 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightSplit: Practical Privacy-Preserving Split Learning via Orthogonal Projections
May 13, 2026Split learning (SL) enables collaborative training by partitioning a neural network across clients and a central server, but the cut-layer interface introduces a key challenge: high-dimensional activations incur substantial communication overhead while exposing representations vulnerable to reconstruction attacks. Existing approaches typically address efficiency or privacy in isolation, relying on additional mechanisms such as sparsification, quantization, or noise injection. We propose LightSplit, which limits information exposure and reduces communication overhead by applying a lightweight fixed orthogonal random projection at the cut layer. Based on Shannon's information theory, this projection acts as an information bottleneck that restricts instance-specific information and suppresses exploitable per-sample signals. By transmitting low-dimensional projections instead of raw activations, the server operates on lifted representations without requiring architectural modifications, ensuring compatibility with existing SL architectures. By avoiding additional trainable components on the client, the method remains lightweight and suitable for edge devices while preserving end-to-end differentiability via exact gradient propagation. As the projection is non-invertible, part of the original representation is irreversibly discarded at the client, LightSplit reduces the information available for reconstruction and limits information exposure. We extensively evaluate LightSplit on state-of-the-art benchmarks in both IID and non-IID settings across varying projection dimensions and client scales. Our results show that the method retains more than 95% of the baseline accuracy at up to 32x reduction in transmitted dimensionality while maintaining stable training dynamics.
SafeSplit: A Novel Defense Against Client-Side Backdoor Attacks in Split Learning
Jan 11, 2025
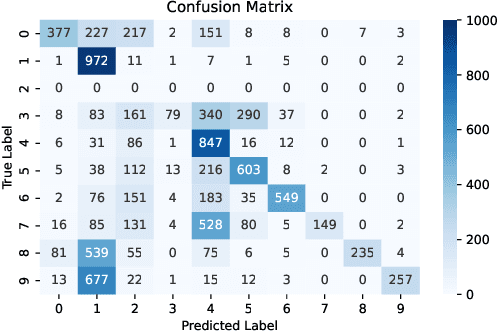
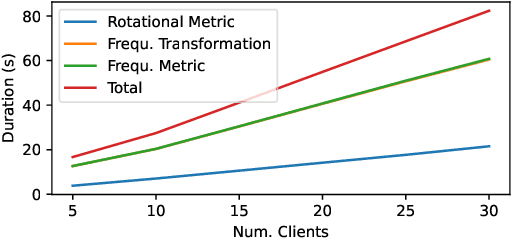
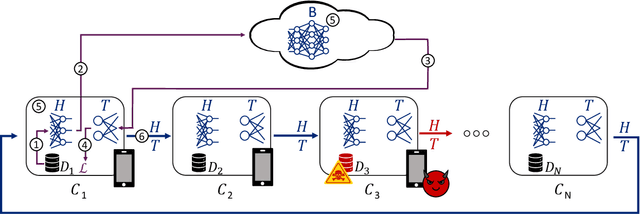
Split Learning (SL) is a distributed deep learning approach enabling multiple clients and a server to collaboratively train and infer on a shared deep neural network (DNN) without requiring clients to share their private local data. The DNN is partitioned in SL, with most layers residing on the server and a few initial layers and inputs on the client side. This configuration allows resource-constrained clients to participate in training and inference. However, the distributed architecture exposes SL to backdoor attacks, where malicious clients can manipulate local datasets to alter the DNN's behavior. Existing defenses from other distributed frameworks like Federated Learning are not applicable, and there is a lack of effective backdoor defenses specifically designed for SL. We present SafeSplit, the first defense against client-side backdoor attacks in Split Learning (SL). SafeSplit enables the server to detect and filter out malicious client behavior by employing circular backward analysis after a client's training is completed, iteratively reverting to a trained checkpoint where the model under examination is found to be benign. It uses a two-fold analysis to identify client-induced changes and detect poisoned models. First, a static analysis in the frequency domain measures the differences in the layer's parameters at the server. Second, a dynamic analysis introduces a novel rotational distance metric that assesses the orientation shifts of the server's layer parameters during training. Our comprehensive evaluation across various data distributions, client counts, and attack scenarios demonstrates the high efficacy of this dual analysis in mitigating backdoor attacks while preserving model utility.
DeepEclipse: How to Break White-Box DNN-Watermarking Schemes
Mar 06, 2024Deep Learning (DL) models have become crucial in digital transformation, thus raising concerns about their intellectual property rights. Different watermarking techniques have been developed to protect Deep Neural Networks (DNNs) from IP infringement, creating a competitive field for DNN watermarking and removal methods. The predominant watermarking schemes use white-box techniques, which involve modifying weights by adding a unique signature to specific DNN layers. On the other hand, existing attacks on white-box watermarking usually require knowledge of the specific deployed watermarking scheme or access to the underlying data for further training and fine-tuning. We propose DeepEclipse, a novel and unified framework designed to remove white-box watermarks. We present obfuscation techniques that significantly differ from the existing white-box watermarking removal schemes. DeepEclipse can evade watermark detection without prior knowledge of the underlying watermarking scheme, additional data, or training and fine-tuning. Our evaluation reveals that DeepEclipse excels in breaking multiple white-box watermarking schemes, reducing watermark detection to random guessing while maintaining a similar model accuracy as the original one. Our framework showcases a promising solution to address the ongoing DNN watermark protection and removal challenges.
FreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
DEMASQ: Unmasking the ChatGPT Wordsmith
Nov 08, 2023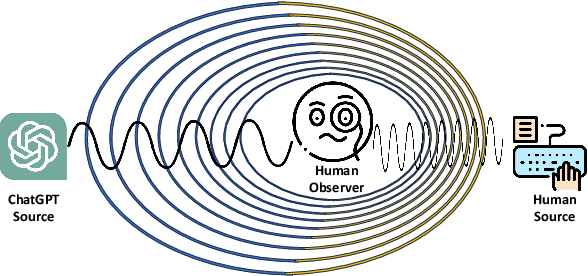
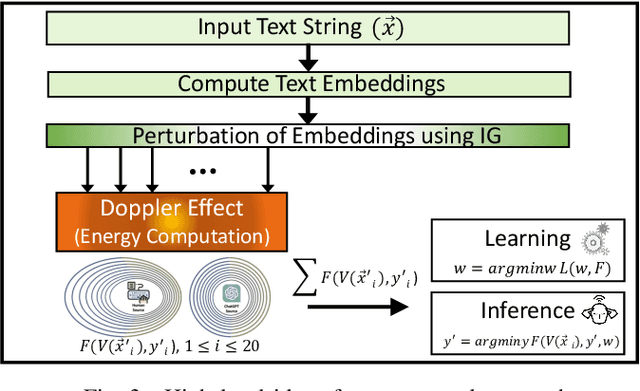

The potential misuse of ChatGPT and other Large Language Models (LLMs) has raised concerns regarding the dissemination of false information, plagiarism, academic dishonesty, and fraudulent activities. Consequently, distinguishing between AI-generated and human-generated content has emerged as an intriguing research topic. However, current text detection methods lack precision and are often restricted to specific tasks or domains, making them inadequate for identifying content generated by ChatGPT. In this paper, we propose an effective ChatGPT detector named DEMASQ, which accurately identifies ChatGPT-generated content. Our method addresses two critical factors: (i) the distinct biases in text composition observed in human- and machine-generated content and (ii) the alterations made by humans to evade previous detection methods. DEMASQ is an energy-based detection model that incorporates novel aspects, such as (i) optimization inspired by the Doppler effect to capture the interdependence between input text embeddings and output labels, and (ii) the use of explainable AI techniques to generate diverse perturbations. To evaluate our detector, we create a benchmark dataset comprising a mixture of prompts from both ChatGPT and humans, encompassing domains such as medical, open Q&A, finance, wiki, and Reddit. Our evaluation demonstrates that DEMASQ achieves high accuracy in identifying content generated by ChatGPT.
To ChatGPT, or not to ChatGPT: That is the question!
Apr 05, 2023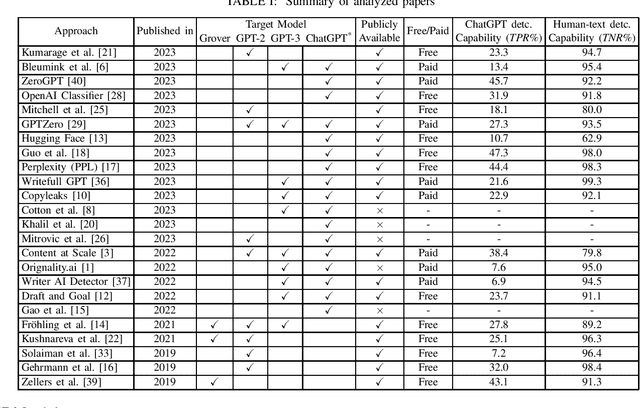
ChatGPT has become a global sensation. As ChatGPT and other Large Language Models (LLMs) emerge, concerns of misusing them in various ways increase, such as disseminating fake news, plagiarism, manipulating public opinion, cheating, and fraud. Hence, distinguishing AI-generated from human-generated becomes increasingly essential. Researchers have proposed various detection methodologies, ranging from basic binary classifiers to more complex deep-learning models. Some detection techniques rely on statistical characteristics or syntactic patterns, while others incorporate semantic or contextual information to improve accuracy. The primary objective of this study is to provide a comprehensive and contemporary assessment of the most recent techniques in ChatGPT detection. Additionally, we evaluated other AI-generated text detection tools that do not specifically claim to detect ChatGPT-generated content to assess their performance in detecting ChatGPT-generated content. For our evaluation, we have curated a benchmark dataset consisting of prompts from ChatGPT and humans, including diverse questions from medical, open Q&A, and finance domains and user-generated responses from popular social networking platforms. The dataset serves as a reference to assess the performance of various techniques in detecting ChatGPT-generated content. Our evaluation results demonstrate that none of the existing methods can effectively detect ChatGPT-generated content.