 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: GenAI Units In Digital Design Education
Mar 18, 2026GenAI Units In Digital Design Education (GUIDE) is an open courseware repository with runnable Google Colab labs and other materials. We describe the repository's architecture and educational approach based on standardized teaching units comprising slides, short videos, runnable labs, and related papers. This organization enables consistency for both the students' learning experience and the reuse and grading by instructors. We demonstrate GUIDE in practice with three representative units: VeriThoughts for reasoning and formal-verification-backed RTL generation, enhanced LLM-aided testbench generation, and LLMPirate for IP Piracy. We also provide details for four example course instances (GUIDE4ChipDesign, Build your ASIC, GUIDE4HardwareSecurity, and Hardware Design) that assemble GUIDE units into full semester offerings, learning outcomes, and capstone projects, all based on proven materials. For example, the GUIDE4HardwareSecurity course includes a project on LLM-aided hardware Trojan insertion that has been successfully deployed in the classroom and in Cybersecurity Games and Conference (CSAW), a student competition and academic conference for cybersecurity. We also organized an NYU Cognichip Hackathon, engaging students across 24 international teams in AI-assisted RTL design workflows. The GUIDE repository is open for contributions and available at: https://github.com/FCHXWH823/LLM4ChipDesign.
Free and Fair Hardware: A Pathway to Copyright Infringement-Free Verilog Generation using LLMs
May 09, 2025Limitations in Large Language Model (LLM) capabilities for hardware design tasks, such as generating functional Verilog codes, have motivated various fine-tuning optimizations utilizing curated hardware datasets from open-source repositories. However, these datasets remain limited in size and contain minimal checks on licensing for reuse, resulting in potential copyright violations by fine-tuned LLMs. Therefore, we propose an evaluation benchmark to estimate the risk of Verilog-trained LLMs to generate copyright-protected codes. To minimize this risk, we present an open-source Verilog dataset, FreeSet, containing over 220k files, along with the automated dataset curation framework utilized to provide additional guarantees of fair-use Verilog data. We then execute an LLM fine-tuning framework consisting of continual pre-training, resulting in a fine-tuned Llama model for Verilog, FreeV. Our results indicate that FreeV demonstrates the smallest risk of copyright-infringement among prior works, with only a 3% violation rate. Furthermore, experimental results demonstrate improvements in Verilog generation functionality over its baseline model, improving VerilogEval pass@10 rates by over 10%.
LLMPirate: LLMs for Black-box Hardware IP Piracy
Nov 25, 2024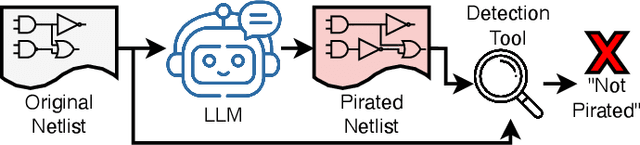



The rapid advancement of large language models (LLMs) has enabled the ability to effectively analyze and generate code nearly instantaneously, resulting in their widespread adoption in software development. Following this advancement, researchers and companies have begun integrating LLMs across the hardware design and verification process. However, these highly potent LLMs can also induce new attack scenarios upon security vulnerabilities across the hardware development process. One such attack vector that has not been explored is intellectual property (IP) piracy. Given that this attack can manifest as rewriting hardware designs to evade piracy detection, it is essential to thoroughly evaluate LLM capabilities in performing this task and assess the mitigation abilities of current IP piracy detection tools. Therefore, in this work, we propose LLMPirate, the first LLM-based technique able to generate pirated variations of circuit designs that successfully evade detection across multiple state-of-the-art piracy detection tools. We devise three solutions to overcome challenges related to integration of LLMs for hardware circuit designs, scalability to large circuits, and effectiveness, resulting in an end-to-end automated, efficient, and practical formulation. We perform an extensive experimental evaluation of LLMPirate using eight LLMs of varying sizes and capabilities and assess their performance in pirating various circuit designs against four state-of-the-art, widely-used piracy detection tools. Our experiments demonstrate that LLMPirate is able to consistently evade detection on 100% of tested circuits across every detection tool. Additionally, we showcase the ramifications of LLMPirate using case studies on IBEX and MOR1KX processors and a GPS module, that we successfully pirate. We envision that our work motivates and fosters the development of better IP piracy detection tools.
CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation
Apr 12, 2024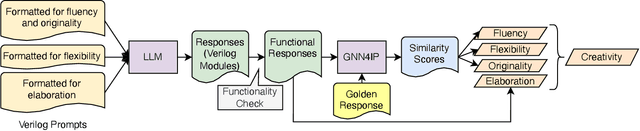
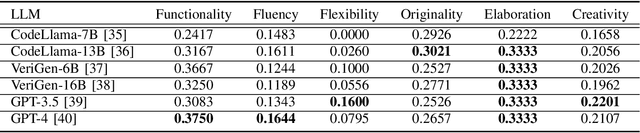
Large Language Models (LLMs) have proved effective and efficient in generating code, leading to their utilization within the hardware design process. Prior works evaluating LLMs' abilities for register transfer level code generation solely focus on functional correctness. However, the creativity associated with these LLMs, or the ability to generate novel and unique solutions, is a metric not as well understood, in part due to the challenge of quantifying this quality. To address this research gap, we present CreativeEval, a framework for evaluating the creativity of LLMs within the context of generating hardware designs. We quantify four creative sub-components, fluency, flexibility, originality, and elaboration, through various prompting and post-processing techniques. We then evaluate multiple popular LLMs (including GPT models, CodeLlama, and VeriGen) upon this creativity metric, with results indicating GPT-3.5 as the most creative model in generating hardware designs.
Beyond Random Inputs: A Novel ML-Based Hardware Fuzzing
Apr 10, 2024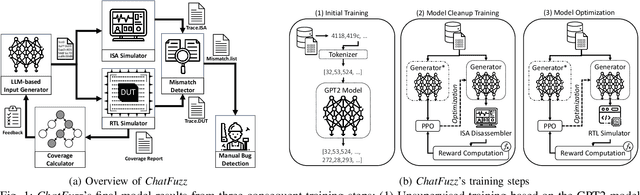
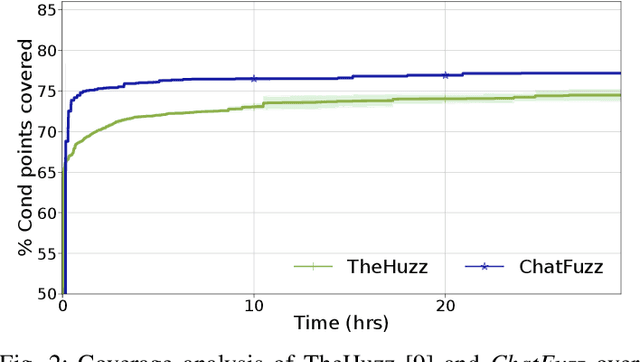
Modern computing systems heavily rely on hardware as the root of trust. However, their increasing complexity has given rise to security-critical vulnerabilities that cross-layer at-tacks can exploit. Traditional hardware vulnerability detection methods, such as random regression and formal verification, have limitations. Random regression, while scalable, is slow in exploring hardware, and formal verification techniques are often concerned with manual effort and state explosions. Hardware fuzzing has emerged as an effective approach to exploring and detecting security vulnerabilities in large-scale designs like modern processors. They outperform traditional methods regarding coverage, scalability, and efficiency. However, state-of-the-art fuzzers struggle to achieve comprehensive coverage of intricate hardware designs within a practical timeframe, often falling short of a 70% coverage threshold. We propose a novel ML-based hardware fuzzer, ChatFuzz, to address this challenge. Ourapproach leverages LLMs like ChatGPT to understand processor language, focusing on machine codes and generating assembly code sequences. RL is integrated to guide the input generation process by rewarding the inputs using code coverage metrics. We use the open-source RISCV-based RocketCore processor as our testbed. ChatFuzz achieves condition coverage rate of 75% in just 52 minutes compared to a state-of-the-art fuzzer, which requires a lengthy 30-hour window to reach a similar condition coverage. Furthermore, our fuzzer can attain 80% coverage when provided with a limited pool of 10 simulation instances/licenses within a 130-hour window. During this time, it conducted a total of 199K test cases, of which 6K produced discrepancies with the processor's golden model. Our analysis identified more than 10 unique mismatches, including two new bugs in the RocketCore and discrepancies from the RISC-V ISA Simulator.
AttackGNN: Red-Teaming GNNs in Hardware Security Using Reinforcement Learning
Feb 26, 2024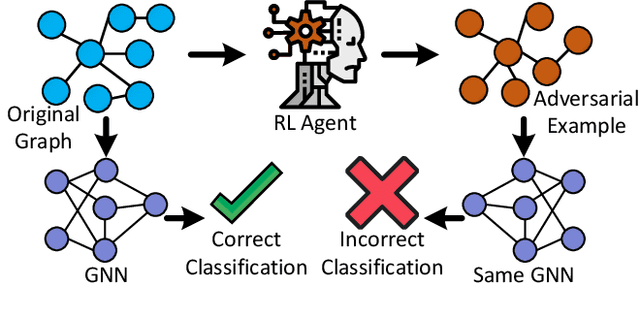

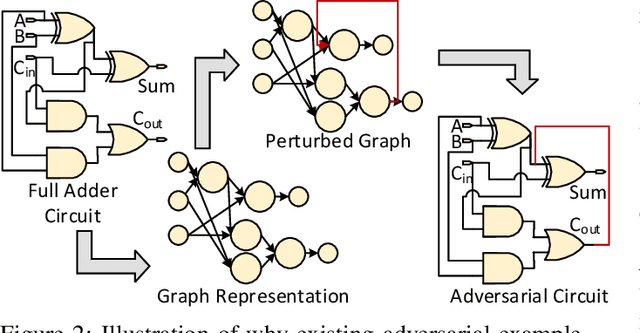
Machine learning has shown great promise in addressing several critical hardware security problems. In particular, researchers have developed novel graph neural network (GNN)-based techniques for detecting intellectual property (IP) piracy, detecting hardware Trojans (HTs), and reverse engineering circuits, to name a few. These techniques have demonstrated outstanding accuracy and have received much attention in the community. However, since these techniques are used for security applications, it is imperative to evaluate them thoroughly and ensure they are robust and do not compromise the security of integrated circuits. In this work, we propose AttackGNN, the first red-team attack on GNN-based techniques in hardware security. To this end, we devise a novel reinforcement learning (RL) agent that generates adversarial examples, i.e., circuits, against the GNN-based techniques. We overcome three challenges related to effectiveness, scalability, and generality to devise a potent RL agent. We target five GNN-based techniques for four crucial classes of problems in hardware security: IP piracy, detecting/localizing HTs, reverse engineering, and hardware obfuscation. Through our approach, we craft circuits that fool all GNNs considered in this work. For instance, to evade IP piracy detection, we generate adversarial pirated circuits that fool the GNN-based defense into classifying our crafted circuits as not pirated. For attacking HT localization GNN, our attack generates HT-infested circuits that fool the defense on all tested circuits. We obtain a similar 100% success rate against GNNs for all classes of problems.
Make Every Move Count: LLM-based High-Quality RTL Code Generation Using MCTS
Feb 05, 2024Existing large language models (LLMs) for register transfer level code generation face challenges like compilation failures and suboptimal power, performance, and area (PPA) efficiency. This is due to the lack of PPA awareness in conventional transformer decoding algorithms. In response, we present an automated transformer decoding algorithm that integrates Monte Carlo tree-search for lookahead, guiding the transformer to produce compilable, functionally correct, and PPA-optimized code. Empirical evaluation with a fine-tuned language model on RTL codesets shows that our proposed technique consistently generates functionally correct code compared to prompting-only methods and effectively addresses the PPA-unawareness drawback of naive large language models. For the largest design generated by the state-of-the-art LLM (16-bit adder), our technique can achieve a 31.8% improvement in the area-delay product.
LLM-assisted Generation of Hardware Assertions
Jun 24, 2023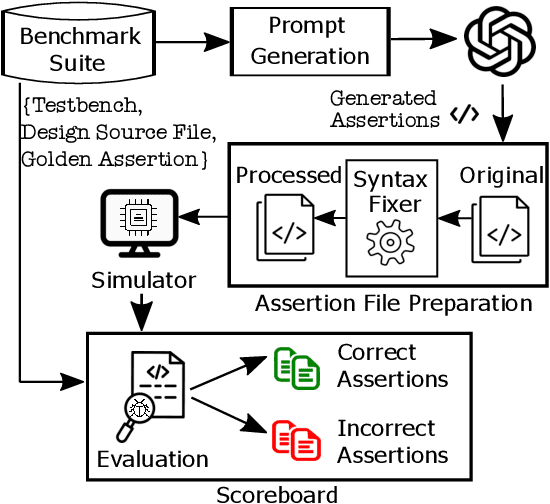
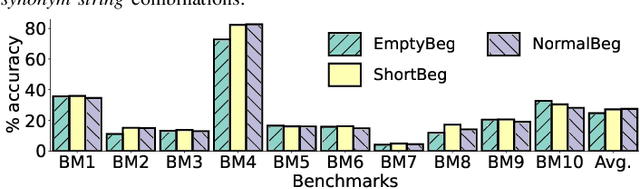
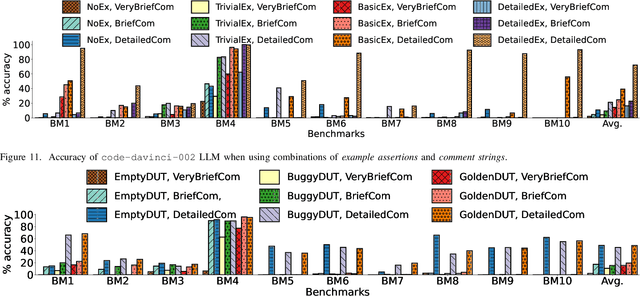
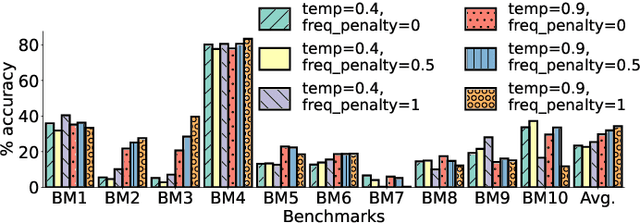
The security of computer systems typically relies on a hardware root of trust. As vulnerabilities in hardware can have severe implications on a system, there is a need for techniques to support security verification activities. Assertion-based verification is a popular verification technique that involves capturing design intent in a set of assertions that can be used in formal verification or testing-based checking. However, writing security-centric assertions is a challenging task. In this work, we investigate the use of emerging large language models (LLMs) for code generation in hardware assertion generation for security, where primarily natural language prompts, such as those one would see as code comments in assertion files, are used to produce SystemVerilog assertions. We focus our attention on a popular LLM and characterize its ability to write assertions out of the box, given varying levels of detail in the prompt. We design an evaluation framework that generates a variety of prompts, and we create a benchmark suite comprising real-world hardware designs and corresponding golden reference assertions that we want to generate with the LLM.