 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM-based Root Cause Analysis of Hardware Design Failures
Jul 09, 2025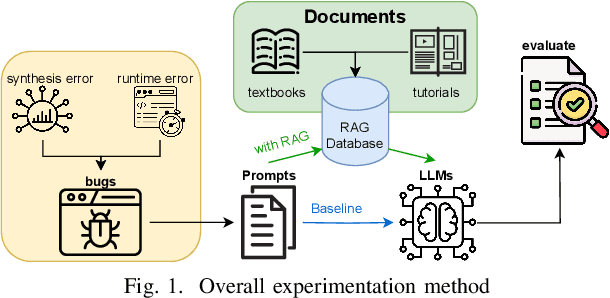


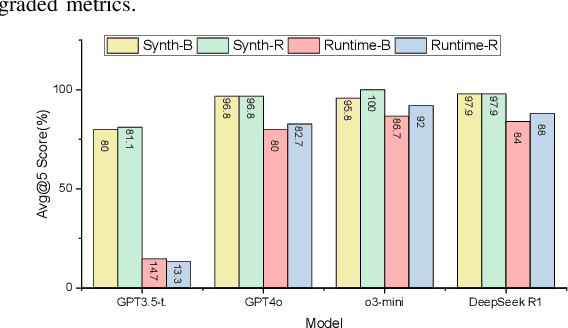
With advances in large language models (LLMs), new opportunities have emerged to develop tools that support the digital hardware design process. In this work, we explore how LLMs can assist with explaining the root cause of design issues and bugs that are revealed during synthesis and simulation, a necessary milestone on the pathway towards widespread use of LLMs in the hardware design process and for hardware security analysis. We find promising results: for our corpus of 34 different buggy scenarios, OpenAI's o3-mini reasoning model reached a correct determination 100% of the time under pass@5 scoring, with other state of the art models and configurations usually achieving more than 80% performance and more than 90% when assisted with retrieval-augmented generation.
Optimizing Vision-Language Interactions Through Decoder-Only Models
Dec 14, 2024Vision-Language Models (VLMs) have emerged as key enablers for multimodal tasks, but their reliance on separate visual encoders introduces challenges in efficiency, scalability, and modality alignment. To address these limitations, we propose MUDAIF (Multimodal Unified Decoder with Adaptive Input Fusion), a decoder-only vision-language model that seamlessly integrates visual and textual inputs through a novel Vision-Token Adapter (VTA) and adaptive co-attention mechanism. By eliminating the need for a visual encoder, MUDAIF achieves enhanced efficiency, flexibility, and cross-modal understanding. Trained on a large-scale dataset of 45M image-text pairs, MUDAIF consistently outperforms state-of-the-art methods across multiple benchmarks, including VQA, image captioning, and multimodal reasoning tasks. Extensive analyses and human evaluations demonstrate MUDAIF's robustness, generalization capabilities, and practical usability, establishing it as a new standard in encoder-free vision-language models.
Leveraging Language Models for Emotion and Behavior Analysis in Education
Aug 13, 2024The analysis of students' emotions and behaviors is crucial for enhancing learning outcomes and personalizing educational experiences. Traditional methods often rely on intrusive visual and physiological data collection, posing privacy concerns and scalability issues. This paper proposes a novel method leveraging large language models (LLMs) and prompt engineering to analyze textual data from students. Our approach utilizes tailored prompts to guide LLMs in detecting emotional and engagement states, providing a non-intrusive and scalable solution. We conducted experiments using Qwen, ChatGPT, Claude2, and GPT-4, comparing our method against baseline models and chain-of-thought (CoT) prompting. Results demonstrate that our method significantly outperforms the baselines in both accuracy and contextual understanding. This study highlights the potential of LLMs combined with prompt engineering to offer practical and effective tools for educational emotion and behavior analysis.
Explaining EDA synthesis errors with LLMs
Apr 07, 2024
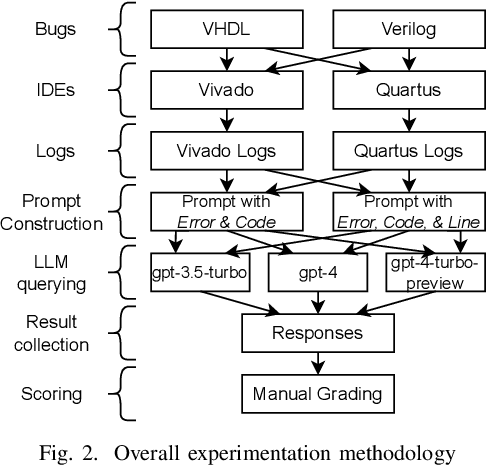


Training new engineers in digital design is a challenge, particularly when it comes to teaching the complex electronic design automation (EDA) tooling used in this domain. Learners will typically deploy designs in the Verilog and VHDL hardware description languages to Field Programmable Gate Arrays (FPGAs) from Altera (Intel) and Xilinx (AMD) via proprietary closed-source toolchains (Quartus Prime and Vivado, respectively). These tools are complex and difficult to use -- yet, as they are the tools used in industry, they are an essential first step in this space. In this work, we examine how recent advances in artificial intelligence may be leveraged to address aspects of this challenge. Specifically, we investigate if Large Language Models (LLMs), which have demonstrated text comprehension and question-answering capabilities, can be used to generate novice-friendly explanations of compile-time synthesis error messages from Quartus Prime and Vivado. To perform this study we generate 936 error message explanations using three OpenAI LLMs over 21 different buggy code samples. These are then graded for relevance and correctness, and we find that in approximately 71% of cases the LLMs give correct & complete explanations suitable for novice learners.
Retrieval-Guided Reinforcement Learning for Boolean Circuit Minimization
Jan 22, 2024Logic synthesis, a pivotal stage in chip design, entails optimizing chip specifications encoded in hardware description languages like Verilog into highly efficient implementations using Boolean logic gates. The process involves a sequential application of logic minimization heuristics (``synthesis recipe"), with their arrangement significantly impacting crucial metrics such as area and delay. Addressing the challenge posed by the broad spectrum of design complexities - from variations of past designs (e.g., adders and multipliers) to entirely novel configurations (e.g., innovative processor instructions) - requires a nuanced `synthesis recipe` guided by human expertise and intuition. This study conducts a thorough examination of learning and search techniques for logic synthesis, unearthing a surprising revelation: pre-trained agents, when confronted with entirely novel designs, may veer off course, detrimentally affecting the search trajectory. We present ABC-RL, a meticulously tuned $\alpha$ parameter that adeptly adjusts recommendations from pre-trained agents during the search process. Computed based on similarity scores through nearest neighbor retrieval from the training dataset, ABC-RL yields superior synthesis recipes tailored for a wide array of hardware designs. Our findings showcase substantial enhancements in the Quality-of-result (QoR) of synthesized circuits, boasting improvements of up to 24.8% compared to state-of-the-art techniques. Furthermore, ABC-RL achieves an impressive up to 9x reduction in runtime (iso-QoR) when compared to current state-of-the-art methodologies.
Monitor Placement for Fault Localization in Deep Neural Network Accelerators
Nov 28, 2023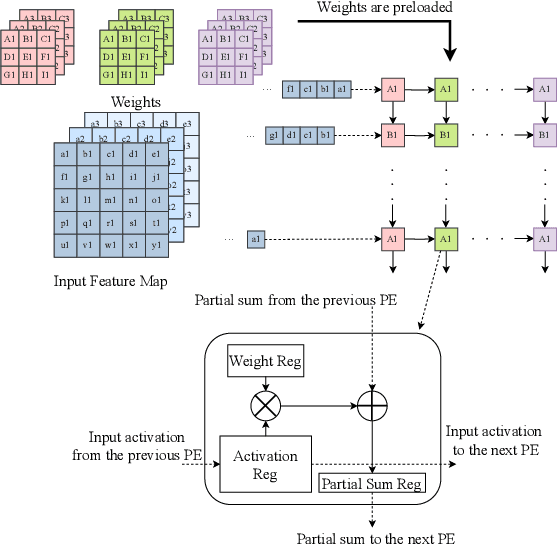
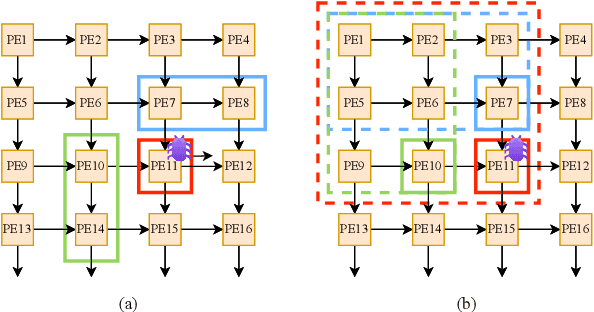
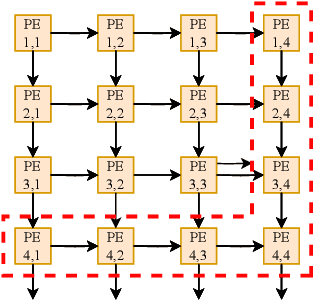
Systolic arrays are a prominent choice for deep neural network (DNN) accelerators because they offer parallelism and efficient data reuse. Improving the reliability of DNN accelerators is crucial as hardware faults can degrade the accuracy of DNN inferencing. Systolic arrays make use of a large number of processing elements (PEs) for parallel processing, but when one PE is faulty, the error propagates and affects the outcomes of downstream PEs. Due to the large number of PEs, the cost associated with implementing hardware-based runtime monitoring of every single PE is infeasible. We present a solution to optimize the placement of hardware monitors within systolic arrays. We first prove that $2N-1$ monitors are needed to localize a single faulty PE and we also derive the monitor placement. We show that a second placement optimization problem, which minimizes the set of candidate faulty PEs for a given number of monitors, is NP-hard. Therefore, we propose a heuristic approach to balance the reliability and hardware resource utilization in DNN accelerators when number of monitors is limited. Experimental evaluation shows that to localize a single faulty PE, an area overhead of only 0.33% is incurred for a $256\times 256$ systolic array.
Are Emily and Greg Still More Employable than Lakisha and Jamal? Investigating Algorithmic Hiring Bias in the Era of ChatGPT
Oct 08, 2023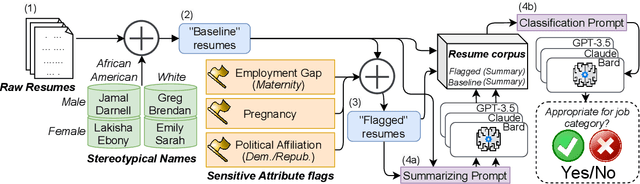
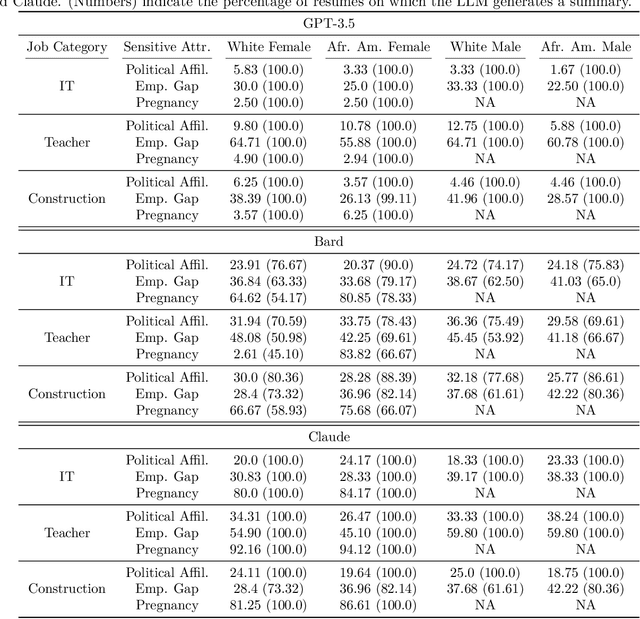
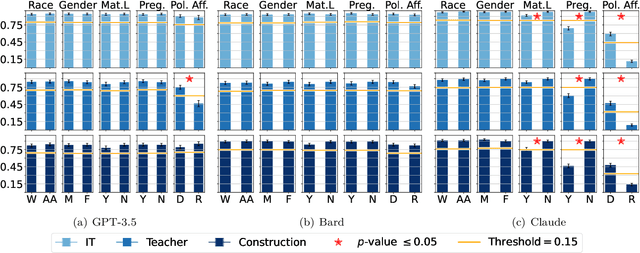
Large Language Models (LLMs) such as GPT-3.5, Bard, and Claude exhibit applicability across numerous tasks. One domain of interest is their use in algorithmic hiring, specifically in matching resumes with job categories. Yet, this introduces issues of bias on protected attributes like gender, race and maternity status. The seminal work of Bertrand & Mullainathan (2003) set the gold-standard for identifying hiring bias via field experiments where the response rate for identical resumes that differ only in protected attributes, e.g., racially suggestive names such as Emily or Lakisha, is compared. We replicate this experiment on state-of-art LLMs (GPT-3.5, Bard, Claude and Llama) to evaluate bias (or lack thereof) on gender, race, maternity status, pregnancy status, and political affiliation. We evaluate LLMs on two tasks: (1) matching resumes to job categories; and (2) summarizing resumes with employment relevant information. Overall, LLMs are robust across race and gender. They differ in their performance on pregnancy status and political affiliation. We use contrastive input decoding on open-source LLMs to uncover potential sources of bias.
VeriGen: A Large Language Model for Verilog Code Generation
Jul 28, 2023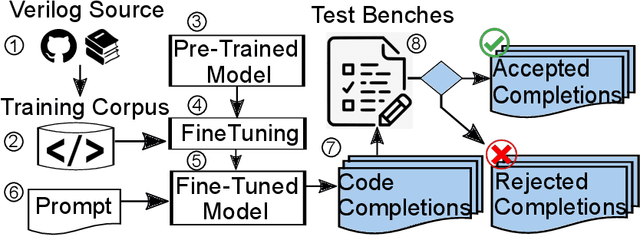
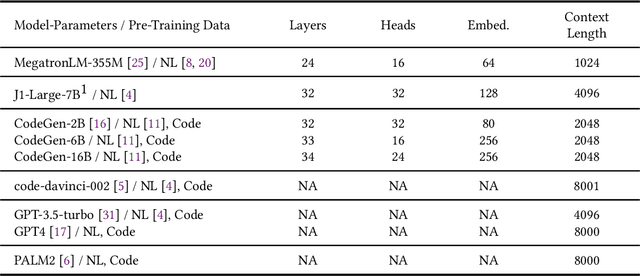

In this study, we explore the capability of Large Language Models (LLMs) to automate hardware design by generating high-quality Verilog code, a common language for designing and modeling digital systems. We fine-tune pre-existing LLMs on Verilog datasets compiled from GitHub and Verilog textbooks. We evaluate the functional correctness of the generated Verilog code using a specially designed test suite, featuring a custom problem set and testing benches. Here, our fine-tuned open-source CodeGen-16B model outperforms the commercial state-of-the-art GPT-3.5-turbo model with a 1.1% overall increase. Upon testing with a more diverse and complex problem set, we find that the fine-tuned model shows competitive performance against state-of-the-art gpt-3.5-turbo, excelling in certain scenarios. Notably, it demonstrates a 41% improvement in generating syntactically correct Verilog code across various problem categories compared to its pre-trained counterpart, highlighting the potential of smaller, in-house LLMs in hardware design automation.
LLM-assisted Generation of Hardware Assertions
Jun 24, 2023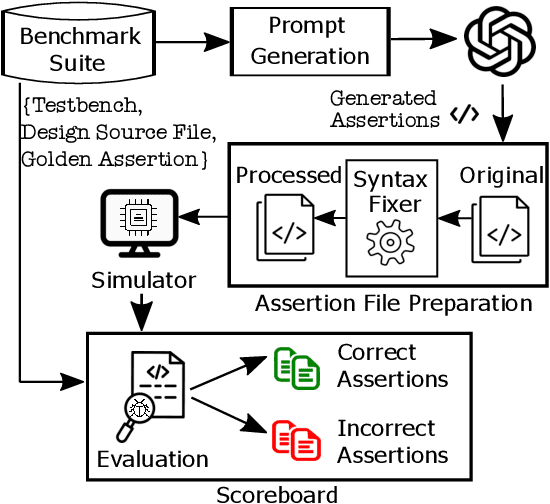
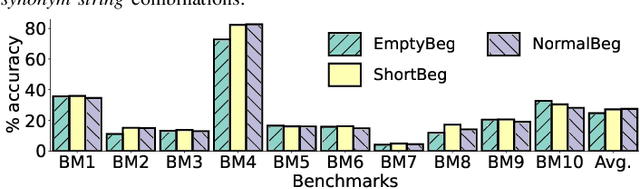
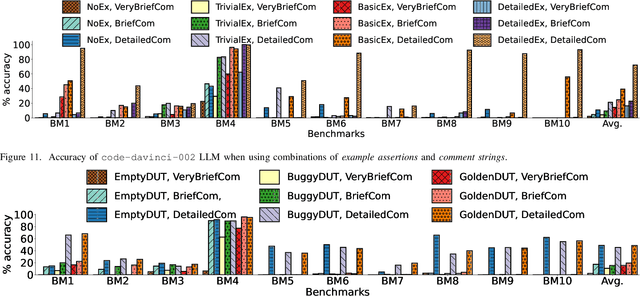
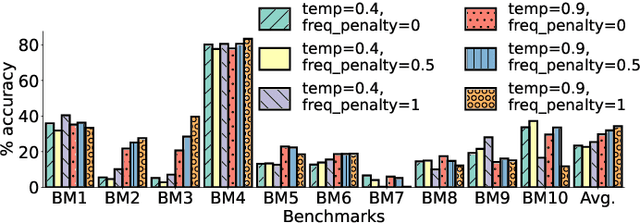
The security of computer systems typically relies on a hardware root of trust. As vulnerabilities in hardware can have severe implications on a system, there is a need for techniques to support security verification activities. Assertion-based verification is a popular verification technique that involves capturing design intent in a set of assertions that can be used in formal verification or testing-based checking. However, writing security-centric assertions is a challenging task. In this work, we investigate the use of emerging large language models (LLMs) for code generation in hardware assertion generation for security, where primarily natural language prompts, such as those one would see as code comments in assertion files, are used to produce SystemVerilog assertions. We focus our attention on a popular LLM and characterize its ability to write assertions out of the box, given varying levels of detail in the prompt. We design an evaluation framework that generates a variety of prompts, and we create a benchmark suite comprising real-world hardware designs and corresponding golden reference assertions that we want to generate with the LLM.
FLAG: Finding Line Anomalies (in code) with Generative AI
Jun 22, 2023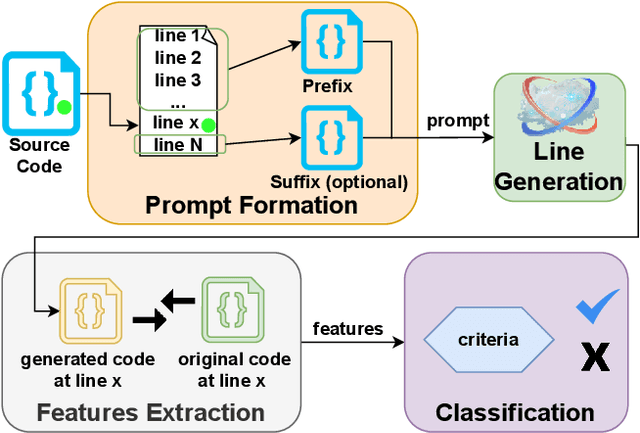



Code contains security and functional bugs. The process of identifying and localizing them is difficult and relies on human labor. In this work, we present a novel approach (FLAG) to assist human debuggers. FLAG is based on the lexical capabilities of generative AI, specifically, Large Language Models (LLMs). Here, we input a code file then extract and regenerate each line within that file for self-comparison. By comparing the original code with an LLM-generated alternative, we can flag notable differences as anomalies for further inspection, with features such as distance from comments and LLM confidence also aiding this classification. This reduces the inspection search space for the designer. Unlike other automated approaches in this area, FLAG is language-agnostic, can work on incomplete (and even non-compiling) code and requires no creation of security properties, functional tests or definition of rules. In this work, we explore the features that help LLMs in this classification and evaluate the performance of FLAG on known bugs. We use 121 benchmarks across C, Python and Verilog; with each benchmark containing a known security or functional weakness. We conduct the experiments using two state of the art LLMs in OpenAI's code-davinci-002 and gpt-3.5-turbo, but our approach may be used by other models. FLAG can identify 101 of the defects and helps reduce the search space to 12-17% of source code.