 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptcha Attack: Turning Captchas Against Humanity
Paper and Code
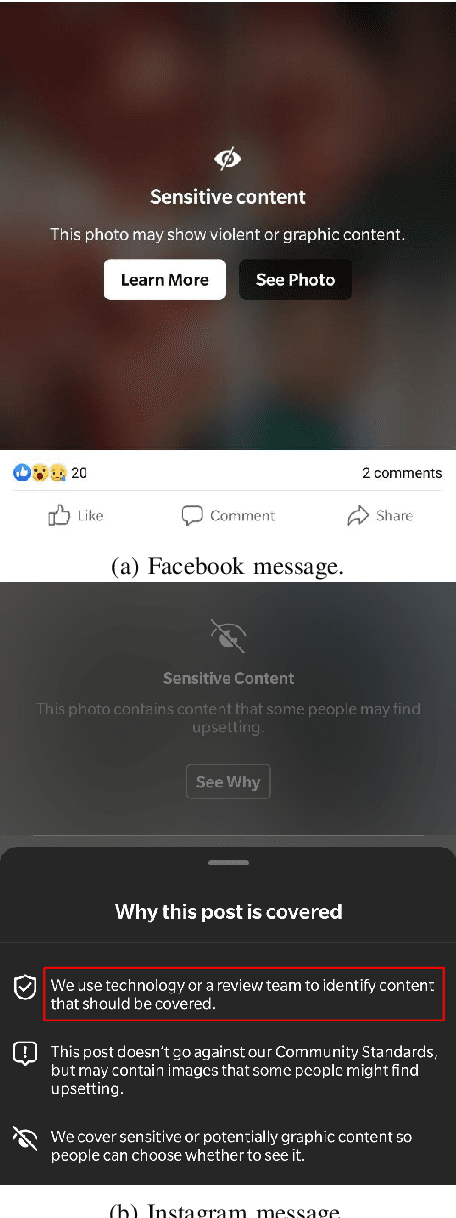


Nowadays, people generate and share massive content on online platforms (e.g., social networks, blogs). In 2021, the 1.9 billion daily active Facebook users posted around 150 thousand photos every minute. Content moderators constantly monitor these online platforms to prevent the spreading of inappropriate content (e.g., hate speech, nudity images). Based on deep learning (DL) advances, Automatic Content Moderators (ACM) help human moderators handle high data volume. Despite their advantages, attackers can exploit weaknesses of DL components (e.g., preprocessing, model) to affect their performance. Therefore, an attacker can leverage such techniques to spread inappropriate content by evading ACM. In this work, we propose CAPtcha Attack (CAPA), an adversarial technique that allows users to spread inappropriate text online by evading ACM controls. CAPA, by generating custom textual CAPTCHAs, exploits ACM's careless design implementations and internal procedures vulnerabilities. We test our attack on real-world ACM, and the results confirm the ferocity of our simple yet effective attack, reaching up to a 100% evasion success in most cases. At the same time, we demonstrate the difficulties in designing CAPA mitigations, opening new challenges in CAPTCHAs research area.