 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalma: Learning to See Memory Corruption in WebAssembly
Mar 25, 2026WebAssembly's (Wasm) monolithic linear memory model facilitates memory corruption attacks that can escalate to cross-site scripting in browsers or go undetected when a malicious host tampers with a module's state. Existing defenses rely on invasive binary instrumentation or custom runtimes, and do not address runtime integrity verification under an adversarial host model. We present Walma, a framework for WebAssembly Linear Memory Attestation that leverages machine learning to detect memory corruption and external tampering by classifying memory snapshots. We evaluate Walma on six real-world CVE-affected applications across three verification backends (cpu-wasm, cpu-tch, gpu) and three instrumentation policies. Our results demonstrate that CNN-based classification can effectively detect memory corruption in applications with structured memory layouts, with coarse-grained boundary checks incurring as low as 1.07x overhead, while fine-grained monitoring introduces higher (1.5x--1.8x) but predictable costs. Our evaluation quantifies the accuracy and overhead trade-offs across deployment configurations, demonstrating the practical feasibility of ML-based memory attestation for WebAssembly.
NeST: Neuron Selective Tuning for LLM Safety
Feb 18, 2026Safety alignment is essential for the responsible deployment of large language models (LLMs). Yet, existing approaches often rely on heavyweight fine-tuning that is costly to update, audit, and maintain across model families. Full fine-tuning incurs substantial computational and storage overhead, while parameter-efficient methods such as LoRA trade efficiency for inconsistent safety gains and sensitivity to design choices. Safety intervention mechanisms such as circuit breakers reduce unsafe outputs without modifying model weights, but do not directly shape or preserve the internal representations that govern safety behavior. These limitations hinder rapid and reliable safety updates, particularly in settings where models evolve frequently or must adapt to new policies and domains. We present NeST, a lightweight, structure-aware safety alignment framework that strengthens refusal behavior by selectively adapting a small subset of safety-relevant neurons while freezing the remainder of the model. NeST aligns parameter updates with the internal organization of safety behavior by clustering functionally coherent safety neurons and enforcing shared updates within each cluster, enabling targeted and stable safety adaptation without broad model modification or inference-time overhead. We benchmark NeST against three dominant baselines: full fine-tuning, LoRA-based fine-tuning, and circuit breakers across 10 open-weight LLMs spanning multiple model families and sizes. Across all evaluated models, NeST reduces the attack success rate from an average of 44.5% to 4.36%, corresponding to a 90.2% reduction in unsafe generations, while requiring only 0.44 million trainable parameters on average. This amounts to a 17,310x decrease in updated parameters compared to full fine-tuning and a 9.25x reduction relative to LoRA, while consistently achieving stronger safety performance for alignment.
SafeSplit: A Novel Defense Against Client-Side Backdoor Attacks in Split Learning
Jan 11, 2025
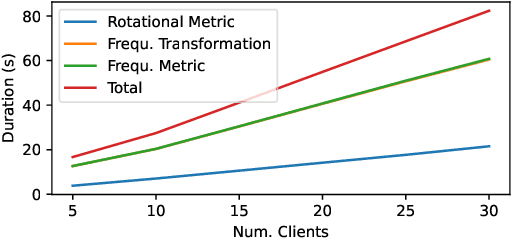
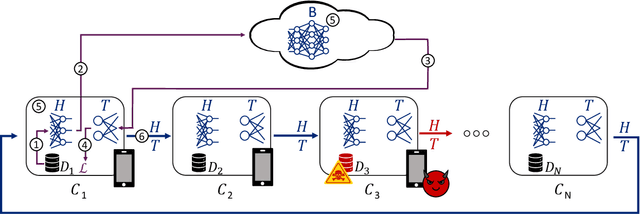
Split Learning (SL) is a distributed deep learning approach enabling multiple clients and a server to collaboratively train and infer on a shared deep neural network (DNN) without requiring clients to share their private local data. The DNN is partitioned in SL, with most layers residing on the server and a few initial layers and inputs on the client side. This configuration allows resource-constrained clients to participate in training and inference. However, the distributed architecture exposes SL to backdoor attacks, where malicious clients can manipulate local datasets to alter the DNN's behavior. Existing defenses from other distributed frameworks like Federated Learning are not applicable, and there is a lack of effective backdoor defenses specifically designed for SL. We present SafeSplit, the first defense against client-side backdoor attacks in Split Learning (SL). SafeSplit enables the server to detect and filter out malicious client behavior by employing circular backward analysis after a client's training is completed, iteratively reverting to a trained checkpoint where the model under examination is found to be benign. It uses a two-fold analysis to identify client-induced changes and detect poisoned models. First, a static analysis in the frequency domain measures the differences in the layer's parameters at the server. Second, a dynamic analysis introduces a novel rotational distance metric that assesses the orientation shifts of the server's layer parameters during training. Our comprehensive evaluation across various data distributions, client counts, and attack scenarios demonstrates the high efficacy of this dual analysis in mitigating backdoor attacks while preserving model utility.
Beyond Random Inputs: A Novel ML-Based Hardware Fuzzing
Apr 10, 2024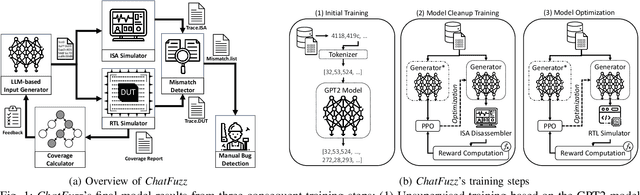
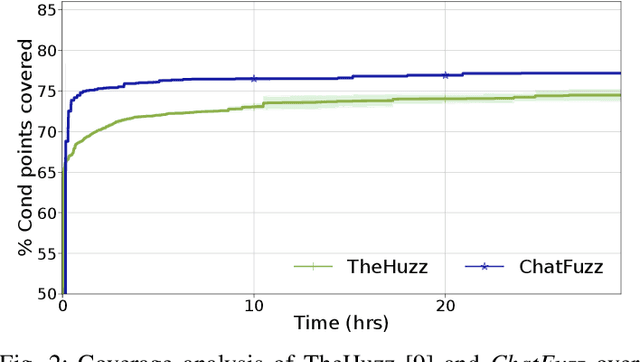
Modern computing systems heavily rely on hardware as the root of trust. However, their increasing complexity has given rise to security-critical vulnerabilities that cross-layer at-tacks can exploit. Traditional hardware vulnerability detection methods, such as random regression and formal verification, have limitations. Random regression, while scalable, is slow in exploring hardware, and formal verification techniques are often concerned with manual effort and state explosions. Hardware fuzzing has emerged as an effective approach to exploring and detecting security vulnerabilities in large-scale designs like modern processors. They outperform traditional methods regarding coverage, scalability, and efficiency. However, state-of-the-art fuzzers struggle to achieve comprehensive coverage of intricate hardware designs within a practical timeframe, often falling short of a 70% coverage threshold. We propose a novel ML-based hardware fuzzer, ChatFuzz, to address this challenge. Ourapproach leverages LLMs like ChatGPT to understand processor language, focusing on machine codes and generating assembly code sequences. RL is integrated to guide the input generation process by rewarding the inputs using code coverage metrics. We use the open-source RISCV-based RocketCore processor as our testbed. ChatFuzz achieves condition coverage rate of 75% in just 52 minutes compared to a state-of-the-art fuzzer, which requires a lengthy 30-hour window to reach a similar condition coverage. Furthermore, our fuzzer can attain 80% coverage when provided with a limited pool of 10 simulation instances/licenses within a 130-hour window. During this time, it conducted a total of 199K test cases, of which 6K produced discrepancies with the processor's golden model. Our analysis identified more than 10 unique mismatches, including two new bugs in the RocketCore and discrepancies from the RISC-V ISA Simulator.
One for All and All for One: GNN-based Control-Flow Attestation for Embedded Devices
Mar 12, 2024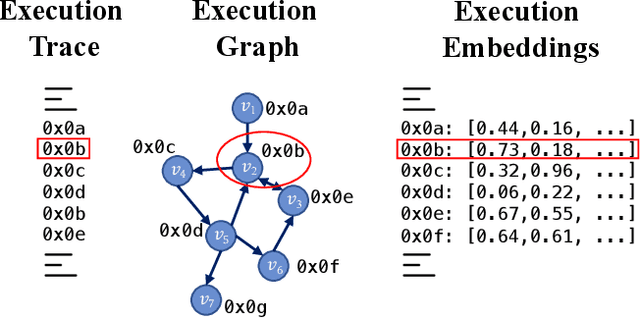



Control-Flow Attestation (CFA) is a security service that allows an entity (verifier) to verify the integrity of code execution on a remote computer system (prover). Existing CFA schemes suffer from impractical assumptions, such as requiring access to the prover's internal state (e.g., memory or code), the complete Control-Flow Graph (CFG) of the prover's software, large sets of measurements, or tailor-made hardware. Moreover, current CFA schemes are inadequate for attesting embedded systems due to their high computational overhead and resource usage. In this paper, we overcome the limitations of existing CFA schemes for embedded devices by introducing RAGE, a novel, lightweight CFA approach with minimal requirements. RAGE can detect Code Reuse Attacks (CRA), including control- and non-control-data attacks. It efficiently extracts features from one execution trace and leverages Unsupervised Graph Neural Networks (GNNs) to identify deviations from benign executions. The core intuition behind RAGE is to exploit the correspondence between execution trace, execution graph, and execution embeddings to eliminate the unrealistic requirement of having access to a complete CFG. We evaluate RAGE on embedded benchmarks and demonstrate that (i) it detects 40 real-world attacks on embedded software; (ii) Further, we stress our scheme with synthetic return-oriented programming (ROP) and data-oriented programming (DOP) attacks on the real-world embedded software benchmark Embench, achieving 98.03% (ROP) and 91.01% (DOP) F1-Score while maintaining a low False Positive Rate of 3.19%; (iii) Additionally, we evaluate RAGE on OpenSSL, used by millions of devices and achieve 97.49% and 84.42% F1-Score for ROP and DOP attack detection, with an FPR of 5.47%.
DeepEclipse: How to Break White-Box DNN-Watermarking Schemes
Mar 06, 2024Deep Learning (DL) models have become crucial in digital transformation, thus raising concerns about their intellectual property rights. Different watermarking techniques have been developed to protect Deep Neural Networks (DNNs) from IP infringement, creating a competitive field for DNN watermarking and removal methods. The predominant watermarking schemes use white-box techniques, which involve modifying weights by adding a unique signature to specific DNN layers. On the other hand, existing attacks on white-box watermarking usually require knowledge of the specific deployed watermarking scheme or access to the underlying data for further training and fine-tuning. We propose DeepEclipse, a novel and unified framework designed to remove white-box watermarks. We present obfuscation techniques that significantly differ from the existing white-box watermarking removal schemes. DeepEclipse can evade watermark detection without prior knowledge of the underlying watermarking scheme, additional data, or training and fine-tuning. Our evaluation reveals that DeepEclipse excels in breaking multiple white-box watermarking schemes, reducing watermark detection to random guessing while maintaining a similar model accuracy as the original one. Our framework showcases a promising solution to address the ongoing DNN watermark protection and removal challenges.
FreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
DEMASQ: Unmasking the ChatGPT Wordsmith
Nov 08, 2023
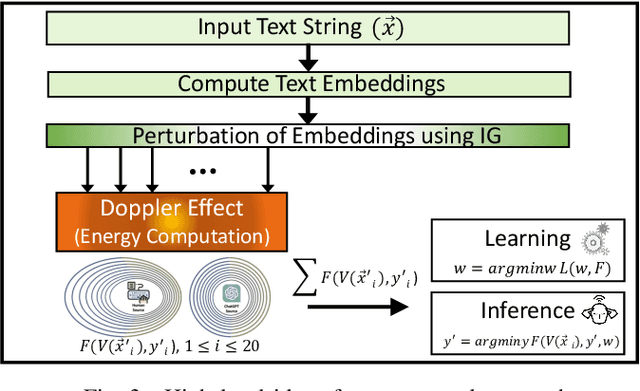

The potential misuse of ChatGPT and other Large Language Models (LLMs) has raised concerns regarding the dissemination of false information, plagiarism, academic dishonesty, and fraudulent activities. Consequently, distinguishing between AI-generated and human-generated content has emerged as an intriguing research topic. However, current text detection methods lack precision and are often restricted to specific tasks or domains, making them inadequate for identifying content generated by ChatGPT. In this paper, we propose an effective ChatGPT detector named DEMASQ, which accurately identifies ChatGPT-generated content. Our method addresses two critical factors: (i) the distinct biases in text composition observed in human- and machine-generated content and (ii) the alterations made by humans to evade previous detection methods. DEMASQ is an energy-based detection model that incorporates novel aspects, such as (i) optimization inspired by the Doppler effect to capture the interdependence between input text embeddings and output labels, and (ii) the use of explainable AI techniques to generate diverse perturbations. To evaluate our detector, we create a benchmark dataset comprising a mixture of prompts from both ChatGPT and humans, encompassing domains such as medical, open Q&A, finance, wiki, and Reddit. Our evaluation demonstrates that DEMASQ achieves high accuracy in identifying content generated by ChatGPT.
To ChatGPT, or not to ChatGPT: That is the question!
Apr 05, 2023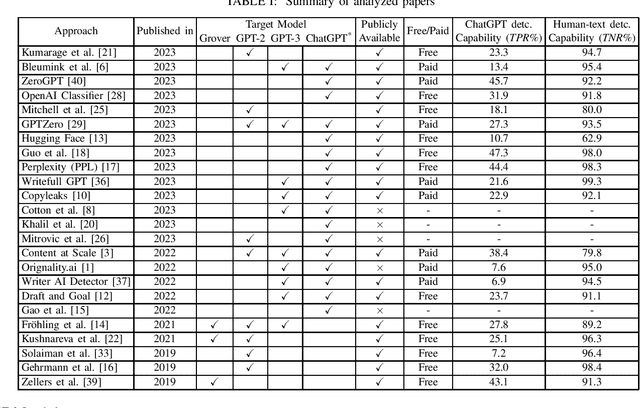
ChatGPT has become a global sensation. As ChatGPT and other Large Language Models (LLMs) emerge, concerns of misusing them in various ways increase, such as disseminating fake news, plagiarism, manipulating public opinion, cheating, and fraud. Hence, distinguishing AI-generated from human-generated becomes increasingly essential. Researchers have proposed various detection methodologies, ranging from basic binary classifiers to more complex deep-learning models. Some detection techniques rely on statistical characteristics or syntactic patterns, while others incorporate semantic or contextual information to improve accuracy. The primary objective of this study is to provide a comprehensive and contemporary assessment of the most recent techniques in ChatGPT detection. Additionally, we evaluated other AI-generated text detection tools that do not specifically claim to detect ChatGPT-generated content to assess their performance in detecting ChatGPT-generated content. For our evaluation, we have curated a benchmark dataset consisting of prompts from ChatGPT and humans, including diverse questions from medical, open Q&A, and finance domains and user-generated responses from popular social networking platforms. The dataset serves as a reference to assess the performance of various techniques in detecting ChatGPT-generated content. Our evaluation results demonstrate that none of the existing methods can effectively detect ChatGPT-generated content.
ARGUS: Context-Based Detection of Stealthy IoT Infiltration Attacks
Feb 16, 2023IoT application domains, device diversity and connectivity are rapidly growing. IoT devices control various functions in smart homes and buildings, smart cities, and smart factories, making these devices an attractive target for attackers. On the other hand, the large variability of different application scenarios and inherent heterogeneity of devices make it very challenging to reliably detect abnormal IoT device behaviors and distinguish these from benign behaviors. Existing approaches for detecting attacks are mostly limited to attacks directly compromising individual IoT devices, or, require predefined detection policies. They cannot detect attacks that utilize the control plane of the IoT system to trigger actions in an unintended/malicious context, e.g., opening a smart lock while the smart home residents are absent. In this paper, we tackle this problem and propose ARGUS, the first self-learning intrusion detection system for detecting contextual attacks on IoT environments, in which the attacker maliciously invokes IoT device actions to reach its goals. ARGUS monitors the contextual setting based on the state and actions of IoT devices in the environment. An unsupervised Deep Neural Network (DNN) is used for modeling the typical contextual device behavior and detecting actions taking place in abnormal contextual settings. This unsupervised approach ensures that ARGUS is not restricted to detecting previously known attacks but is also able to detect new attacks. We evaluated ARGUS on heterogeneous real-world smart-home settings and achieve at least an F1-Score of 99.64% for each setup, with a false positive rate (FPR) of at most 0.03%.