 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-efficient Training Updates for Malware Detection over Time
Mar 30, 2026Machine Learning (ML)-based detectors are becoming essential to counter the proliferation of malware. However, common ML algorithms are not designed to cope with the dynamic nature of real-world settings, where both legitimate and malicious software evolve. This distribution drift causes models trained under static assumptions to degrade over time unless they are continuously updated. Regularly retraining these models, however, is expensive, since labeling new acquired data requires costly manual analysis by security experts. To reduce labeling costs and address distribution drift in malware detection, prior work explored active learning (AL) and semi-supervised learning (SSL) techniques. Yet, existing studies (i) are tightly coupled to specific detector architectures and restricted to a specific malware domain, resulting in non-uniform comparisons; and (ii) lack a consistent methodology for analyzing the distribution drift, despite the critical sensitivity of the malware domain to temporal changes. In this work, we bridge this gap by proposing a model-agnostic framework that evaluates an extensive set of AL and SSL techniques, isolated and combined, for Android and Windows malware detection. We show that these techniques, when combined, can reduce manual annotation costs by up to 90% across both domains while achieving comparable detection performance to full-labeling retraining. We also introduce a methodology for feature-level drift analysis that measures feature stability over time, showing its correlation with the detector performance. Overall, our study provides a detailed understanding of how AL and SSL behave under distribution drift and how they can be successfully combined, offering practical insights for the design of effective detectors over time.
Are Trees Really Green? A Detection Approach of IoT Malware Attacks
Jun 09, 2025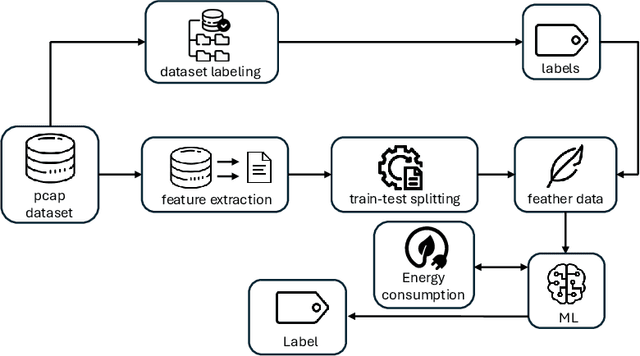
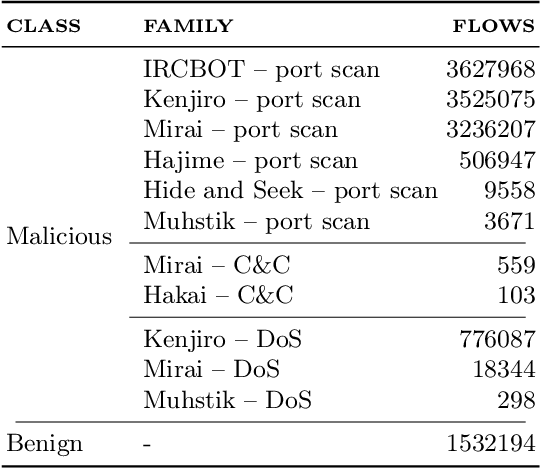

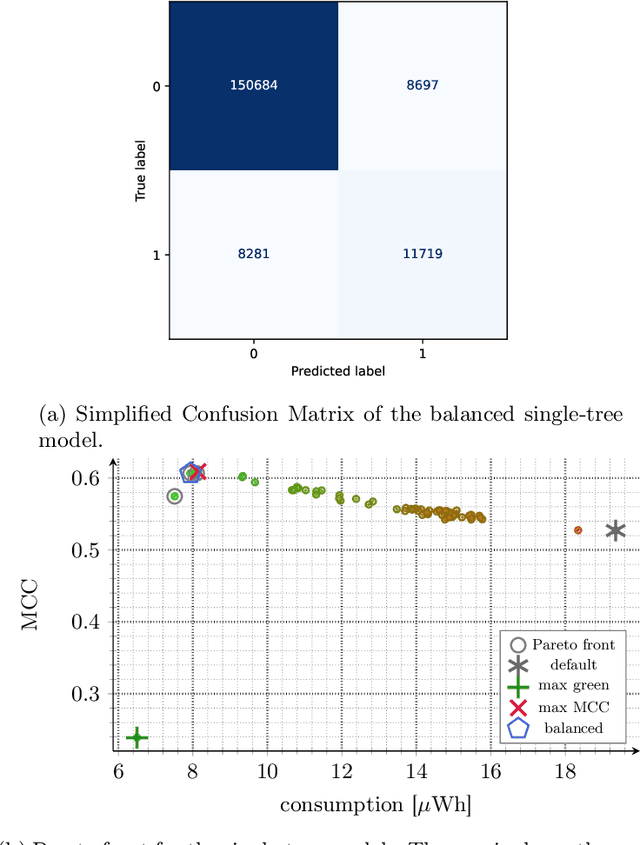
Nowadays, the Internet of Things (IoT) is widely employed, and its usage is growing exponentially because it facilitates remote monitoring, predictive maintenance, and data-driven decision making, especially in the healthcare and industrial sectors. However, IoT devices remain vulnerable due to their resource constraints and difficulty in applying security patches. Consequently, various cybersecurity attacks are reported daily, such as Denial of Service, particularly in IoT-driven solutions. Most attack detection methodologies are based on Machine Learning (ML) techniques, which can detect attack patterns. However, the focus is more on identification rather than considering the impact of ML algorithms on computational resources. This paper proposes a green methodology to identify IoT malware networking attacks based on flow privacy-preserving statistical features. In particular, the hyperparameters of three tree-based models -- Decision Trees, Random Forest and Extra-Trees -- are optimized based on energy consumption and test-time performance in terms of Matthew's Correlation Coefficient. Our results show that models maintain high performance and detection accuracy while consistently reducing power usage in terms of watt-hours (Wh). This suggests that on-premise ML-based Intrusion Detection Systems are suitable for IoT and other resource-constrained devices.
Exploring the Robustness of AI-Driven Tools in Digital Forensics: A Preliminary Study
Dec 02, 2024



Nowadays, many tools are used to facilitate forensic tasks about data extraction and data analysis. In particular, some tools leverage Artificial Intelligence (AI) to automatically label examined data into specific categories (\ie, drugs, weapons, nudity). However, this raises a serious concern about the robustness of the employed AI algorithms against adversarial attacks. Indeed, some people may need to hide specific data to AI-based digital forensics tools, thus manipulating the content so that the AI system does not recognize the offensive/prohibited content and marks it at as suspicious to the analyst. This could be seen as an anti-forensics attack scenario. For this reason, we analyzed two of the most important forensics tools employing AI for data classification: Magnet AI, used by Magnet Axiom, and Excire Photo AI, used by X-Ways Forensics. We made preliminary tests using about $200$ images, other $100$ sent in $3$ chats about pornography and teenage nudity, drugs and weapons to understand how the tools label them. Moreover, we loaded some deepfake images (images generated by AI forging real ones) of some actors to understand if they would be classified in the same category as the original images. From our preliminary study, we saw that the AI algorithm is not robust enough, as we expected since these topics are still open research problems. For example, some sexual images were not categorized as nudity, and some deepfakes were categorized as the same real person, while the human eye can see the clear nudity image or catch the difference between the deepfakes. Building on these results and other state-of-the-art works, we provide some suggestions for improving how digital forensics analysis tool leverage AI and their robustness against adversarial attacks or different scenarios than the trained one.
Adversarial Pruning: A Survey and Benchmark of Pruning Methods for Adversarial Robustness
Sep 02, 2024Recent work has proposed neural network pruning techniques to reduce the size of a network while preserving robustness against adversarial examples, i.e., well-crafted inputs inducing a misclassification. These methods, which we refer to as adversarial pruning methods, involve complex and articulated designs, making it difficult to analyze the differences and establish a fair and accurate comparison. In this work, we overcome these issues by surveying current adversarial pruning methods and proposing a novel taxonomy to categorize them based on two main dimensions: the pipeline, defining when to prune; and the specifics, defining how to prune. We then highlight the limitations of current empirical analyses and propose a novel, fair evaluation benchmark to address them. We finally conduct an empirical re-evaluation of current adversarial pruning methods and discuss the results, highlighting the shared traits of top-performing adversarial pruning methods, as well as common issues. We welcome contributions in our publicly-available benchmark at https://github.com/pralab/AdversarialPruningBenchmark
HO-FMN: Hyperparameter Optimization for Fast Minimum-Norm Attacks
Jul 11, 2024



Gradient-based attacks are a primary tool to evaluate robustness of machine-learning models. However, many attacks tend to provide overly-optimistic evaluations as they use fixed loss functions, optimizers, step-size schedulers, and default hyperparameters. In this work, we tackle these limitations by proposing a parametric variation of the well-known fast minimum-norm attack algorithm, whose loss, optimizer, step-size scheduler, and hyperparameters can be dynamically adjusted. We re-evaluate 12 robust models, showing that our attack finds smaller adversarial perturbations without requiring any additional tuning. This also enables reporting adversarial robustness as a function of the perturbation budget, providing a more complete evaluation than that offered by fixed-budget attacks, while remaining efficient. We release our open-source code at https://github.com/pralab/HO-FMN.
Do Gradient-based Explanations Tell Anything About Adversarial Robustness to Android Malware?
May 04, 2020

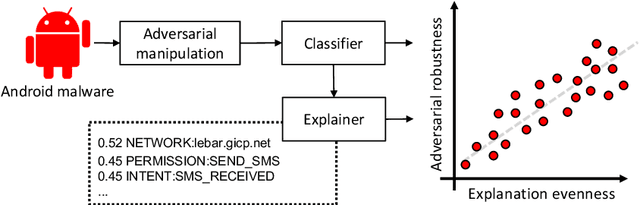
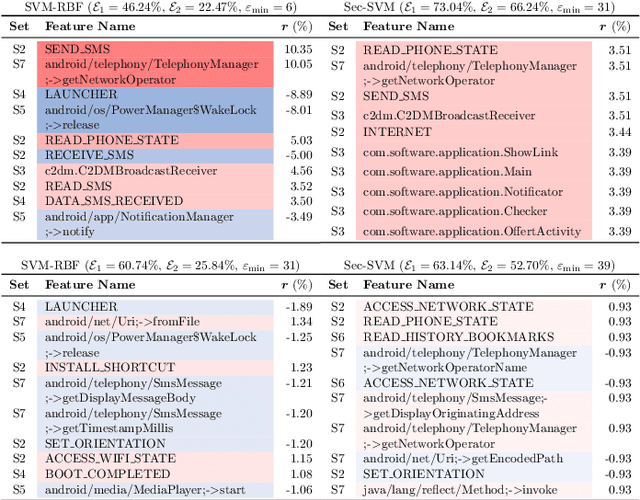
Machine-learning algorithms trained on features extracted from static code analysis can successfully detect Android malware. However, these approaches can be evaded by sparse evasion attacks that produce adversarial malware samples in which only few features are modified. This can be achieved, e.g., by injecting a small set of fake permissions and system calls into the malicious application, without compromising its intrusive functionality. To improve adversarial robustness against such sparse attacks, learning algorithms should avoid providing decisions which only rely upon a small subset of discriminant features; otherwise, even manipulating some of them may easily allow evading detection. Previous work showed that classifiers which avoid overemphasizing few discriminant features tend to be more robust against sparse attacks, and have developed simple metrics to help identify and select more robust algorithms. In this work, we aim to investigate whether gradient-based attribution methods used to explain classifiers' decisions by identifying the most relevant features can also be used to this end. Our intuition is that a classifier providing more uniform, evener attributions should rely upon a larger set of features, instead of overemphasizing few of them, thus being more robust against sparse attacks. We empirically investigate the connection between gradient-based explanations and adversarial robustness on a case study conducted on Android malware detection, and show that, in some cases, there is a strong correlation between the distribution of such explanations and adversarial robustness. We conclude the paper by discussing how our findings may thus enable the development of more efficient mechanisms both to evaluate and to improve adversarial robustness.
Poisoning Behavioral Malware Clustering
Nov 25, 2018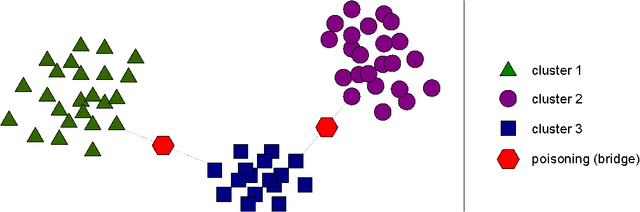

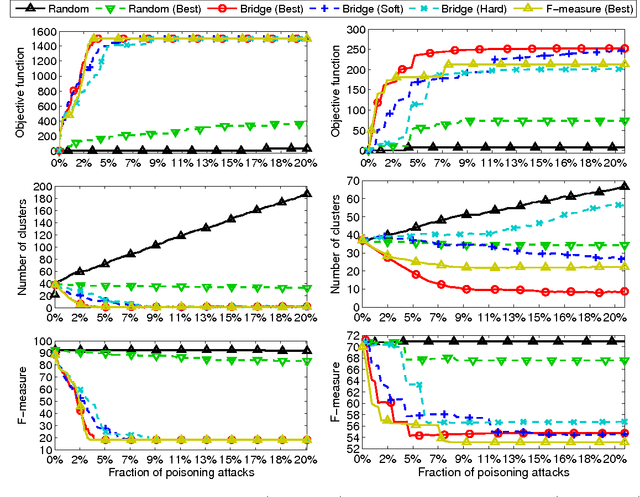
Clustering algorithms have become a popular tool in computer security to analyze the behavior of malware variants, identify novel malware families, and generate signatures for antivirus systems. However, the suitability of clustering algorithms for security-sensitive settings has been recently questioned by showing that they can be significantly compromised if an attacker can exercise some control over the input data. In this paper, we revisit this problem by focusing on behavioral malware clustering approaches, and investigate whether and to what extent an attacker may be able to subvert these approaches through a careful injection of samples with poisoning behavior. To this end, we present a case study on Malheur, an open-source tool for behavioral malware clustering. Our experiments not only demonstrate that this tool is vulnerable to poisoning attacks, but also that it can be significantly compromised even if the attacker can only inject a very small percentage of attacks into the input data. As a remedy, we discuss possible countermeasures and highlight the need for more secure clustering algorithms.
Explaining Black-box Android Malware Detection
Oct 29, 2018
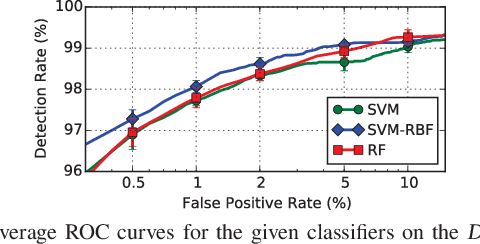
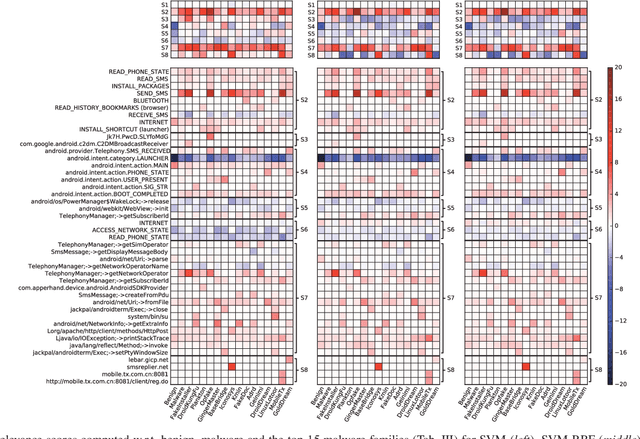

Machine-learning models have been recently used for detecting malicious Android applications, reporting impressive performances on benchmark datasets, even when trained only on features statically extracted from the application, such as system calls and permissions. However, recent findings have highlighted the fragility of such in-vitro evaluations with benchmark datasets, showing that very few changes to the content of Android malware may suffice to evade detection. How can we thus trust that a malware detector performing well on benchmark data will continue to do so when deployed in an operating environment? To mitigate this issue, the most popular Android malware detectors use linear, explainable machine-learning models to easily identify the most influential features contributing to each decision. In this work, we generalize this approach to any black-box machine- learning model, by leveraging a gradient-based approach to identify the most influential local features. This enables using nonlinear models to potentially increase accuracy without sacrificing interpretability of decisions. Our approach also highlights the global characteristics learned by the model to discriminate between benign and malware applications. Finally, as shown by our empirical analysis on a popular Android malware detection task, it also helps identifying potential vulnerabilities of linear and nonlinear models against adversarial manipulations.
Evasion Attacks against Machine Learning at Test Time
Aug 21, 2017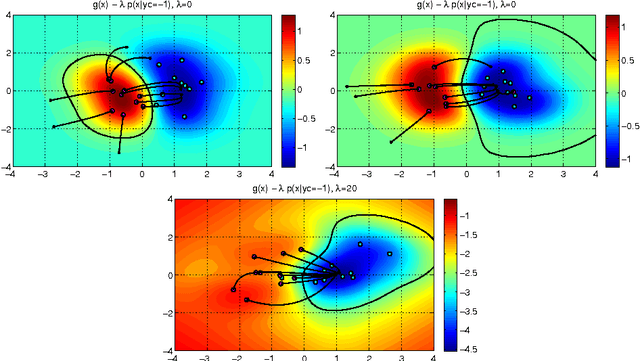
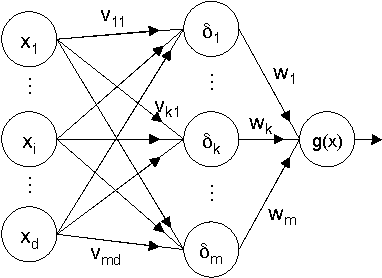
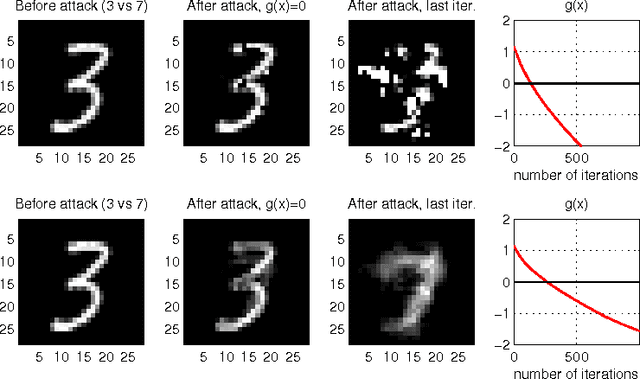
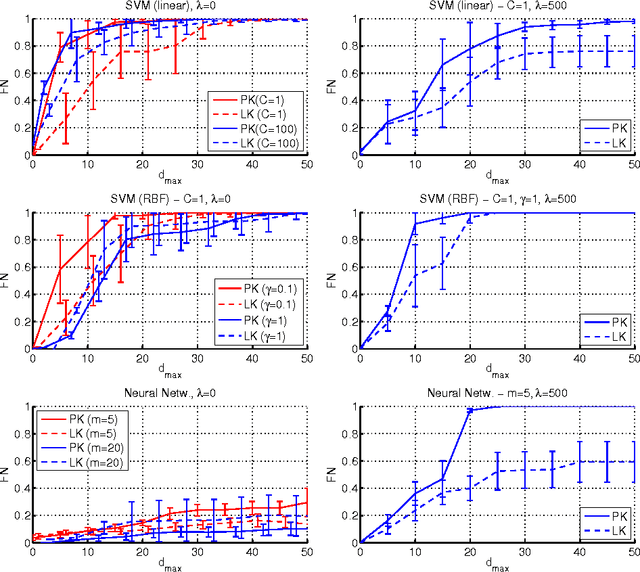
In security-sensitive applications, the success of machine learning depends on a thorough vetting of their resistance to adversarial data. In one pertinent, well-motivated attack scenario, an adversary may attempt to evade a deployed system at test time by carefully manipulating attack samples. In this work, we present a simple but effective gradient-based approach that can be exploited to systematically assess the security of several, widely-used classification algorithms against evasion attacks. Following a recently proposed framework for security evaluation, we simulate attack scenarios that exhibit different risk levels for the classifier by increasing the attacker's knowledge of the system and her ability to manipulate attack samples. This gives the classifier designer a better picture of the classifier performance under evasion attacks, and allows him to perform a more informed model selection (or parameter setting). We evaluate our approach on the relevant security task of malware detection in PDF files, and show that such systems can be easily evaded. We also sketch some countermeasures suggested by our analysis.
* In this paper, in 2013, we were the first to introduce the notion of evasion attacks (adversarial examples) created with high confidence (instead of minimum-distance misclassifications), and the notion of surrogate learners (substitute models). These two concepts are now widely re-used in developing attacks against deep networks (even if not always referring to the ideas reported in this work). arXiv admin note: text overlap with arXiv:1401.7727
Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification
Mar 10, 2016


Modern malware is designed with mutation characteristics, namely polymorphism and metamorphism, which causes an enormous growth in the number of variants of malware samples. Categorization of malware samples on the basis of their behaviors is essential for the computer security community, because they receive huge number of malware everyday, and the signature extraction process is usually based on malicious parts characterizing malware families. Microsoft released a malware classification challenge in 2015 with a huge dataset of near 0.5 terabytes of data, containing more than 20K malware samples. The analysis of this dataset inspired the development of a novel paradigm that is effective in categorizing malware variants into their actual family groups. This paradigm is presented and discussed in the present paper, where emphasis has been given to the phases related to the extraction, and selection of a set of novel features for the effective representation of malware samples. Features can be grouped according to different characteristics of malware behavior, and their fusion is performed according to a per-class weighting paradigm. The proposed method achieved a very high accuracy ($\approx$ 0.998) on the Microsoft Malware Challenge dataset.