 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
DEMASQ: Unmasking the ChatGPT Wordsmith
Nov 08, 2023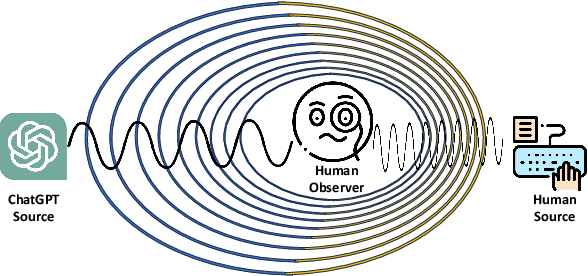
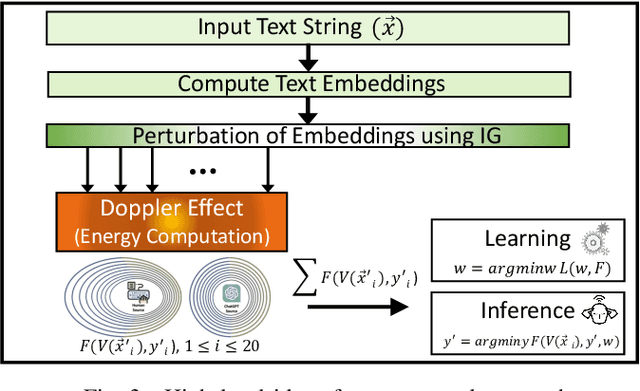

The potential misuse of ChatGPT and other Large Language Models (LLMs) has raised concerns regarding the dissemination of false information, plagiarism, academic dishonesty, and fraudulent activities. Consequently, distinguishing between AI-generated and human-generated content has emerged as an intriguing research topic. However, current text detection methods lack precision and are often restricted to specific tasks or domains, making them inadequate for identifying content generated by ChatGPT. In this paper, we propose an effective ChatGPT detector named DEMASQ, which accurately identifies ChatGPT-generated content. Our method addresses two critical factors: (i) the distinct biases in text composition observed in human- and machine-generated content and (ii) the alterations made by humans to evade previous detection methods. DEMASQ is an energy-based detection model that incorporates novel aspects, such as (i) optimization inspired by the Doppler effect to capture the interdependence between input text embeddings and output labels, and (ii) the use of explainable AI techniques to generate diverse perturbations. To evaluate our detector, we create a benchmark dataset comprising a mixture of prompts from both ChatGPT and humans, encompassing domains such as medical, open Q&A, finance, wiki, and Reddit. Our evaluation demonstrates that DEMASQ achieves high accuracy in identifying content generated by ChatGPT.
FLEDGE: Ledger-based Federated Learning Resilient to Inference and Backdoor Attacks
Oct 03, 2023



Federated learning (FL) is a distributed learning process that uses a trusted aggregation server to allow multiple parties (or clients) to collaboratively train a machine learning model without having them share their private data. Recent research, however, has demonstrated the effectiveness of inference and poisoning attacks on FL. Mitigating both attacks simultaneously is very challenging. State-of-the-art solutions have proposed the use of poisoning defenses with Secure Multi-Party Computation (SMPC) and/or Differential Privacy (DP). However, these techniques are not efficient and fail to address the malicious intent behind the attacks, i.e., adversaries (curious servers and/or compromised clients) seek to exploit a system for monetization purposes. To overcome these limitations, we present a ledger-based FL framework known as FLEDGE that allows making parties accountable for their behavior and achieve reasonable efficiency for mitigating inference and poisoning attacks. Our solution leverages crypto-currency to increase party accountability by penalizing malicious behavior and rewarding benign conduct. We conduct an extensive evaluation on four public datasets: Reddit, MNIST, Fashion-MNIST, and CIFAR-10. Our experimental results demonstrate that (1) FLEDGE provides strong privacy guarantees for model updates without sacrificing model utility; (2) FLEDGE can successfully mitigate different poisoning attacks without degrading the performance of the global model; and (3) FLEDGE offers unique reward mechanisms to promote benign behavior during model training and/or model aggregation.
To ChatGPT, or not to ChatGPT: That is the question!
Apr 05, 2023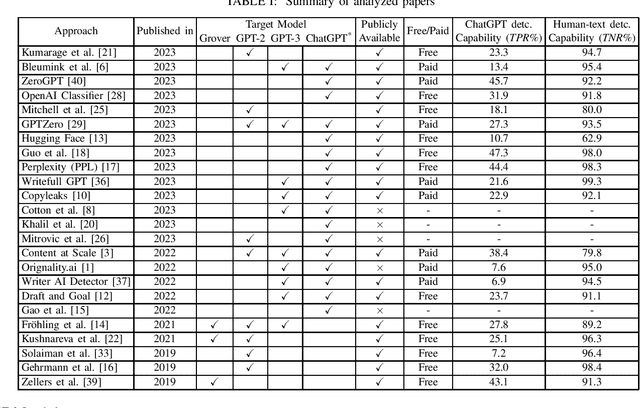
ChatGPT has become a global sensation. As ChatGPT and other Large Language Models (LLMs) emerge, concerns of misusing them in various ways increase, such as disseminating fake news, plagiarism, manipulating public opinion, cheating, and fraud. Hence, distinguishing AI-generated from human-generated becomes increasingly essential. Researchers have proposed various detection methodologies, ranging from basic binary classifiers to more complex deep-learning models. Some detection techniques rely on statistical characteristics or syntactic patterns, while others incorporate semantic or contextual information to improve accuracy. The primary objective of this study is to provide a comprehensive and contemporary assessment of the most recent techniques in ChatGPT detection. Additionally, we evaluated other AI-generated text detection tools that do not specifically claim to detect ChatGPT-generated content to assess their performance in detecting ChatGPT-generated content. For our evaluation, we have curated a benchmark dataset consisting of prompts from ChatGPT and humans, including diverse questions from medical, open Q&A, and finance domains and user-generated responses from popular social networking platforms. The dataset serves as a reference to assess the performance of various techniques in detecting ChatGPT-generated content. Our evaluation results demonstrate that none of the existing methods can effectively detect ChatGPT-generated content.
ARGUS: Context-Based Detection of Stealthy IoT Infiltration Attacks
Feb 16, 2023IoT application domains, device diversity and connectivity are rapidly growing. IoT devices control various functions in smart homes and buildings, smart cities, and smart factories, making these devices an attractive target for attackers. On the other hand, the large variability of different application scenarios and inherent heterogeneity of devices make it very challenging to reliably detect abnormal IoT device behaviors and distinguish these from benign behaviors. Existing approaches for detecting attacks are mostly limited to attacks directly compromising individual IoT devices, or, require predefined detection policies. They cannot detect attacks that utilize the control plane of the IoT system to trigger actions in an unintended/malicious context, e.g., opening a smart lock while the smart home residents are absent. In this paper, we tackle this problem and propose ARGUS, the first self-learning intrusion detection system for detecting contextual attacks on IoT environments, in which the attacker maliciously invokes IoT device actions to reach its goals. ARGUS monitors the contextual setting based on the state and actions of IoT devices in the environment. An unsupervised Deep Neural Network (DNN) is used for modeling the typical contextual device behavior and detecting actions taking place in abnormal contextual settings. This unsupervised approach ensures that ARGUS is not restricted to detecting previously known attacks but is also able to detect new attacks. We evaluated ARGUS on heterogeneous real-world smart-home settings and achieve at least an F1-Score of 99.64% for each setup, with a false positive rate (FPR) of at most 0.03%.
BayBFed: Bayesian Backdoor Defense for Federated Learning
Jan 23, 2023Federated learning (FL) allows participants to jointly train a machine learning model without sharing their private data with others. However, FL is vulnerable to poisoning attacks such as backdoor attacks. Consequently, a variety of defenses have recently been proposed, which have primarily utilized intermediary states of the global model (i.e., logits) or distance of the local models (i.e., L2-norm) from the global model to detect malicious backdoors. However, as these approaches directly operate on client updates, their effectiveness depends on factors such as clients' data distribution or the adversary's attack strategies. In this paper, we introduce a novel and more generic backdoor defense framework, called BayBFed, which proposes to utilize probability distributions over client updates to detect malicious updates in FL: it computes a probabilistic measure over the clients' updates to keep track of any adjustments made in the updates, and uses a novel detection algorithm that can leverage this probabilistic measure to efficiently detect and filter out malicious updates. Thus, it overcomes the shortcomings of previous approaches that arise due to the direct usage of client updates; as our probabilistic measure will include all aspects of the local client training strategies. BayBFed utilizes two Bayesian Non-Parametric extensions: (i) a Hierarchical Beta-Bernoulli process to draw a probabilistic measure given the clients' updates, and (ii) an adaptation of the Chinese Restaurant Process (CRP), referred by us as CRP-Jensen, which leverages this probabilistic measure to detect and filter out malicious updates. We extensively evaluate our defense approach on five benchmark datasets: CIFAR10, Reddit, IoT intrusion detection, MNIST, and FMNIST, and show that it can effectively detect and eliminate malicious updates in FL without deteriorating the benign performance of the global model.
ESCORT: Ethereum Smart COntRacTs Vulnerability Detection using Deep Neural Network and Transfer Learning
Mar 23, 2021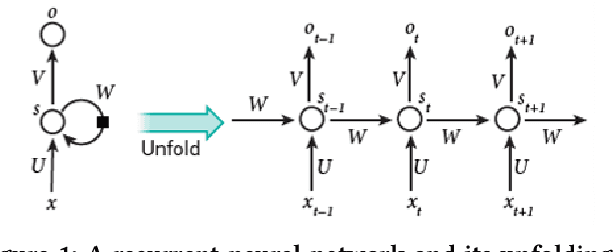
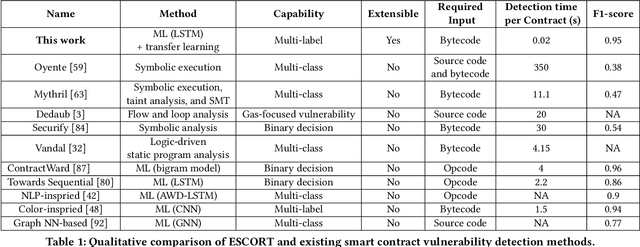
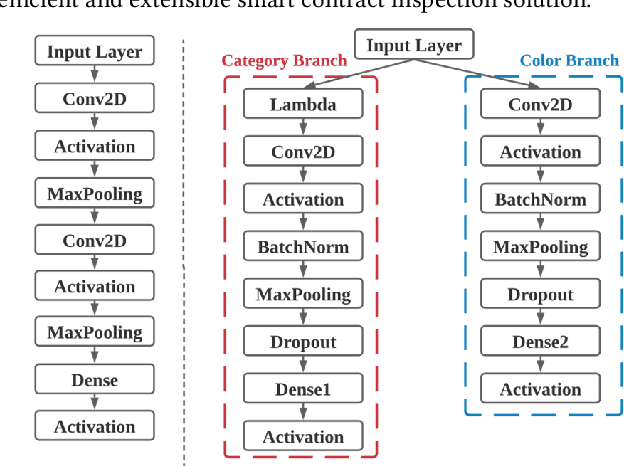
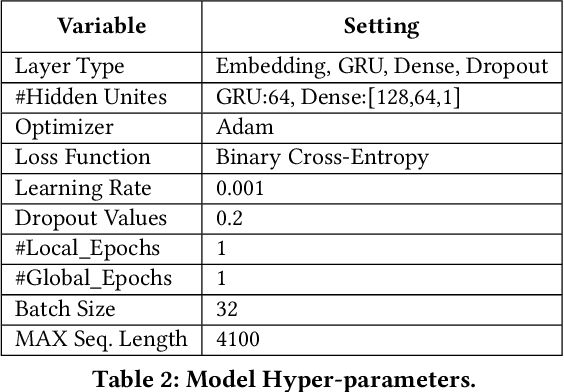
Ethereum smart contracts are automated decentralized applications on the blockchain that describe the terms of the agreement between buyers and sellers, reducing the need for trusted intermediaries and arbitration. However, the deployment of smart contracts introduces new attack vectors into the cryptocurrency systems. In particular, programming flaws in smart contracts can be and have already been exploited to gain enormous financial profits. It is thus an emerging yet crucial issue to detect vulnerabilities of different classes in contracts in an efficient manner. Existing machine learning-based vulnerability detection methods are limited and only inspect whether the smart contract is vulnerable, or train individual classifiers for each specific vulnerability, or demonstrate multi-class vulnerability detection without extensibility consideration. To overcome the scalability and generalization limitations of existing works, we propose ESCORT, the first Deep Neural Network (DNN)-based vulnerability detection framework for Ethereum smart contracts that support lightweight transfer learning on unseen security vulnerabilities, thus is extensible and generalizable. ESCORT leverages a multi-output NN architecture that consists of two parts: (i) A common feature extractor that learns the semantics of the input contract; (ii) Multiple branch structures where each branch learns a specific vulnerability type based on features obtained from the feature extractor. Experimental results show that ESCORT achieves an average F1-score of 95% on six vulnerability types and the detection time is 0.02 seconds per contract. When extended to new vulnerability types, ESCORT yields an average F1-score of 93%. To the best of our knowledge, ESCORT is the first framework that enables transfer learning on new vulnerability types with minimal modification of the DNN model architecture and re-training overhead.