 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial News and Lost Profits: Manipulating Headlines in LLM-Driven Algorithmic Trading
Jan 19, 2026Large Language Models (LLMs) are increasingly adopted in the financial domain. Their exceptional capabilities to analyse textual data make them well-suited for inferring the sentiment of finance-related news. Such feedback can be leveraged by algorithmic trading systems (ATS) to guide buy/sell decisions. However, this practice bears the risk that a threat actor may craft "adversarial news" intended to mislead an LLM. In particular, the news headline may include "malicious" content that remains invisible to human readers but which is still ingested by the LLM. Although prior work has studied textual adversarial examples, their system-wide impact on LLM-supported ATS has not yet been quantified in terms of monetary risk. To address this threat, we consider an adversary with no direct access to an ATS but able to alter stock-related news headlines on a single day. We evaluate two human-imperceptible manipulations in a financial context: Unicode homoglyph substitutions that misroute models during stock-name recognition, and hidden-text clauses that alter the sentiment of the news headline. We implement a realistic ATS in Backtrader that fuses an LSTM-based price forecast with LLM-derived sentiment (FinBERT, FinGPT, FinLLaMA, and six general-purpose LLMs), and quantify monetary impact using portfolio metrics. Experiments on real-world data show that manipulating a one-day attack over 14 months can reliably mislead LLMs and reduce annual returns by up to 17.7 percentage points. To assess real-world feasibility, we analyze popular scraping libraries and trading platforms and survey 27 FinTech practitioners, confirming our hypotheses. We notified trading platform owners of this security issue.
SoK: On the Offensive Potential of AI
Dec 24, 2024



Our society increasingly benefits from Artificial Intelligence (AI). Unfortunately, more and more evidence shows that AI is also used for offensive purposes. Prior works have revealed various examples of use cases in which the deployment of AI can lead to violation of security and privacy objectives. No extant work, however, has been able to draw a holistic picture of the offensive potential of AI. In this SoK paper we seek to lay the ground for a systematic analysis of the heterogeneous capabilities of offensive AI. In particular we (i) account for AI risks to both humans and systems while (ii) consolidating and distilling knowledge from academic literature, expert opinions, industrial venues, as well as laymen -- all of which being valuable sources of information on offensive AI. To enable alignment of such diverse sources of knowledge, we devise a common set of criteria reflecting essential technological factors related to offensive AI. With the help of such criteria, we systematically analyze: 95 research papers; 38 InfoSec briefings (from, e.g., BlackHat); the responses of a user study (N=549) entailing individuals with diverse backgrounds and expertise; and the opinion of 12 experts. Our contributions not only reveal concerning ways (some of which overlooked by prior work) in which AI can be offensively used today, but also represent a foothold to address this threat in the years to come.
Emerging Security Challenges of Large Language Models
Dec 23, 2024Large language models (LLMs) have achieved record adoption in a short period of time across many different sectors including high importance areas such as education [4] and healthcare [23]. LLMs are open-ended models trained on diverse data without being tailored for specific downstream tasks, enabling broad applicability across various domains. They are commonly used for text generation, but also widely used to assist with code generation [3], and even analysis of security information, as Microsoft Security Copilot demonstrates [18]. Traditional Machine Learning (ML) models are vulnerable to adversarial attacks [9]. So the concerns on the potential security implications of such wide scale adoption of LLMs have led to the creation of this working group on the security of LLMs. During the Dagstuhl seminar on "Network Attack Detection and Defense - AI-Powered Threats and Responses", the working group discussions focused on the vulnerability of LLMs to adversarial attacks, rather than their potential use in generating malware or enabling cyberattacks. Although we note the potential threat represented by the latter, the role of the LLMs in such uses is mostly as an accelerator for development, similar to what it is in benign use. To make the analysis more specific, the working group employed ChatGPT as a concrete example of an LLM and addressed the following points, which also form the structure of this report: 1. How do LLMs differ in vulnerabilities from traditional ML models? 2. What are the attack objectives in LLMs? 3. How complex it is to assess the risks posed by the vulnerabilities of LLMs? 4. What is the supply chain in LLMs, how data flow in and out of systems and what are the security implications? We conclude with an overview of open challenges and outlook.
SoK: Pragmatic Assessment of Machine Learning for Network Intrusion Detection
Apr 30, 2023Machine Learning (ML) has become a valuable asset to solve many real-world tasks. For Network Intrusion Detection (NID), however, scientific advances in ML are still seen with skepticism by practitioners. This disconnection is due to the intrinsically limited scope of research papers, many of which primarily aim to demonstrate new methods ``outperforming'' prior work -- oftentimes overlooking the practical implications for deploying the proposed solutions in real systems. Unfortunately, the value of ML for NID depends on a plethora of factors, such as hardware, that are often neglected in scientific literature. This paper aims to reduce the practitioners' skepticism towards ML for NID by "changing" the evaluation methodology adopted in research. After elucidating which "factors" influence the operational deployment of ML in NID, we propose the notion of "pragmatic assessment", which enable practitioners to gauge the real value of ML methods for NID. Then, we show that the state-of-research hardly allows one to estimate the value of ML for NID. As a constructive step forward, we carry out a pragmatic assessment. We re-assess existing ML methods for NID, focusing on the classification of malicious network traffic, and consider: hundreds of configuration settings; diverse adversarial scenarios; and four hardware platforms. Our large and reproducible evaluations enable estimating the quality of ML for NID. We also validate our claims through a user-study with security practitioners.
Wild Networks: Exposure of 5G Network Infrastructures to Adversarial Examples
Jul 04, 2022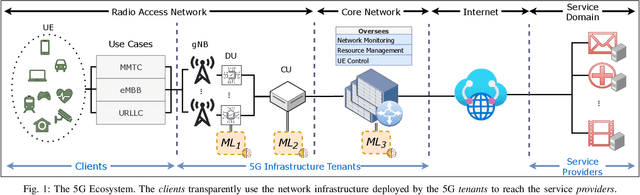
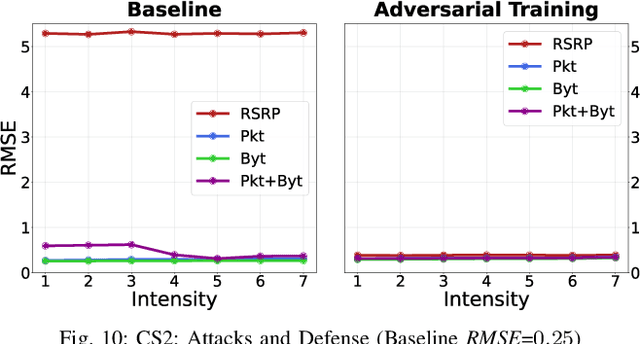
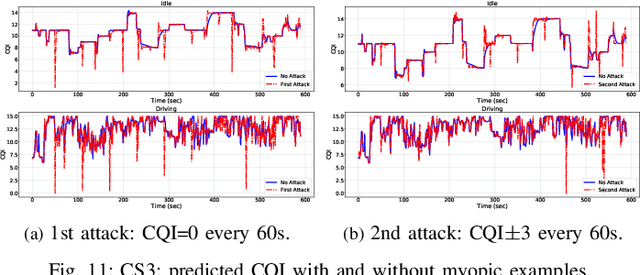
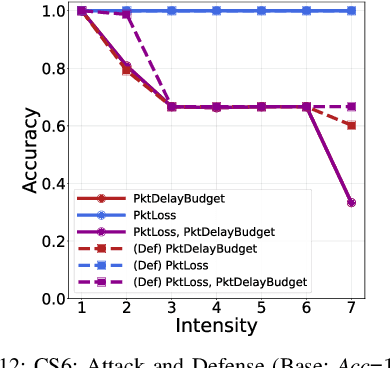
Fifth Generation (5G) networks must support billions of heterogeneous devices while guaranteeing optimal Quality of Service (QoS). Such requirements are impossible to meet with human effort alone, and Machine Learning (ML) represents a core asset in 5G. ML, however, is known to be vulnerable to adversarial examples; moreover, as our paper will show, the 5G context is exposed to a yet another type of adversarial ML attacks that cannot be formalized with existing threat models. Proactive assessment of such risks is also challenging due to the lack of ML-powered 5G equipment available for adversarial ML research. To tackle these problems, we propose a novel adversarial ML threat model that is particularly suited to 5G scenarios, and is agnostic to the precise function solved by ML. In contrast to existing ML threat models, our attacks do not require any compromise of the target 5G system while still being viable due to the QoS guarantees and the open nature of 5G networks. Furthermore, we propose an original framework for realistic ML security assessments based on public data. We proactively evaluate our threat model on 6 applications of ML envisioned in 5G. Our attacks affect both the training and the inference stages, can degrade the performance of state-of-the-art ML systems, and have a lower entry barrier than previous attacks.
The Role of Machine Learning in Cybersecurity
Jun 20, 2022

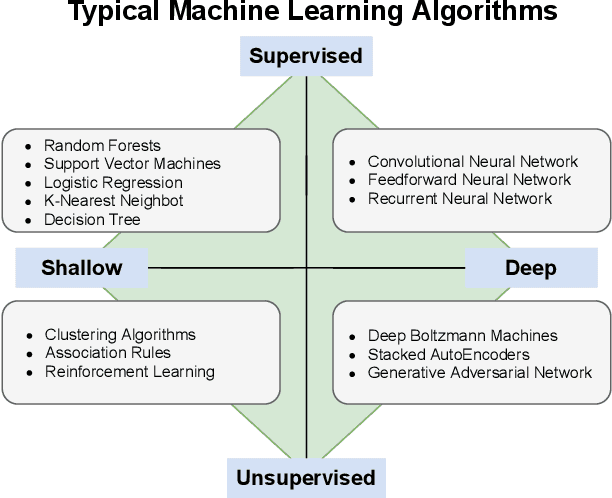
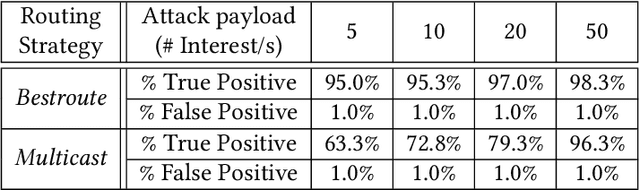
Machine Learning (ML) represents a pivotal technology for current and future information systems, and many domains already leverage the capabilities of ML. However, deployment of ML in cybersecurity is still at an early stage, revealing a significant discrepancy between research and practice. Such discrepancy has its root cause in the current state-of-the-art, which does not allow to identify the role of ML in cybersecurity. The full potential of ML will never be unleashed unless its pros and cons are understood by a broad audience. This paper is the first attempt to provide a holistic understanding of the role of ML in the entire cybersecurity domain -- to any potential reader with an interest in this topic. We highlight the advantages of ML with respect to human-driven detection methods, as well as the additional tasks that can be addressed by ML in cybersecurity. Moreover, we elucidate various intrinsic problems affecting real ML deployments in cybersecurity. Finally, we present how various stakeholders can contribute to future developments of ML in cybersecurity, which is essential for further progress in this field. Our contributions are complemented with two real case studies describing industrial applications of ML as defense against cyber-threats.
SoK: The Impact of Unlabelled Data in Cyberthreat Detection
May 18, 2022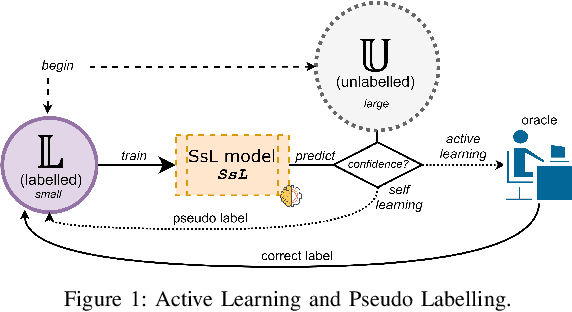
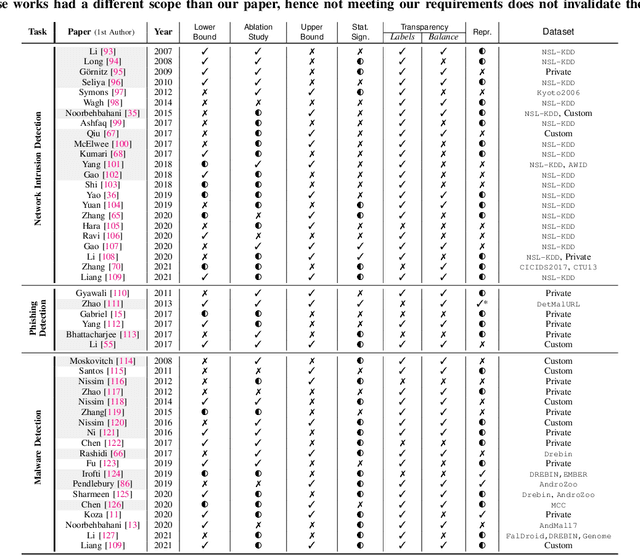
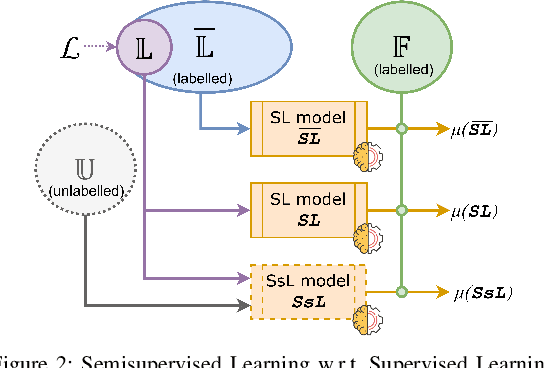
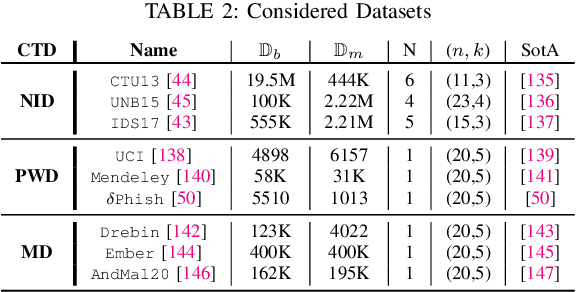
Machine learning (ML) has become an important paradigm for cyberthreat detection (CTD) in the recent years. A substantial research effort has been invested in the development of specialized algorithms for CTD tasks. From the operational perspective, however, the progress of ML-based CTD is hindered by the difficulty in obtaining the large sets of labelled data to train ML detectors. A potential solution to this problem are semisupervised learning (SsL) methods, which combine small labelled datasets with large amounts of unlabelled data. This paper is aimed at systematization of existing work on SsL for CTD and, in particular, on understanding the utility of unlabelled data in such systems. To this end, we analyze the cost of labelling in various CTD tasks and develop a formal cost model for SsL in this context. Building on this foundation, we formalize a set of requirements for evaluation of SsL methods, which elucidates the contribution of unlabelled data. We review the state-of-the-art and observe that no previous work meets such requirements. To address this problem, we propose a framework for assessing the benefits of unlabelled data in SsL. We showcase an application of this framework by performing the first benchmark evaluation that highlights the tradeoffs of 9 existing SsL methods on 9 public datasets. Our findings verify that, in some cases, unlabelled data provides a small, but statistically significant, performance gain. This paper highlights that SsL in CTD has a lot of room for improvement, which should stimulate future research in this field.
Evasion Attacks against Machine Learning at Test Time
Aug 21, 2017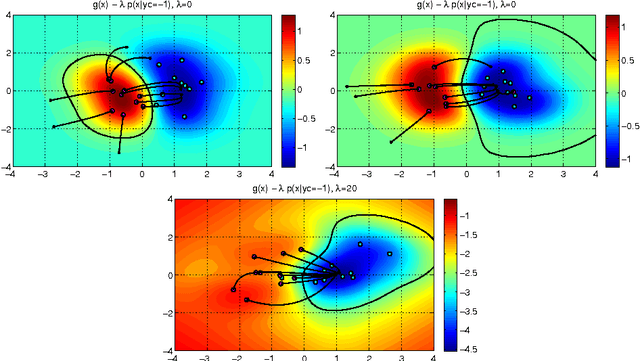
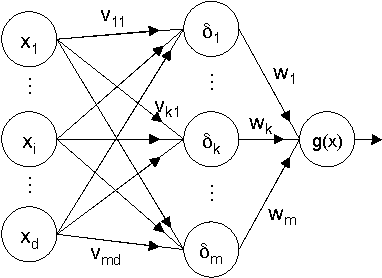
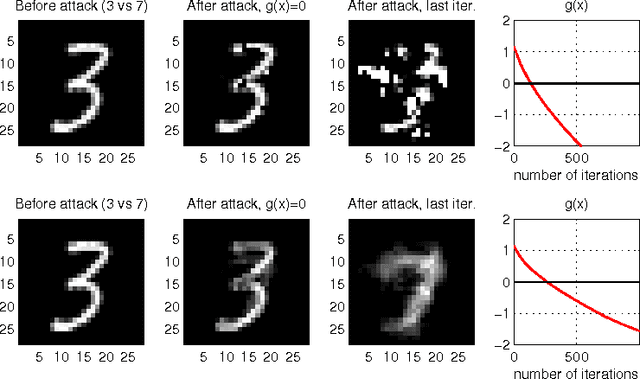
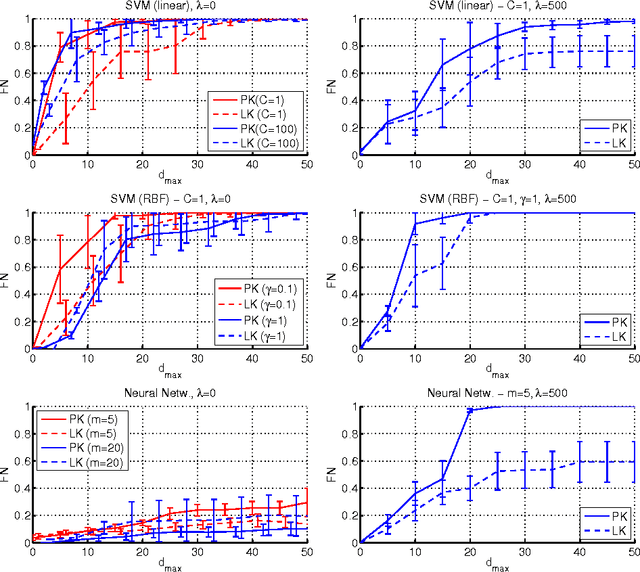
In security-sensitive applications, the success of machine learning depends on a thorough vetting of their resistance to adversarial data. In one pertinent, well-motivated attack scenario, an adversary may attempt to evade a deployed system at test time by carefully manipulating attack samples. In this work, we present a simple but effective gradient-based approach that can be exploited to systematically assess the security of several, widely-used classification algorithms against evasion attacks. Following a recently proposed framework for security evaluation, we simulate attack scenarios that exhibit different risk levels for the classifier by increasing the attacker's knowledge of the system and her ability to manipulate attack samples. This gives the classifier designer a better picture of the classifier performance under evasion attacks, and allows him to perform a more informed model selection (or parameter setting). We evaluate our approach on the relevant security task of malware detection in PDF files, and show that such systems can be easily evaded. We also sketch some countermeasures suggested by our analysis.
* In this paper, in 2013, we were the first to introduce the notion of evasion attacks (adversarial examples) created with high confidence (instead of minimum-distance misclassifications), and the notion of surrogate learners (substitute models). These two concepts are now widely re-used in developing attacks against deep networks (even if not always referring to the ideas reported in this work). arXiv admin note: text overlap with arXiv:1401.7727
Poisoning Attacks against Support Vector Machines
Mar 25, 2013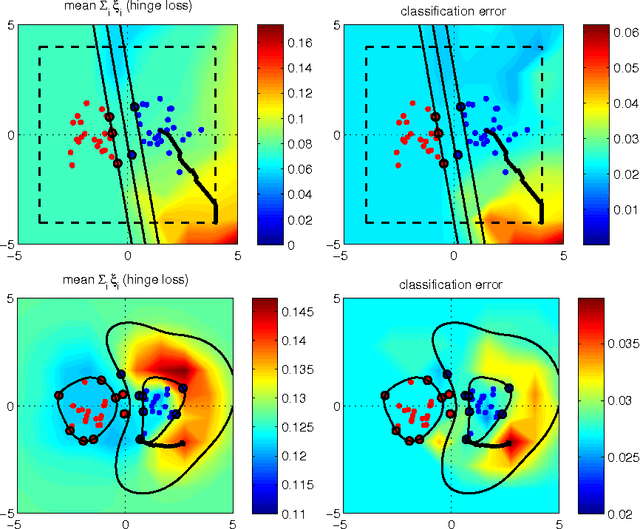
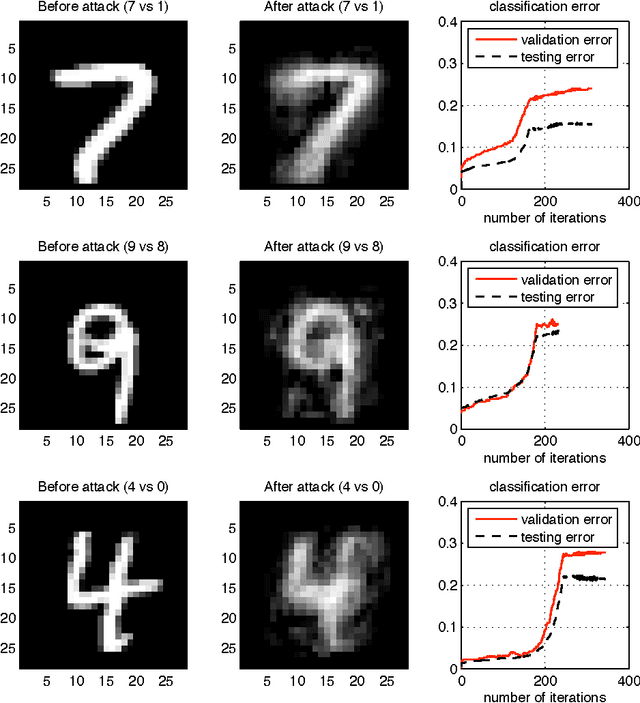
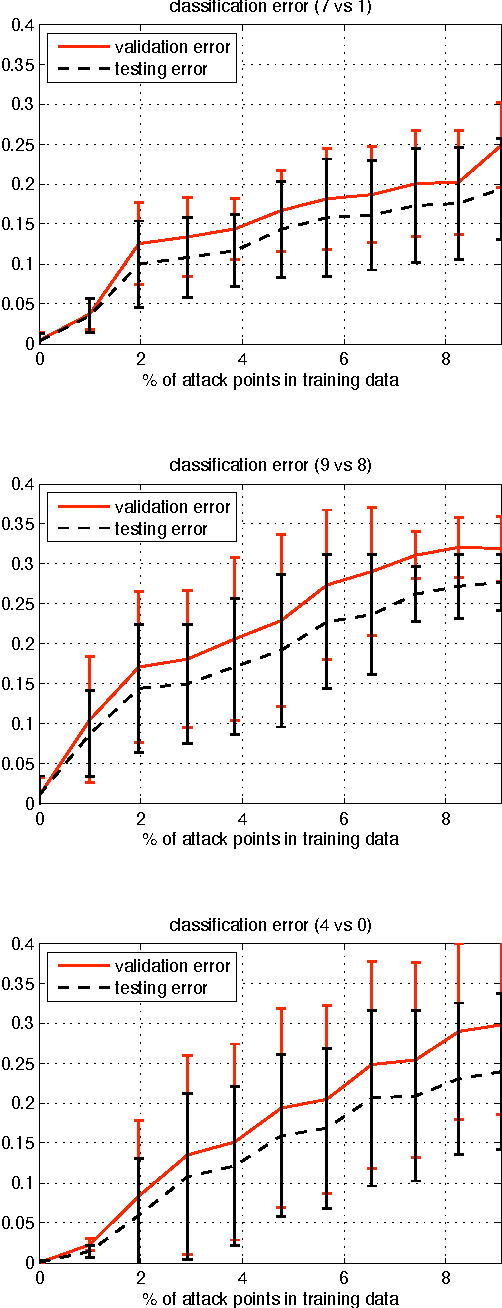
We investigate a family of poisoning attacks against Support Vector Machines (SVM). Such attacks inject specially crafted training data that increases the SVM's test error. Central to the motivation for these attacks is the fact that most learning algorithms assume that their training data comes from a natural or well-behaved distribution. However, this assumption does not generally hold in security-sensitive settings. As we demonstrate, an intelligent adversary can, to some extent, predict the change of the SVM's decision function due to malicious input and use this ability to construct malicious data. The proposed attack uses a gradient ascent strategy in which the gradient is computed based on properties of the SVM's optimal solution. This method can be kernelized and enables the attack to be constructed in the input space even for non-linear kernels. We experimentally demonstrate that our gradient ascent procedure reliably identifies good local maxima of the non-convex validation error surface, which significantly increases the classifier's test error.
Security Analysis of Online Centroid Anomaly Detection
Feb 27, 2010



Security issues are crucial in a number of machine learning applications, especially in scenarios dealing with human activity rather than natural phenomena (e.g., information ranking, spam detection, malware detection, etc.). It is to be expected in such cases that learning algorithms will have to deal with manipulated data aimed at hampering decision making. Although some previous work addressed the handling of malicious data in the context of supervised learning, very little is known about the behavior of anomaly detection methods in such scenarios. In this contribution we analyze the performance of a particular method -- online centroid anomaly detection -- in the presence of adversarial noise. Our analysis addresses the following security-related issues: formalization of learning and attack processes, derivation of an optimal attack, analysis of its efficiency and constraints. We derive bounds on the effectiveness of a poisoning attack against centroid anomaly under different conditions: bounded and unbounded percentage of traffic, and bounded false positive rate. Our bounds show that whereas a poisoning attack can be effectively staged in the unconstrained case, it can be made arbitrarily difficult (a strict upper bound on the attacker's gain) if external constraints are properly used. Our experimental evaluation carried out on real HTTP and exploit traces confirms the tightness of our theoretical bounds and practicality of our protection mechanisms.