 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random Inputs: A Novel ML-Based Hardware Fuzzing
Apr 10, 2024
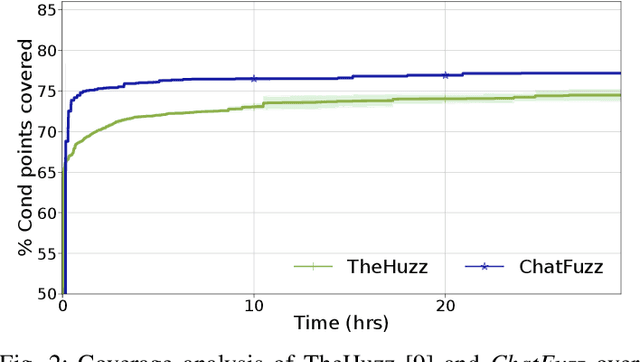
Modern computing systems heavily rely on hardware as the root of trust. However, their increasing complexity has given rise to security-critical vulnerabilities that cross-layer at-tacks can exploit. Traditional hardware vulnerability detection methods, such as random regression and formal verification, have limitations. Random regression, while scalable, is slow in exploring hardware, and formal verification techniques are often concerned with manual effort and state explosions. Hardware fuzzing has emerged as an effective approach to exploring and detecting security vulnerabilities in large-scale designs like modern processors. They outperform traditional methods regarding coverage, scalability, and efficiency. However, state-of-the-art fuzzers struggle to achieve comprehensive coverage of intricate hardware designs within a practical timeframe, often falling short of a 70% coverage threshold. We propose a novel ML-based hardware fuzzer, ChatFuzz, to address this challenge. Ourapproach leverages LLMs like ChatGPT to understand processor language, focusing on machine codes and generating assembly code sequences. RL is integrated to guide the input generation process by rewarding the inputs using code coverage metrics. We use the open-source RISCV-based RocketCore processor as our testbed. ChatFuzz achieves condition coverage rate of 75% in just 52 minutes compared to a state-of-the-art fuzzer, which requires a lengthy 30-hour window to reach a similar condition coverage. Furthermore, our fuzzer can attain 80% coverage when provided with a limited pool of 10 simulation instances/licenses within a 130-hour window. During this time, it conducted a total of 199K test cases, of which 6K produced discrepancies with the processor's golden model. Our analysis identified more than 10 unique mismatches, including two new bugs in the RocketCore and discrepancies from the RISC-V ISA Simulator.
LLM-assisted Generation of Hardware Assertions
Jun 24, 2023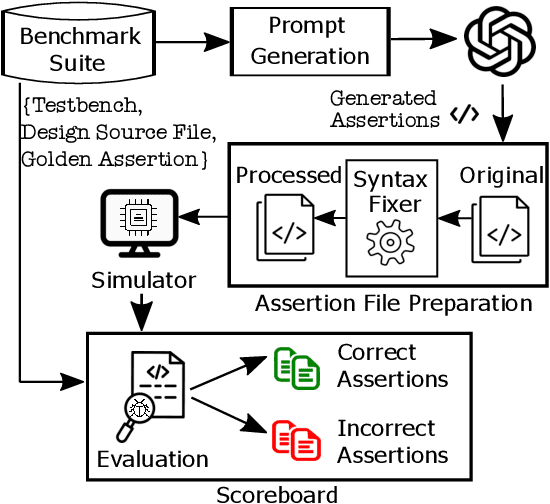
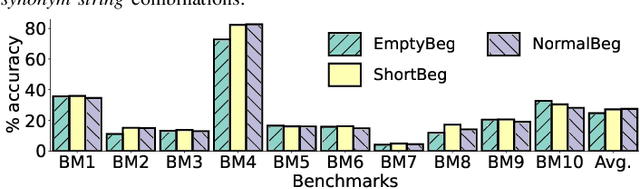
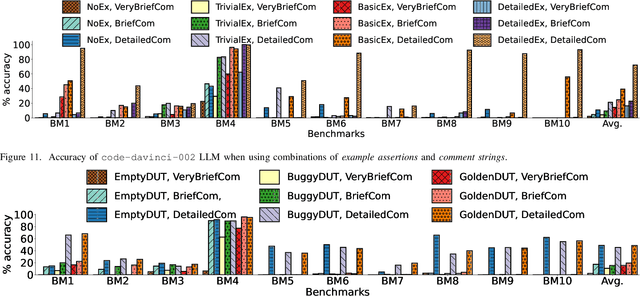
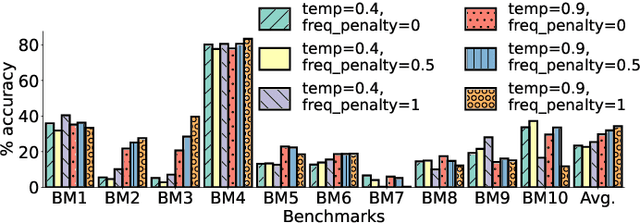
The security of computer systems typically relies on a hardware root of trust. As vulnerabilities in hardware can have severe implications on a system, there is a need for techniques to support security verification activities. Assertion-based verification is a popular verification technique that involves capturing design intent in a set of assertions that can be used in formal verification or testing-based checking. However, writing security-centric assertions is a challenging task. In this work, we investigate the use of emerging large language models (LLMs) for code generation in hardware assertion generation for security, where primarily natural language prompts, such as those one would see as code comments in assertion files, are used to produce SystemVerilog assertions. We focus our attention on a popular LLM and characterize its ability to write assertions out of the box, given varying levels of detail in the prompt. We design an evaluation framework that generates a variety of prompts, and we create a benchmark suite comprising real-world hardware designs and corresponding golden reference assertions that we want to generate with the LLM.