 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeSplit: A Novel Defense Against Client-Side Backdoor Attacks in Split Learning
Jan 11, 2025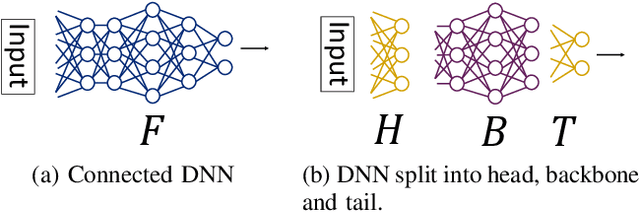
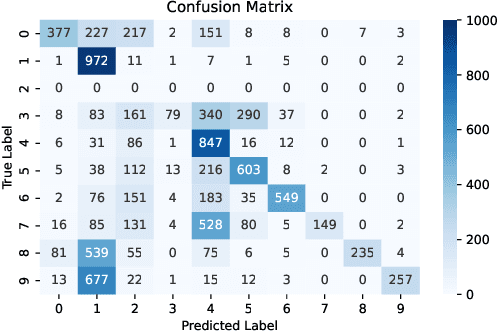
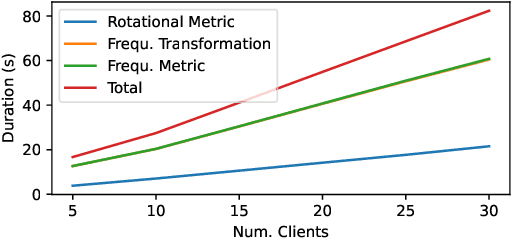
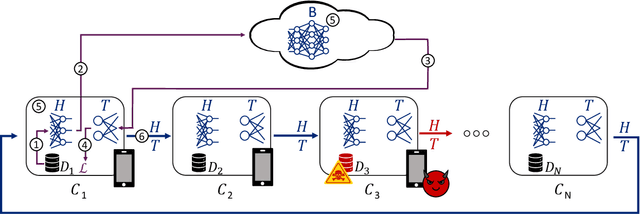
Split Learning (SL) is a distributed deep learning approach enabling multiple clients and a server to collaboratively train and infer on a shared deep neural network (DNN) without requiring clients to share their private local data. The DNN is partitioned in SL, with most layers residing on the server and a few initial layers and inputs on the client side. This configuration allows resource-constrained clients to participate in training and inference. However, the distributed architecture exposes SL to backdoor attacks, where malicious clients can manipulate local datasets to alter the DNN's behavior. Existing defenses from other distributed frameworks like Federated Learning are not applicable, and there is a lack of effective backdoor defenses specifically designed for SL. We present SafeSplit, the first defense against client-side backdoor attacks in Split Learning (SL). SafeSplit enables the server to detect and filter out malicious client behavior by employing circular backward analysis after a client's training is completed, iteratively reverting to a trained checkpoint where the model under examination is found to be benign. It uses a two-fold analysis to identify client-induced changes and detect poisoned models. First, a static analysis in the frequency domain measures the differences in the layer's parameters at the server. Second, a dynamic analysis introduces a novel rotational distance metric that assesses the orientation shifts of the server's layer parameters during training. Our comprehensive evaluation across various data distributions, client counts, and attack scenarios demonstrates the high efficacy of this dual analysis in mitigating backdoor attacks while preserving model utility.
FreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
FLEDGE: Ledger-based Federated Learning Resilient to Inference and Backdoor Attacks
Oct 03, 2023



Federated learning (FL) is a distributed learning process that uses a trusted aggregation server to allow multiple parties (or clients) to collaboratively train a machine learning model without having them share their private data. Recent research, however, has demonstrated the effectiveness of inference and poisoning attacks on FL. Mitigating both attacks simultaneously is very challenging. State-of-the-art solutions have proposed the use of poisoning defenses with Secure Multi-Party Computation (SMPC) and/or Differential Privacy (DP). However, these techniques are not efficient and fail to address the malicious intent behind the attacks, i.e., adversaries (curious servers and/or compromised clients) seek to exploit a system for monetization purposes. To overcome these limitations, we present a ledger-based FL framework known as FLEDGE that allows making parties accountable for their behavior and achieve reasonable efficiency for mitigating inference and poisoning attacks. Our solution leverages crypto-currency to increase party accountability by penalizing malicious behavior and rewarding benign conduct. We conduct an extensive evaluation on four public datasets: Reddit, MNIST, Fashion-MNIST, and CIFAR-10. Our experimental results demonstrate that (1) FLEDGE provides strong privacy guarantees for model updates without sacrificing model utility; (2) FLEDGE can successfully mitigate different poisoning attacks without degrading the performance of the global model; and (3) FLEDGE offers unique reward mechanisms to promote benign behavior during model training and/or model aggregation.
ARGUS: Context-Based Detection of Stealthy IoT Infiltration Attacks
Feb 16, 2023IoT application domains, device diversity and connectivity are rapidly growing. IoT devices control various functions in smart homes and buildings, smart cities, and smart factories, making these devices an attractive target for attackers. On the other hand, the large variability of different application scenarios and inherent heterogeneity of devices make it very challenging to reliably detect abnormal IoT device behaviors and distinguish these from benign behaviors. Existing approaches for detecting attacks are mostly limited to attacks directly compromising individual IoT devices, or, require predefined detection policies. They cannot detect attacks that utilize the control plane of the IoT system to trigger actions in an unintended/malicious context, e.g., opening a smart lock while the smart home residents are absent. In this paper, we tackle this problem and propose ARGUS, the first self-learning intrusion detection system for detecting contextual attacks on IoT environments, in which the attacker maliciously invokes IoT device actions to reach its goals. ARGUS monitors the contextual setting based on the state and actions of IoT devices in the environment. An unsupervised Deep Neural Network (DNN) is used for modeling the typical contextual device behavior and detecting actions taking place in abnormal contextual settings. This unsupervised approach ensures that ARGUS is not restricted to detecting previously known attacks but is also able to detect new attacks. We evaluated ARGUS on heterogeneous real-world smart-home settings and achieve at least an F1-Score of 99.64% for each setup, with a false positive rate (FPR) of at most 0.03%.
BayBFed: Bayesian Backdoor Defense for Federated Learning
Jan 23, 2023Federated learning (FL) allows participants to jointly train a machine learning model without sharing their private data with others. However, FL is vulnerable to poisoning attacks such as backdoor attacks. Consequently, a variety of defenses have recently been proposed, which have primarily utilized intermediary states of the global model (i.e., logits) or distance of the local models (i.e., L2-norm) from the global model to detect malicious backdoors. However, as these approaches directly operate on client updates, their effectiveness depends on factors such as clients' data distribution or the adversary's attack strategies. In this paper, we introduce a novel and more generic backdoor defense framework, called BayBFed, which proposes to utilize probability distributions over client updates to detect malicious updates in FL: it computes a probabilistic measure over the clients' updates to keep track of any adjustments made in the updates, and uses a novel detection algorithm that can leverage this probabilistic measure to efficiently detect and filter out malicious updates. Thus, it overcomes the shortcomings of previous approaches that arise due to the direct usage of client updates; as our probabilistic measure will include all aspects of the local client training strategies. BayBFed utilizes two Bayesian Non-Parametric extensions: (i) a Hierarchical Beta-Bernoulli process to draw a probabilistic measure given the clients' updates, and (ii) an adaptation of the Chinese Restaurant Process (CRP), referred by us as CRP-Jensen, which leverages this probabilistic measure to detect and filter out malicious updates. We extensively evaluate our defense approach on five benchmark datasets: CIFAR10, Reddit, IoT intrusion detection, MNIST, and FMNIST, and show that it can effectively detect and eliminate malicious updates in FL without deteriorating the benign performance of the global model.
Close the Gate: Detecting Backdoored Models in Federated Learning based on Client-Side Deep Layer Output Analysis
Oct 14, 2022

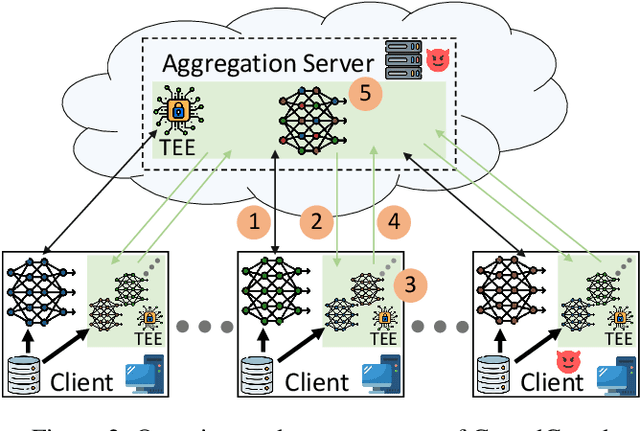

Federated Learning (FL) is a scheme for collaboratively training Deep Neural Networks (DNNs) with multiple data sources from different clients. Instead of sharing the data, each client trains the model locally, resulting in improved privacy. However, recently so-called targeted poisoning attacks have been proposed that allow individual clients to inject a backdoor into the trained model. Existing defenses against these backdoor attacks either rely on techniques like Differential Privacy to mitigate the backdoor, or analyze the weights of the individual models and apply outlier detection methods that restricts these defenses to certain data distributions. However, adding noise to the models' parameters or excluding benign outliers might also reduce the accuracy of the collaboratively trained model. Additionally, allowing the server to inspect the clients' models creates a privacy risk due to existing knowledge extraction methods. We propose \textit{CrowdGuard}, a model filtering defense, that mitigates backdoor attacks by leveraging the clients' data to analyze the individual models before the aggregation. To prevent data leaks, the server sends the individual models to secure enclaves, running in client-located Trusted Execution Environments. To effectively distinguish benign and poisoned models, even if the data of different clients are not independently and identically distributed (non-IID), we introduce a novel metric called \textit{HLBIM} to analyze the outputs of the DNN's hidden layers. We show that the applied significance-based detection algorithm combined can effectively detect poisoned models, even in non-IID scenarios.
DeepSight: Mitigating Backdoor Attacks in Federated Learning Through Deep Model Inspection
Jan 03, 2022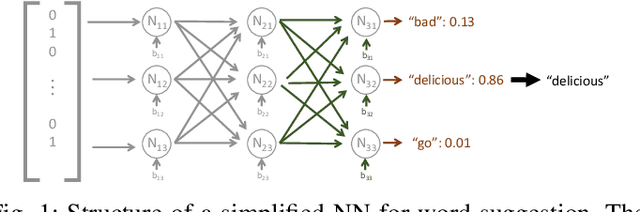



Federated Learning (FL) allows multiple clients to collaboratively train a Neural Network (NN) model on their private data without revealing the data. Recently, several targeted poisoning attacks against FL have been introduced. These attacks inject a backdoor into the resulting model that allows adversary-controlled inputs to be misclassified. Existing countermeasures against backdoor attacks are inefficient and often merely aim to exclude deviating models from the aggregation. However, this approach also removes benign models of clients with deviating data distributions, causing the aggregated model to perform poorly for such clients. To address this problem, we propose DeepSight, a novel model filtering approach for mitigating backdoor attacks. It is based on three novel techniques that allow to characterize the distribution of data used to train model updates and seek to measure fine-grained differences in the internal structure and outputs of NNs. Using these techniques, DeepSight can identify suspicious model updates. We also develop a scheme that can accurately cluster model updates. Combining the results of both components, DeepSight is able to identify and eliminate model clusters containing poisoned models with high attack impact. We also show that the backdoor contributions of possibly undetected poisoned models can be effectively mitigated with existing weight clipping-based defenses. We evaluate the performance and effectiveness of DeepSight and show that it can mitigate state-of-the-art backdoor attacks with a negligible impact on the model's performance on benign data.