarms.
Robustness-Congruent Adversarial Training for Secure Machine Learning Model Updates
Feb 27, 2024



Machine-learning models demand for periodic updates to improve their average accuracy, exploiting novel architectures and additional data. However, a newly-updated model may commit mistakes that the previous model did not make. Such misclassifications are referred to as negative flips, and experienced by users as a regression of performance. In this work, we show that this problem also affects robustness to adversarial examples, thereby hindering the development of secure model update practices. In particular, when updating a model to improve its adversarial robustness, some previously-ineffective adversarial examples may become misclassified, causing a regression in the perceived security of the system. We propose a novel technique, named robustness-congruent adversarial training, to address this issue. It amounts to fine-tuning a model with adversarial training, while constraining it to retain higher robustness on the adversarial examples that were correctly classified before the update. We show that our algorithm and, more generally, learning with non-regression constraints, provides a theoretically-grounded framework to train consistent estimators. Our experiments on robust models for computer vision confirm that (i) both accuracy and robustness, even if improved after model update, can be affected by negative flips, and (ii) our robustness-congruent adversarial training can mitigate the problem, outperforming competing baseline methods.