 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"All of Me": Mining Users' Attributes from their Public Spotify Playlists
Jan 25, 2024In the age of digital music streaming, playlists on platforms like Spotify have become an integral part of individuals' musical experiences. People create and publicly share their own playlists to express their musical tastes, promote the discovery of their favorite artists, and foster social connections. These publicly accessible playlists transcend the boundaries of mere musical preferences: they serve as sources of rich insights into users' attributes and identities. For example, the musical preferences of elderly individuals may lean more towards Frank Sinatra, while Billie Eilish remains a favored choice among teenagers. These playlists thus become windows into the diverse and evolving facets of one's musical identity. In this work, we investigate the relationship between Spotify users' attributes and their public playlists. In particular, we focus on identifying recurring musical characteristics associated with users' individual attributes, such as demographics, habits, or personality traits. To this end, we conducted an online survey involving 739 Spotify users, yielding a dataset of 10,286 publicly shared playlists encompassing over 200,000 unique songs and 55,000 artists. Through extensive statistical analyses, we first assess a deep connection between a user's Spotify playlists and their real-life attributes. For instance, we found individuals high in openness often create playlists featuring a diverse array of artists, while female users prefer Pop and K-pop music genres. Building upon these observed associations, we create accurate predictive models for users' attributes, presenting a novel DeepSet application that outperforms baselines in most of these users' attributes.
Social Honeypot for Humans: Luring People through Self-managed Instagram Pages
Mar 31, 2023



Social Honeypots are tools deployed in Online Social Networks (OSN) to attract malevolent activities performed by spammers and bots. To this end, their content is designed to be of maximum interest to malicious users. However, by choosing an appropriate content topic, this attractive mechanism could be extended to any OSN users, rather than only luring malicious actors. As a result, honeypots can be used to attract individuals interested in a wide range of topics, from sports and hobbies to more sensitive subjects like political views and conspiracies. With all these individuals gathered in one place, honeypot owners can conduct many analyses, from social to marketing studies. In this work, we introduce a novel concept of social honeypot for attracting OSN users interested in a generic target topic. We propose a framework based on fully-automated content generation strategies and engagement plans to mimic legit Instagram pages. To validate our framework, we created 21 self-managed social honeypots (i.e., pages) on Instagram, covering three topics, four content generation strategies, and three engaging plans. In nine weeks, our honeypots gathered a total of 753 followers, 5387 comments, and 15739 likes. These results demonstrate the validity of our approach, and through statistical analysis, we examine the characteristics of effective social honeypots.
Follow Us and Become Famous! Insights and Guidelines From Instagram Engagement Mechanisms
Jan 17, 2023



With 1.3 billion users, Instagram (IG) has also become a business tool. IG influencer marketing, expected to generate $33.25 billion in 2022, encourages companies and influencers to create trending content. Various methods have been proposed for predicting a post's popularity, i.e., how much engagement (e.g., Likes) it will generate. However, these methods are limited: first, they focus on forecasting the likes, ignoring the number of comments, which became crucial in 2021. Secondly, studies often use biased or limited data. Third, researchers focused on Deep Learning models to increase predictive performance, which are difficult to interpret. As a result, end-users can only estimate engagement after a post is created, which is inefficient and expensive. A better approach is to generate a post based on what people and IG like, e.g., by following guidelines. In this work, we uncover part of the underlying mechanisms driving IG engagement. To achieve this goal, we rely on statistical analysis and interpretable models rather than Deep Learning (black-box) approaches. We conduct extensive experiments using a worldwide dataset of 10 million posts created by 34K global influencers in nine different categories. With our simple yet powerful algorithms, we can predict engagement up to 94% of F1-Score, making us comparable and even superior to Deep Learning-based method. Furthermore, we propose a novel unsupervised algorithm for finding highly engaging topics on IG. Thanks to our interpretable approaches, we conclude by outlining guidelines for creating successful posts.
Attribute Inference Attacks in Online Multiplayer Video Games: a Case Study on Dota2
Oct 17, 2022
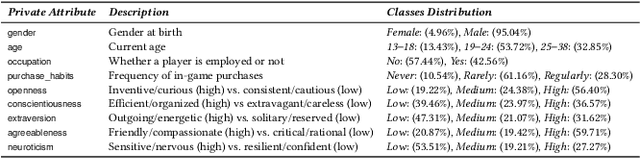
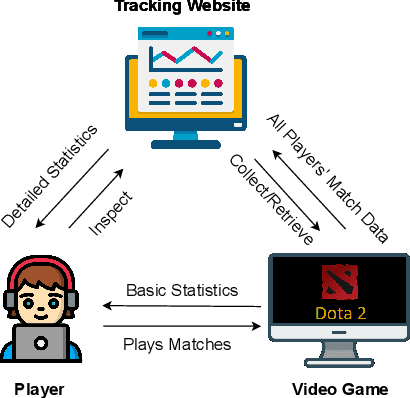
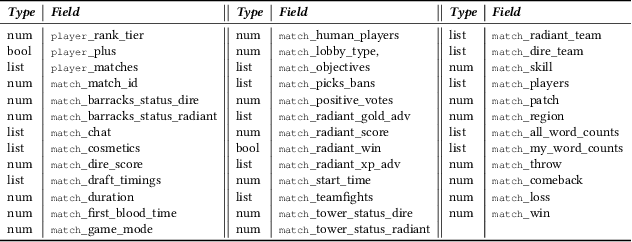
Did you know that over 70 million of Dota2 players have their in-game data freely accessible? What if such data is used in malicious ways? This paper is the first to investigate such a problem. Motivated by the widespread popularity of video games, we propose the first threat model for Attribute Inference Attacks (AIA) in the Dota2 context. We explain how (and why) attackers can exploit the abundant public data in the Dota2 ecosystem to infer private information about its players. Due to lack of concrete evidence on the efficacy of our AIA, we empirically prove and assess their impact in reality. By conducting an extensive survey on $\sim$500 Dota2 players spanning over 26k matches, we verify whether a correlation exists between a player's Dota2 activity and their real-life. Then, after finding such a link ($p\!<\!0.01$ and $\rho>0.3$), we ethically perform diverse AIA. We leverage the capabilities of machine learning to infer real-life attributes of the respondents of our survey by using their publicly available in-game data. Our results show that, by applying domain expertise, some AIA can reach up to 98% precision and over 90% accuracy. This paper hence raises the alarm on a subtle, but concrete threat that can potentially affect the entire competitive gaming landscape. We alerted the developers of Dota2.
Thermal (and Hybrid Thermal/Audio) Side-Channel Attacks on Keyboard Input
Oct 05, 2022



To date, there has been no systematic investigation of thermal profiles of keyboards, and thus no efforts have been made to secure them. This serves as our main motivation for constructing a means for password harvesting from keyboard thermal emanations. Specifically, we introduce Thermanator: a new post-factum insider attack based on heat transfer caused by a user typing a password on a typical external (plastic) keyboard. We conduct and describe a user study that collected thermal residues from 30 users entering 10 unique passwords (both weak and strong) on 4 popular commodity keyboards. Results show that entire sets of key-presses can be recovered by non-expert users as late as 30 seconds after initial password entry, while partial sets can be recovered as late as 1 minute after entry. However, the thermal residue side-channel lacks information about password length, duplicate key-presses, and key-press ordering. To overcome these limitations, we leverage keyboard acoustic emanations and combine the two to yield AcuTherm, the first hybrid side-channel attack on keyboards. AcuTherm significantly reduces password search without the need for any training on the victim's typing. We report results gathered for many representative passwords based on a user study involving 19 subjects. The takeaway of this work is three-fold: (1) using plastic keyboards to enter secrets (such as passwords and PINs) is even less secure than previously recognized, (2) post-factum thermal imaging attacks are realistic, and (3) hybrid (multiple side-channel) attacks are both realistic and effective.
Captcha Attack: Turning Captchas Against Humanity
Jan 13, 2022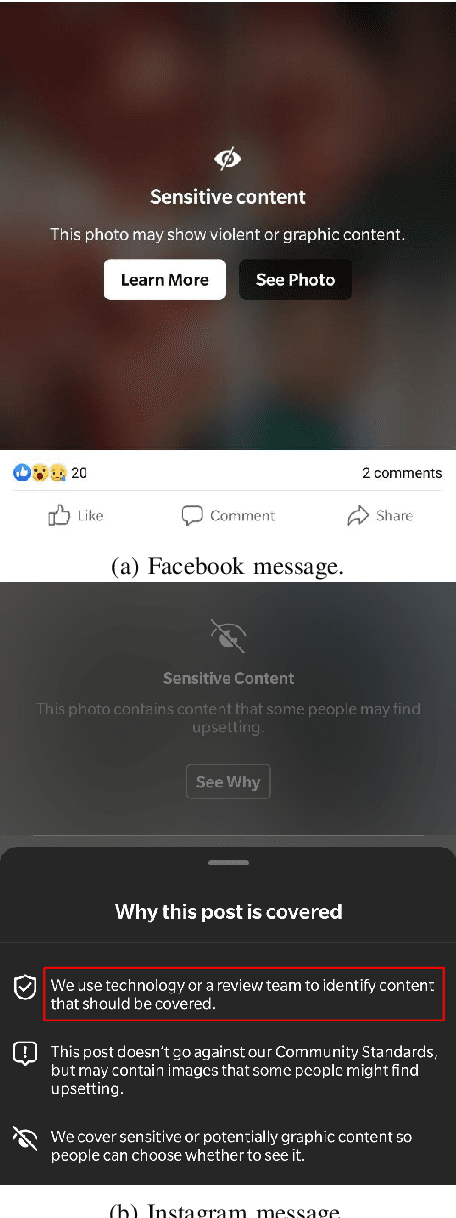


Nowadays, people generate and share massive content on online platforms (e.g., social networks, blogs). In 2021, the 1.9 billion daily active Facebook users posted around 150 thousand photos every minute. Content moderators constantly monitor these online platforms to prevent the spreading of inappropriate content (e.g., hate speech, nudity images). Based on deep learning (DL) advances, Automatic Content Moderators (ACM) help human moderators handle high data volume. Despite their advantages, attackers can exploit weaknesses of DL components (e.g., preprocessing, model) to affect their performance. Therefore, an attacker can leverage such techniques to spread inappropriate content by evading ACM. In this work, we propose CAPtcha Attack (CAPA), an adversarial technique that allows users to spread inappropriate text online by evading ACM controls. CAPA, by generating custom textual CAPTCHAs, exploits ACM's careless design implementations and internal procedures vulnerabilities. We test our attack on real-world ACM, and the results confirm the ferocity of our simple yet effective attack, reaching up to a 100% evasion success in most cases. At the same time, we demonstrate the difficulties in designing CAPA mitigations, opening new challenges in CAPTCHAs research area.