 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial News and Lost Profits: Manipulating Headlines in LLM-Driven Algorithmic Trading
Jan 19, 2026Large Language Models (LLMs) are increasingly adopted in the financial domain. Their exceptional capabilities to analyse textual data make them well-suited for inferring the sentiment of finance-related news. Such feedback can be leveraged by algorithmic trading systems (ATS) to guide buy/sell decisions. However, this practice bears the risk that a threat actor may craft "adversarial news" intended to mislead an LLM. In particular, the news headline may include "malicious" content that remains invisible to human readers but which is still ingested by the LLM. Although prior work has studied textual adversarial examples, their system-wide impact on LLM-supported ATS has not yet been quantified in terms of monetary risk. To address this threat, we consider an adversary with no direct access to an ATS but able to alter stock-related news headlines on a single day. We evaluate two human-imperceptible manipulations in a financial context: Unicode homoglyph substitutions that misroute models during stock-name recognition, and hidden-text clauses that alter the sentiment of the news headline. We implement a realistic ATS in Backtrader that fuses an LSTM-based price forecast with LLM-derived sentiment (FinBERT, FinGPT, FinLLaMA, and six general-purpose LLMs), and quantify monetary impact using portfolio metrics. Experiments on real-world data show that manipulating a one-day attack over 14 months can reliably mislead LLMs and reduce annual returns by up to 17.7 percentage points. To assess real-world feasibility, we analyze popular scraping libraries and trading platforms and survey 27 FinTech practitioners, confirming our hypotheses. We notified trading platform owners of this security issue.
SoK: On the Offensive Potential of AI
Dec 24, 2024



Our society increasingly benefits from Artificial Intelligence (AI). Unfortunately, more and more evidence shows that AI is also used for offensive purposes. Prior works have revealed various examples of use cases in which the deployment of AI can lead to violation of security and privacy objectives. No extant work, however, has been able to draw a holistic picture of the offensive potential of AI. In this SoK paper we seek to lay the ground for a systematic analysis of the heterogeneous capabilities of offensive AI. In particular we (i) account for AI risks to both humans and systems while (ii) consolidating and distilling knowledge from academic literature, expert opinions, industrial venues, as well as laymen -- all of which being valuable sources of information on offensive AI. To enable alignment of such diverse sources of knowledge, we devise a common set of criteria reflecting essential technological factors related to offensive AI. With the help of such criteria, we systematically analyze: 95 research papers; 38 InfoSec briefings (from, e.g., BlackHat); the responses of a user study (N=549) entailing individuals with diverse backgrounds and expertise; and the opinion of 12 experts. Our contributions not only reveal concerning ways (some of which overlooked by prior work) in which AI can be offensively used today, but also represent a foothold to address this threat in the years to come.
Machine Learning in Space: Surveying the Robustness of on-board ML models to Radiation
May 04, 2024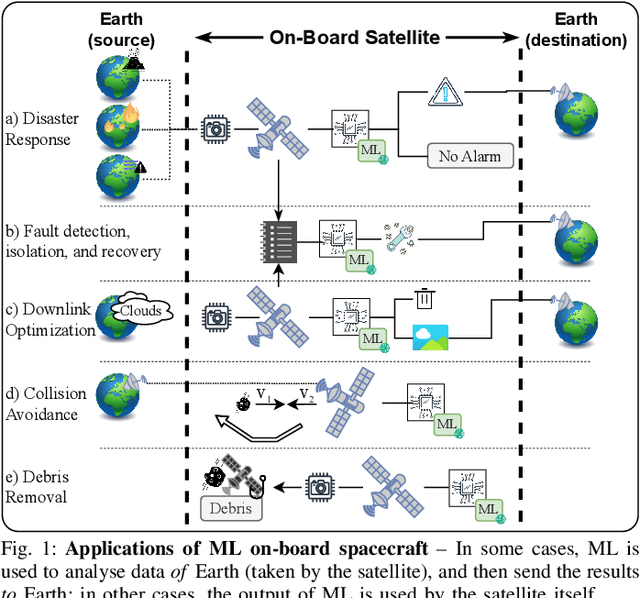


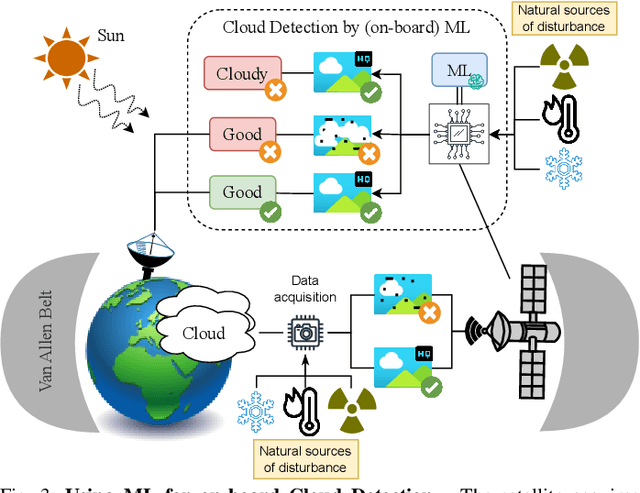
Modern spacecraft are increasingly relying on machine learning (ML). However, physical equipment in space is subject to various natural hazards, such as radiation, which may inhibit the correct operation of computing devices. Despite plenty of evidence showing the damage that naturally-induced faults can cause to ML-related hardware, we observe that the effects of radiation on ML models for space applications are not well-studied. This is a problem: without understanding how ML models are affected by these natural phenomena, it is uncertain "where to start from" to develop radiation-tolerant ML software. As ML researchers, we attempt to tackle this dilemma. By partnering up with space-industry practitioners specialized in ML, we perform a reflective analysis of the state of the art. We provide factual evidence that prior work did not thoroughly examine the impact of natural hazards on ML models meant for spacecraft. Then, through a "negative result", we show that some existing open-source technologies can hardly be used by researchers to study the effects of radiation for some applications of ML in satellites. As a constructive step forward, we perform simple experiments showcasing how to leverage current frameworks to assess the robustness of practical ML models for cloud detection against radiation-induced faults. Our evaluation reveals that not all faults are as devastating as claimed by some prior work. By publicly releasing our resources, we provide a foothold -- usable by researchers without access to spacecraft -- for spearheading development of space-tolerant ML models.
SoK: Pragmatic Assessment of Machine Learning for Network Intrusion Detection
Apr 30, 2023Machine Learning (ML) has become a valuable asset to solve many real-world tasks. For Network Intrusion Detection (NID), however, scientific advances in ML are still seen with skepticism by practitioners. This disconnection is due to the intrinsically limited scope of research papers, many of which primarily aim to demonstrate new methods ``outperforming'' prior work -- oftentimes overlooking the practical implications for deploying the proposed solutions in real systems. Unfortunately, the value of ML for NID depends on a plethora of factors, such as hardware, that are often neglected in scientific literature. This paper aims to reduce the practitioners' skepticism towards ML for NID by "changing" the evaluation methodology adopted in research. After elucidating which "factors" influence the operational deployment of ML in NID, we propose the notion of "pragmatic assessment", which enable practitioners to gauge the real value of ML methods for NID. Then, we show that the state-of-research hardly allows one to estimate the value of ML for NID. As a constructive step forward, we carry out a pragmatic assessment. We re-assess existing ML methods for NID, focusing on the classification of malicious network traffic, and consider: hundreds of configuration settings; diverse adversarial scenarios; and four hardware platforms. Our large and reproducible evaluations enable estimating the quality of ML for NID. We also validate our claims through a user-study with security practitioners.
"Real Attackers Don't Compute Gradients": Bridging the Gap Between Adversarial ML Research and Practice
Dec 29, 2022
Recent years have seen a proliferation of research on adversarial machine learning. Numerous papers demonstrate powerful algorithmic attacks against a wide variety of machine learning (ML) models, and numerous other papers propose defenses that can withstand most attacks. However, abundant real-world evidence suggests that actual attackers use simple tactics to subvert ML-driven systems, and as a result security practitioners have not prioritized adversarial ML defenses. Motivated by the apparent gap between researchers and practitioners, this position paper aims to bridge the two domains. We first present three real-world case studies from which we can glean practical insights unknown or neglected in research. Next we analyze all adversarial ML papers recently published in top security conferences, highlighting positive trends and blind spots. Finally, we state positions on precise and cost-driven threat modeling, collaboration between industry and academia, and reproducible research. We believe that our positions, if adopted, will increase the real-world impact of future endeavours in adversarial ML, bringing both researchers and practitioners closer to their shared goal of improving the security of ML systems.
Mitigating Adversarial Gray-Box Attacks Against Phishing Detectors
Dec 11, 2022



Although machine learning based algorithms have been extensively used for detecting phishing websites, there has been relatively little work on how adversaries may attack such "phishing detectors" (PDs for short). In this paper, we propose a set of Gray-Box attacks on PDs that an adversary may use which vary depending on the knowledge that he has about the PD. We show that these attacks severely degrade the effectiveness of several existing PDs. We then propose the concept of operation chains that iteratively map an original set of features to a new set of features and develop the "Protective Operation Chain" (POC for short) algorithm. POC leverages the combination of random feature selection and feature mappings in order to increase the attacker's uncertainty about the target PD. Using 3 existing publicly available datasets plus a fourth that we have created and will release upon the publication of this paper, we show that POC is more robust to these attacks than past competing work, while preserving predictive performance when no adversarial attacks are present. Moreover, POC is robust to attacks on 13 different classifiers, not just one. These results are shown to be statistically significant at the p < 0.001 level.
SpacePhish: The Evasion-space of Adversarial Attacks against Phishing Website Detectors using Machine Learning
Oct 24, 2022Existing literature on adversarial Machine Learning (ML) focuses either on showing attacks that break every ML model, or defenses that withstand most attacks. Unfortunately, little consideration is given to the actual \textit{cost} of the attack or the defense. Moreover, adversarial samples are often crafted in the "feature-space", making the corresponding evaluations of questionable value. Simply put, the current situation does not allow to estimate the actual threat posed by adversarial attacks, leading to a lack of secure ML systems. We aim to clarify such confusion in this paper. By considering the application of ML for Phishing Website Detection (PWD), we formalize the "evasion-space" in which an adversarial perturbation can be introduced to fool a ML-PWD -- demonstrating that even perturbations in the "feature-space" are useful. Then, we propose a realistic threat model describing evasion attacks against ML-PWD that are cheap to stage, and hence intrinsically more attractive for real phishers. Finally, we perform the first statistically validated assessment of state-of-the-art ML-PWD against 12 evasion attacks. Our evaluation shows (i) the true efficacy of evasion attempts that are more likely to occur; and (ii) the impact of perturbations crafted in different evasion-spaces. Our realistic evasion attempts induce a statistically significant degradation (3-10% at $p\!<$0.05), and their cheap cost makes them a subtle threat. Notably, however, some ML-PWD are immune to our most realistic attacks ($p$=0.22). Our contribution paves the way for a much needed re-assessment of adversarial attacks against ML systems for cybersecurity.
Attribute Inference Attacks in Online Multiplayer Video Games: a Case Study on Dota2
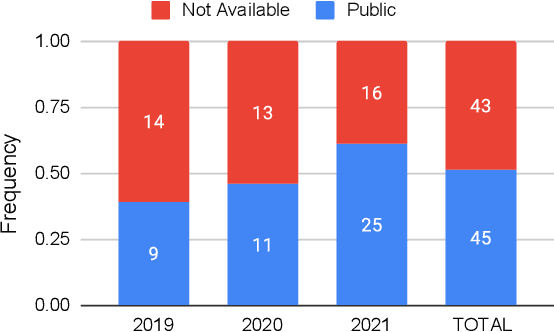
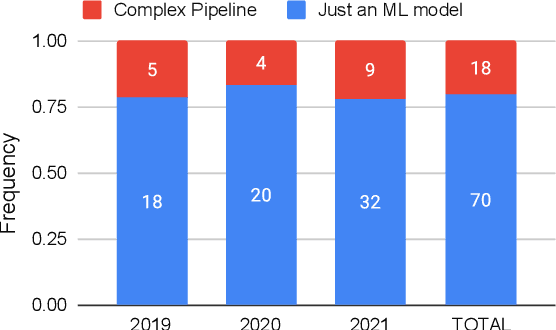
Oct 17, 2022
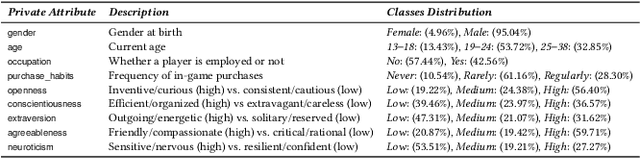
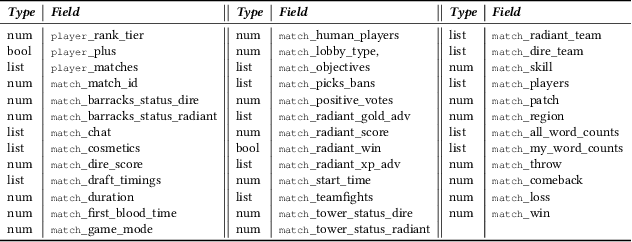
Did you know that over 70 million of Dota2 players have their in-game data freely accessible? What if such data is used in malicious ways? This paper is the first to investigate such a problem. Motivated by the widespread popularity of video games, we propose the first threat model for Attribute Inference Attacks (AIA) in the Dota2 context. We explain how (and why) attackers can exploit the abundant public data in the Dota2 ecosystem to infer private information about its players. Due to lack of concrete evidence on the efficacy of our AIA, we empirically prove and assess their impact in reality. By conducting an extensive survey on $\sim$500 Dota2 players spanning over 26k matches, we verify whether a correlation exists between a player's Dota2 activity and their real-life. Then, after finding such a link ($p\!<\!0.01$ and $\rho>0.3$), we ethically perform diverse AIA. We leverage the capabilities of machine learning to infer real-life attributes of the respondents of our survey by using their publicly available in-game data. Our results show that, by applying domain expertise, some AIA can reach up to 98% precision and over 90% accuracy. This paper hence raises the alarm on a subtle, but concrete threat that can potentially affect the entire competitive gaming landscape. We alerted the developers of Dota2.
Wild Networks: Exposure of 5G Network Infrastructures to Adversarial Examples
Jul 04, 2022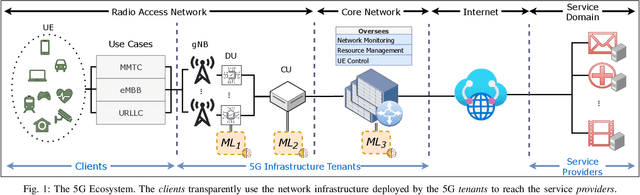
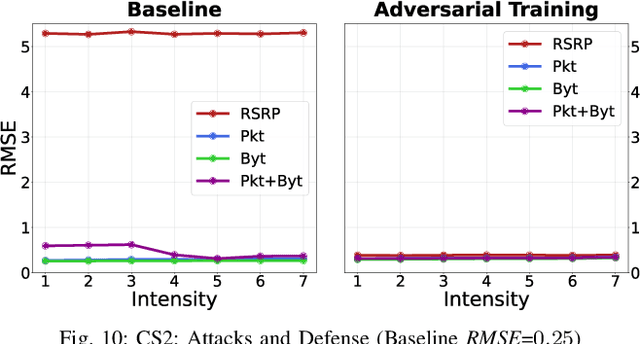
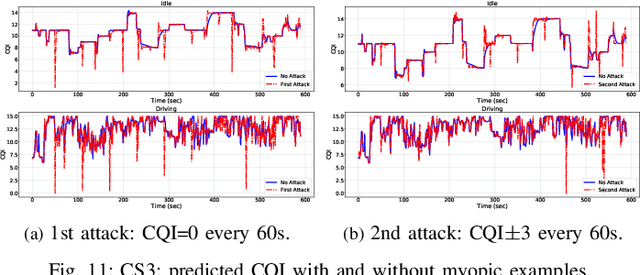
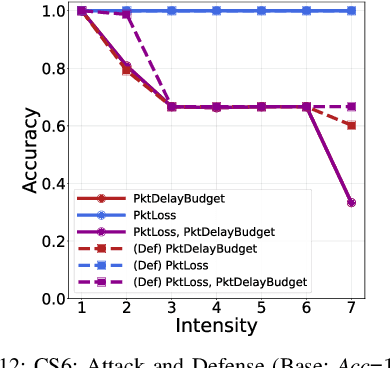
Fifth Generation (5G) networks must support billions of heterogeneous devices while guaranteeing optimal Quality of Service (QoS). Such requirements are impossible to meet with human effort alone, and Machine Learning (ML) represents a core asset in 5G. ML, however, is known to be vulnerable to adversarial examples; moreover, as our paper will show, the 5G context is exposed to a yet another type of adversarial ML attacks that cannot be formalized with existing threat models. Proactive assessment of such risks is also challenging due to the lack of ML-powered 5G equipment available for adversarial ML research. To tackle these problems, we propose a novel adversarial ML threat model that is particularly suited to 5G scenarios, and is agnostic to the precise function solved by ML. In contrast to existing ML threat models, our attacks do not require any compromise of the target 5G system while still being viable due to the QoS guarantees and the open nature of 5G networks. Furthermore, we propose an original framework for realistic ML security assessments based on public data. We proactively evaluate our threat model on 6 applications of ML envisioned in 5G. Our attacks affect both the training and the inference stages, can degrade the performance of state-of-the-art ML systems, and have a lower entry barrier than previous attacks.
The Role of Machine Learning in Cybersecurity
Jun 20, 2022

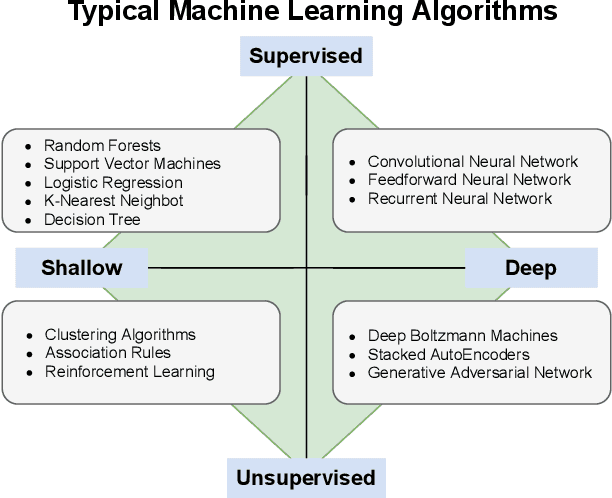
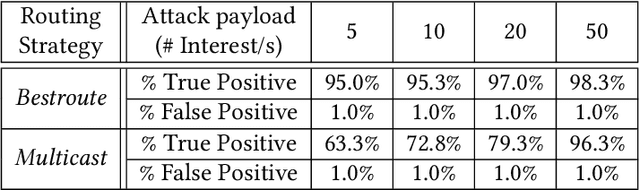
Machine Learning (ML) represents a pivotal technology for current and future information systems, and many domains already leverage the capabilities of ML. However, deployment of ML in cybersecurity is still at an early stage, revealing a significant discrepancy between research and practice. Such discrepancy has its root cause in the current state-of-the-art, which does not allow to identify the role of ML in cybersecurity. The full potential of ML will never be unleashed unless its pros and cons are understood by a broad audience. This paper is the first attempt to provide a holistic understanding of the role of ML in the entire cybersecurity domain -- to any potential reader with an interest in this topic. We highlight the advantages of ML with respect to human-driven detection methods, as well as the additional tasks that can be addressed by ML in cybersecurity. Moreover, we elucidate various intrinsic problems affecting real ML deployments in cybersecurity. Finally, we present how various stakeholders can contribute to future developments of ML in cybersecurity, which is essential for further progress in this field. Our contributions are complemented with two real case studies describing industrial applications of ML as defense against cyber-threats.