 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModSec-Learn: Boosting ModSecurity with Machine Learning
Jun 19, 2024ModSecurity is widely recognized as the standard open-source Web Application Firewall (WAF), maintained by the OWASP Foundation. It detects malicious requests by matching them against the Core Rule Set (CRS), identifying well-known attack patterns. Each rule is manually assigned a weight based on the severity of the corresponding attack, and a request is blocked if the sum of the weights of matched rules exceeds a given threshold. However, we argue that this strategy is largely ineffective against web attacks, as detection is only based on heuristics and not customized on the application to protect. In this work, we overcome this issue by proposing a machine-learning model that uses the CRS rules as input features. Through training, ModSec-Learn is able to tune the contribution of each CRS rule to predictions, thus adapting the severity level to the web applications to protect. Our experiments show that ModSec-Learn achieves a significantly better trade-off between detection and false positive rates. Finally, we analyze how sparse regularization can reduce the number of rules that are relevant at inference time, by discarding more than 30% of the CRS rules. We release our open-source code and the dataset at https://github.com/pralab/modsec-learn and https://github.com/pralab/http-traffic-dataset, respectively.
Strategies to Counter Artificial Intelligence in Law Enforcement: Cross-Country Comparison of Citizens in Greece, Italy and Spain
May 30, 2024

This paper investigates citizens' counter-strategies to the use of Artificial Intelligence (AI) by law enforcement agencies (LEAs). Based on information from three countries (Greece, Italy and Spain) we demonstrate disparities in the likelihood of ten specific counter-strategies. We further identified factors that increase the propensity for counter-strategies. Our study provides an important new perspective to societal impacts of security-focused AI applications by illustrating the conscious, strategic choices by citizens when confronted with AI capabilities for LEAs.
Adversarial ModSecurity: Countering Adversarial SQL Injections with Robust Machine Learning
Aug 17, 2023



ModSecurity is widely recognized as the standard open-source Web Application Firewall (WAF), maintained by the OWASP Foundation. It detects malicious requests by matching them against the Core Rule Set, identifying well-known attack patterns. Each rule in the CRS is manually assigned a weight, based on the severity of the corresponding attack, and a request is detected as malicious if the sum of the weights of the firing rules exceeds a given threshold. In this work, we show that this simple strategy is largely ineffective for detecting SQL injection (SQLi) attacks, as it tends to block many legitimate requests, while also being vulnerable to adversarial SQLi attacks, i.e., attacks intentionally manipulated to evade detection. To overcome these issues, we design a robust machine learning model, named AdvModSec, which uses the CRS rules as input features, and it is trained to detect adversarial SQLi attacks. Our experiments show that AdvModSec, being trained on the traffic directed towards the protected web services, achieves a better trade-off between detection and false positive rates, improving the detection rate of the vanilla version of ModSecurity with CRS by 21%. Moreover, our approach is able to improve its adversarial robustness against adversarial SQLi attacks by 42%, thereby taking a step forward towards building more robust and trustworthy WAFs.
Poisoning Behavioral Malware Clustering
Nov 25, 2018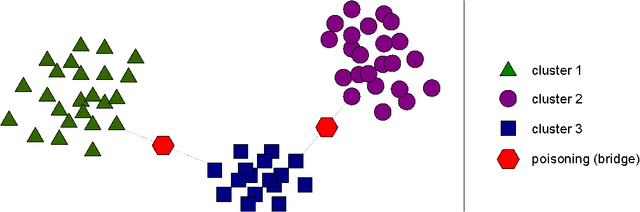

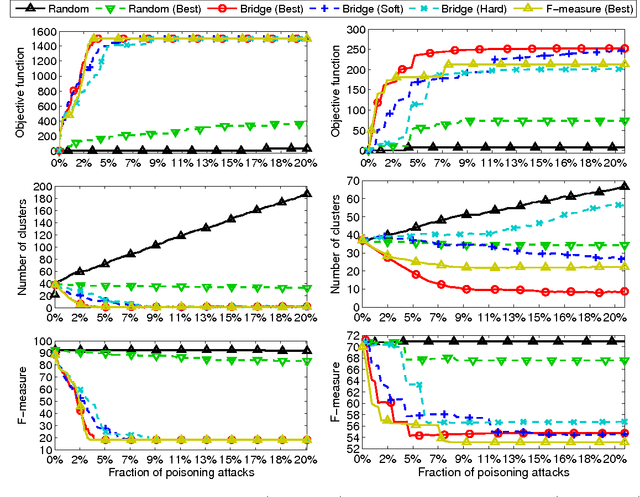
Clustering algorithms have become a popular tool in computer security to analyze the behavior of malware variants, identify novel malware families, and generate signatures for antivirus systems. However, the suitability of clustering algorithms for security-sensitive settings has been recently questioned by showing that they can be significantly compromised if an attacker can exercise some control over the input data. In this paper, we revisit this problem by focusing on behavioral malware clustering approaches, and investigate whether and to what extent an attacker may be able to subvert these approaches through a careful injection of samples with poisoning behavior. To this end, we present a case study on Malheur, an open-source tool for behavioral malware clustering. Our experiments not only demonstrate that this tool is vulnerable to poisoning attacks, but also that it can be significantly compromised even if the attacker can only inject a very small percentage of attacks into the input data. As a remedy, we discuss possible countermeasures and highlight the need for more secure clustering algorithms.
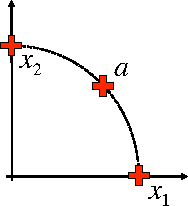
Is Data Clustering in Adversarial Settings Secure?
Nov 25, 2018
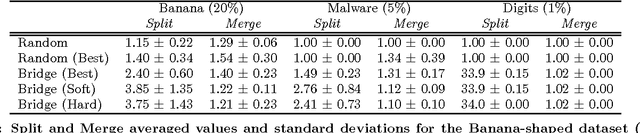


Clustering algorithms have been increasingly adopted in security applications to spot dangerous or illicit activities. However, they have not been originally devised to deal with deliberate attack attempts that may aim to subvert the clustering process itself. Whether clustering can be safely adopted in such settings remains thus questionable. In this work we propose a general framework that allows one to identify potential attacks against clustering algorithms, and to evaluate their impact, by making specific assumptions on the adversary's goal, knowledge of the attacked system, and capabilities of manipulating the input data. We show that an attacker may significantly poison the whole clustering process by adding a relatively small percentage of attack samples to the input data, and that some attack samples may be obfuscated to be hidden within some existing clusters. We present a case study on single-linkage hierarchical clustering, and report experiments on clustering of malware samples and handwritten digits.