 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinBreak: Jailbreaking LLM Security Alignments based on Twin Prompts
Jun 09, 2025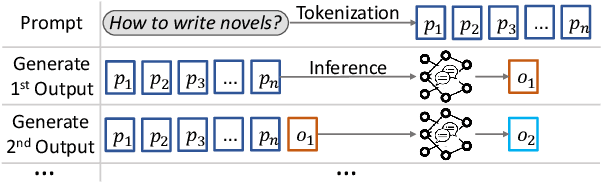



Machine learning is advancing rapidly, with applications bringing notable benefits, such as improvements in translation and code generation. Models like ChatGPT, powered by Large Language Models (LLMs), are increasingly integrated into daily life. However, alongside these benefits, LLMs also introduce social risks. Malicious users can exploit LLMs by submitting harmful prompts, such as requesting instructions for illegal activities. To mitigate this, models often include a security mechanism that automatically rejects such harmful prompts. However, they can be bypassed through LLM jailbreaks. Current jailbreaks often require significant manual effort, high computational costs, or result in excessive model modifications that may degrade regular utility. We introduce TwinBreak, an innovative safety alignment removal method. Building on the idea that the safety mechanism operates like an embedded backdoor, TwinBreak identifies and prunes parameters responsible for this functionality. By focusing on the most relevant model layers, TwinBreak performs fine-grained analysis of parameters essential to model utility and safety. TwinBreak is the first method to analyze intermediate outputs from prompts with high structural and content similarity to isolate safety parameters. We present the TwinPrompt dataset containing 100 such twin prompts. Experiments confirm TwinBreak's effectiveness, achieving 89% to 98% success rates with minimal computational requirements across 16 LLMs from five vendors.
GNN-Based Code Annotation Logic for Establishing Security Boundaries in C Code
Nov 19, 2024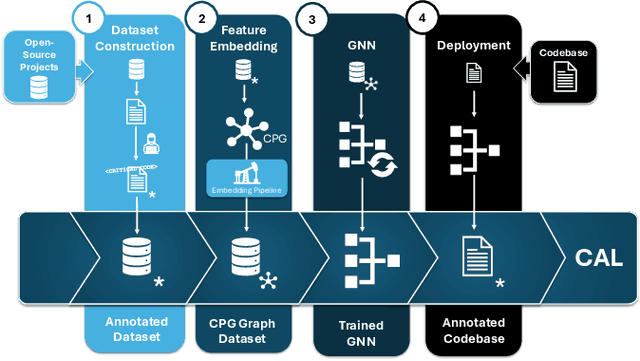
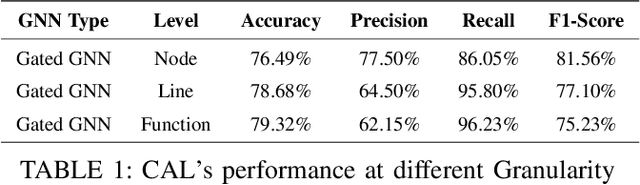
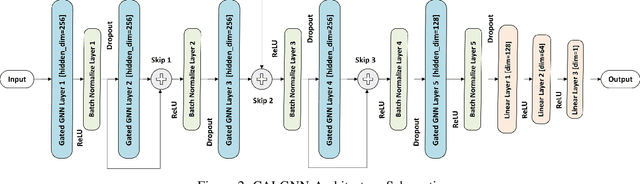

Securing sensitive operations in today's interconnected software landscape is crucial yet challenging. Modern platforms rely on Trusted Execution Environments (TEEs), such as Intel SGX and ARM TrustZone, to isolate security sensitive code from the main system, reducing the Trusted Computing Base (TCB) and providing stronger assurances. However, identifying which code should reside in TEEs is complex and requires specialized expertise, which is not supported by current automated tools. Existing solutions often migrate entire applications to TEEs, leading to suboptimal use and an increased TCB. To address this gap, we propose Code Annotation Logic (CAL), a pioneering tool that automatically identifies security sensitive components for TEE isolation. CAL analyzes codebases, leveraging a graph-based approach with novel feature construction and employing a custom graph neural network model to accurately determine which parts of the code should be isolated. CAL effectively optimizes TCB, reducing the burden of manual analysis and enhancing overall security. Our contributions include the definition of security sensitive code, the construction and labeling of a comprehensive dataset of source files, a feature rich graph based data preparation pipeline, and the CAL model for TEE integration. Evaluation results demonstrate CAL's efficacy in identifying sensitive code with a recall of 86.05%, an F1 score of 81.56%, and an identification rate of 91.59% for security sensitive functions. By enabling efficient code isolation, CAL advances the secure development of applications using TEEs, offering a practical solution for developers to reduce attack vectors.
Time-Aware Face Anti-Spoofing with Rotation Invariant Local Binary Patterns and Deep Learning
Aug 27, 2024
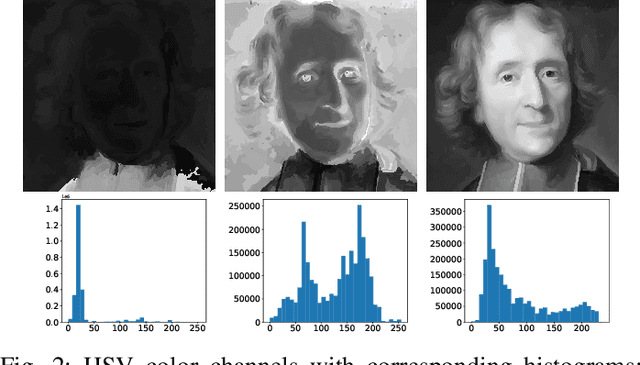
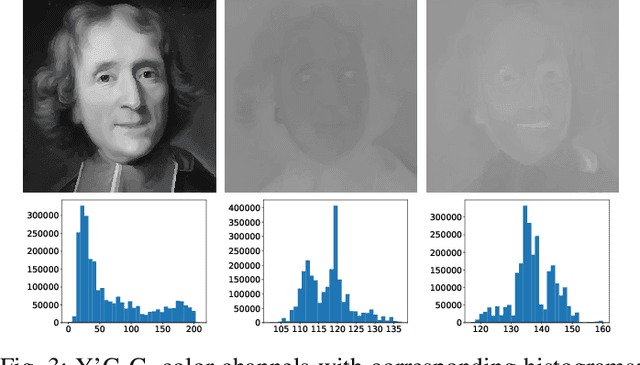
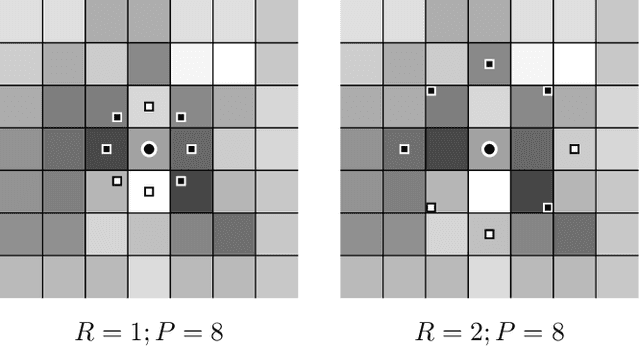
Facial recognition systems have become an integral part of the modern world. These methods accomplish the task of human identification in an automatic, fast, and non-interfering way. Past research has uncovered high vulnerability to simple imitation attacks that could lead to erroneous identification and subsequent authentication of attackers. Similar to face recognition, imitation attacks can also be detected with Machine Learning. Attack detection systems use a variety of facial features and advanced machine learning models for uncovering the presence of attacks. In this work, we assess existing work on liveness detection and propose a novel approach that promises high classification accuracy by combining previously unused features with time-aware deep learning strategies.
FreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
ClearMark: Intuitive and Robust Model Watermarking via Transposed Model Training
Oct 25, 2023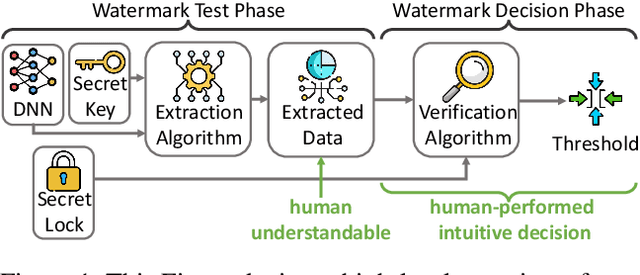
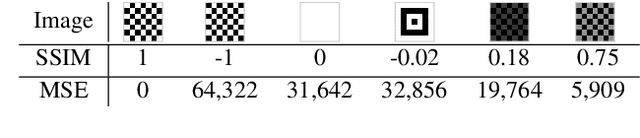
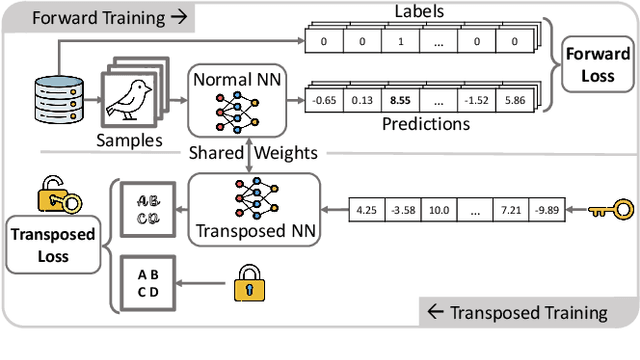

Due to costly efforts during data acquisition and model training, Deep Neural Networks (DNNs) belong to the intellectual property of the model creator. Hence, unauthorized use, theft, or modification may lead to legal repercussions. Existing DNN watermarking methods for ownership proof are often non-intuitive, embed human-invisible marks, require trust in algorithmic assessment that lacks human-understandable attributes, and rely on rigid thresholds, making it susceptible to failure in cases of partial watermark erasure. This paper introduces ClearMark, the first DNN watermarking method designed for intuitive human assessment. ClearMark embeds visible watermarks, enabling human decision-making without rigid value thresholds while allowing technology-assisted evaluations. ClearMark defines a transposed model architecture allowing to use of the model in a backward fashion to interwove the watermark with the main task within all model parameters. Compared to existing watermarking methods, ClearMark produces visual watermarks that are easy for humans to understand without requiring complex verification algorithms or strict thresholds. The watermark is embedded within all model parameters and entangled with the main task, exhibiting superior robustness. It shows an 8,544-bit watermark capacity comparable to the strongest existing work. Crucially, ClearMark's effectiveness is model and dataset-agnostic, and resilient against adversarial model manipulations, as demonstrated in a comprehensive study performed with four datasets and seven architectures.
Avoid Adversarial Adaption in Federated Learning by Multi-Metric Investigations
Jun 06, 2023
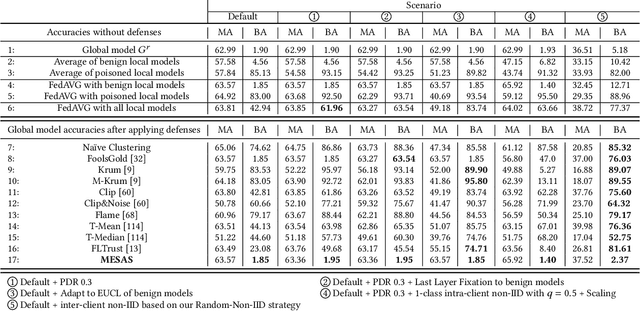

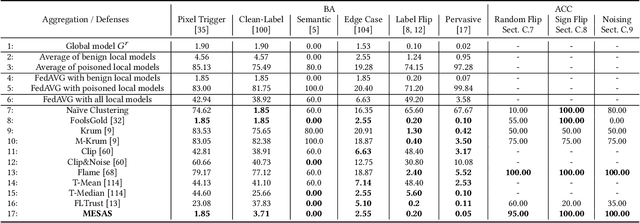
Federated Learning (FL) trains machine learning models on data distributed across multiple devices, avoiding data transfer to a central location. This improves privacy, reduces communication costs, and enhances model performance. However, FL is prone to poisoning attacks, which can be untargeted aiming to reduce the model performance, or targeted, so-called backdoors, which add adversarial behavior that can be triggered with appropriately crafted inputs. Striving for stealthiness, backdoor attacks are harder to deal with. Mitigation techniques against poisoning attacks rely on monitoring certain metrics and filtering malicious model updates. However, previous works didn't consider real-world adversaries and data distributions. To support our statement, we define a new notion of strong adaptive adversaries that can simultaneously adapt to multiple objectives and demonstrate through extensive tests, that existing defense methods can be circumvented in this adversary model. We also demonstrate, that existing defenses have limited effectiveness when no assumptions are made about underlying data distributions. To address realistic scenarios and adversary models, we propose Metric-Cascades (MESAS) a new defense that leverages multiple detection metrics simultaneously for the filtering of poisoned model updates. This approach forces adaptive attackers into a heavy multi-objective optimization problem, and our evaluation with nine backdoors and three datasets shows that even our strong adaptive attacker cannot evade MESAS's detection. We show that MESAS outperforms existing defenses in distinguishing backdoors from distortions originating from different data distributions within and across the clients. Overall, MESAS is the first defense that is robust against strong adaptive adversaries and is effective in real-world data scenarios while introducing a low overhead of 24.37s on average.
Close the Gate: Detecting Backdoored Models in Federated Learning based on Client-Side Deep Layer Output Analysis
Oct 14, 2022

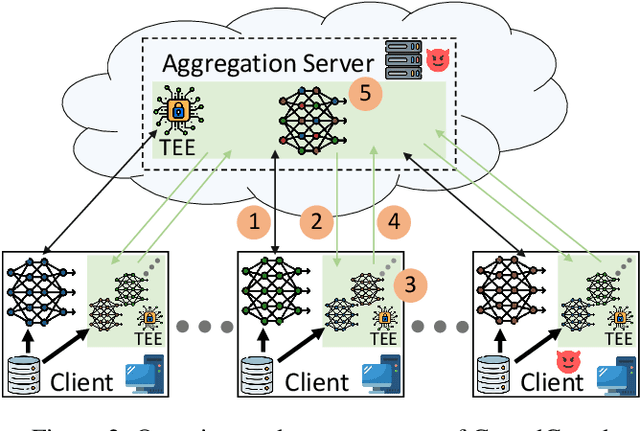

Federated Learning (FL) is a scheme for collaboratively training Deep Neural Networks (DNNs) with multiple data sources from different clients. Instead of sharing the data, each client trains the model locally, resulting in improved privacy. However, recently so-called targeted poisoning attacks have been proposed that allow individual clients to inject a backdoor into the trained model. Existing defenses against these backdoor attacks either rely on techniques like Differential Privacy to mitigate the backdoor, or analyze the weights of the individual models and apply outlier detection methods that restricts these defenses to certain data distributions. However, adding noise to the models' parameters or excluding benign outliers might also reduce the accuracy of the collaboratively trained model. Additionally, allowing the server to inspect the clients' models creates a privacy risk due to existing knowledge extraction methods. We propose \textit{CrowdGuard}, a model filtering defense, that mitigates backdoor attacks by leveraging the clients' data to analyze the individual models before the aggregation. To prevent data leaks, the server sends the individual models to secure enclaves, running in client-located Trusted Execution Environments. To effectively distinguish benign and poisoned models, even if the data of different clients are not independently and identically distributed (non-IID), we introduce a novel metric called \textit{HLBIM} to analyze the outputs of the DNN's hidden layers. We show that the applied significance-based detection algorithm combined can effectively detect poisoned models, even in non-IID scenarios.
ESCORT: Ethereum Smart COntRacTs Vulnerability Detection using Deep Neural Network and Transfer Learning
Mar 23, 2021
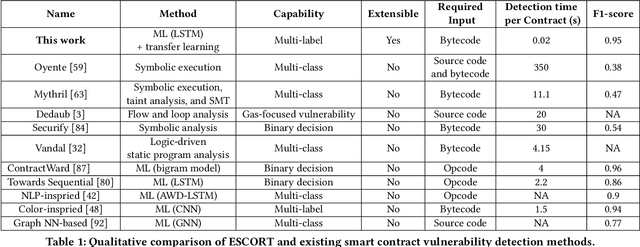
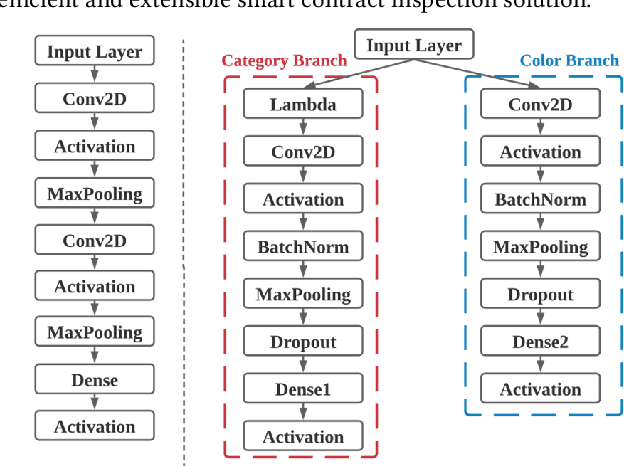
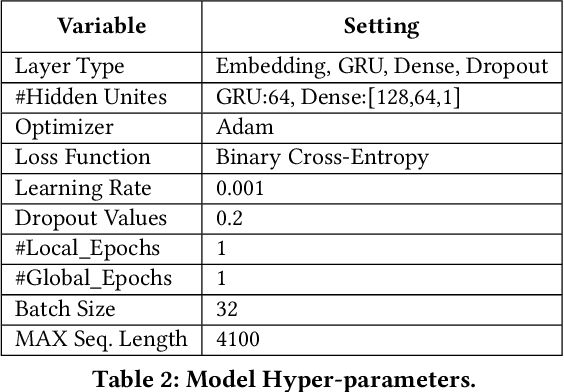
Ethereum smart contracts are automated decentralized applications on the blockchain that describe the terms of the agreement between buyers and sellers, reducing the need for trusted intermediaries and arbitration. However, the deployment of smart contracts introduces new attack vectors into the cryptocurrency systems. In particular, programming flaws in smart contracts can be and have already been exploited to gain enormous financial profits. It is thus an emerging yet crucial issue to detect vulnerabilities of different classes in contracts in an efficient manner. Existing machine learning-based vulnerability detection methods are limited and only inspect whether the smart contract is vulnerable, or train individual classifiers for each specific vulnerability, or demonstrate multi-class vulnerability detection without extensibility consideration. To overcome the scalability and generalization limitations of existing works, we propose ESCORT, the first Deep Neural Network (DNN)-based vulnerability detection framework for Ethereum smart contracts that support lightweight transfer learning on unseen security vulnerabilities, thus is extensible and generalizable. ESCORT leverages a multi-output NN architecture that consists of two parts: (i) A common feature extractor that learns the semantics of the input contract; (ii) Multiple branch structures where each branch learns a specific vulnerability type based on features obtained from the feature extractor. Experimental results show that ESCORT achieves an average F1-score of 95% on six vulnerability types and the detection time is 0.02 seconds per contract. When extended to new vulnerability types, ESCORT yields an average F1-score of 93%. To the best of our knowledge, ESCORT is the first framework that enables transfer learning on new vulnerability types with minimal modification of the DNN model architecture and re-training overhead.