 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAL-SUMMER: A Structured Evaluation Framework of Hierarchical Errors in Dialogue Summaries
Feb 08, 2026Dialogues are a predominant mode of communication for humans, and it is immensely helpful to have automatically generated summaries of them (e.g., to revise key points discussed in a meeting, to review conversations between customer agents and product users). Prior works on dialogue summary evaluation largely ignore the complexities specific to this task: (i) shift in structure, from multiple speakers discussing information in a scattered fashion across several turns, to a summary's sentences, and (ii) shift in narration viewpoint, from speakers' first/second-person narration, standardized third-person narration in the summary. In this work, we introduce our framework DIALSUMMER to address the above. We propose DIAL-SUMMER's taxonomy of errors to comprehensively evaluate dialogue summaries at two hierarchical levels: DIALOGUE-LEVEL that focuses on the broader speakers/turns, and WITHIN-TURN-LEVEL that focuses on the information talked about inside a turn. We then present DIAL-SUMMER's dataset composed of dialogue summaries manually annotated with our taxonomy's fine-grained errors. We conduct empirical analyses of these annotated errors, and observe interesting trends (e.g., turns occurring in middle of the dialogue are the most frequently missed in the summary, extrinsic hallucinations largely occur at the end of the summary). We also conduct experiments on LLM-Judges' capability at detecting these errors, through which we demonstrate the challenging nature of our dataset, the robustness of our taxonomy, and the need for future work in this field to enhance LLMs' performance in the same. Code and inference dataset coming soon.
Are Emily and Greg Still More Employable than Lakisha and Jamal? Investigating Algorithmic Hiring Bias in the Era of ChatGPT
Oct 08, 2023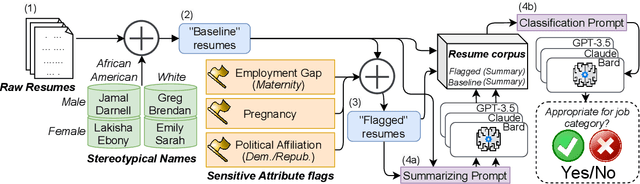
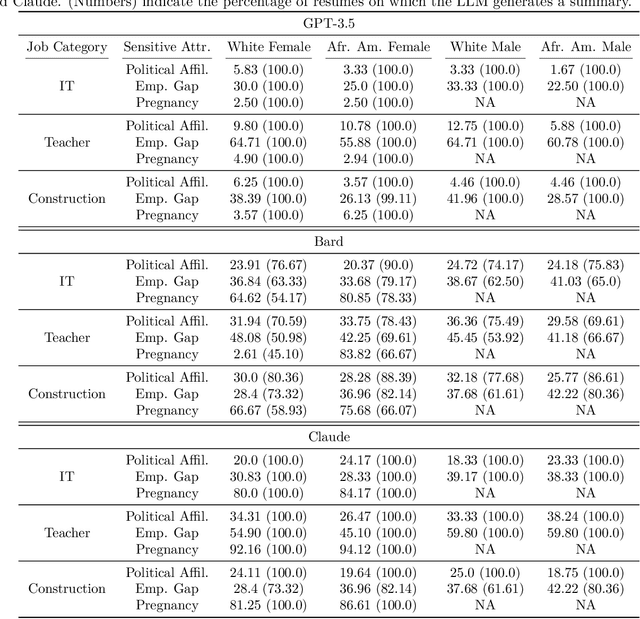
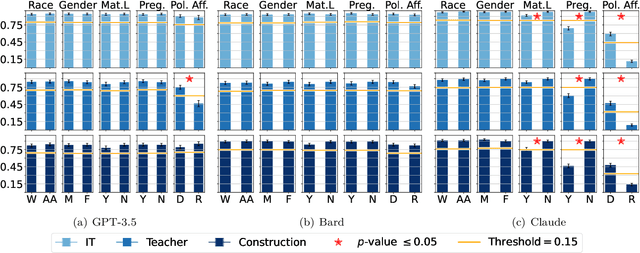
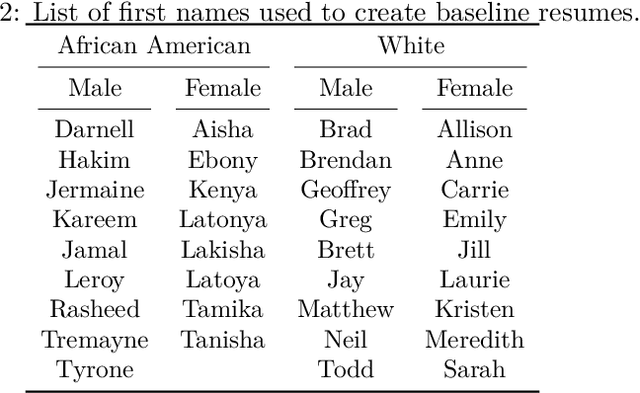
Large Language Models (LLMs) such as GPT-3.5, Bard, and Claude exhibit applicability across numerous tasks. One domain of interest is their use in algorithmic hiring, specifically in matching resumes with job categories. Yet, this introduces issues of bias on protected attributes like gender, race and maternity status. The seminal work of Bertrand & Mullainathan (2003) set the gold-standard for identifying hiring bias via field experiments where the response rate for identical resumes that differ only in protected attributes, e.g., racially suggestive names such as Emily or Lakisha, is compared. We replicate this experiment on state-of-art LLMs (GPT-3.5, Bard, Claude and Llama) to evaluate bias (or lack thereof) on gender, race, maternity status, pregnancy status, and political affiliation. We evaluate LLMs on two tasks: (1) matching resumes to job categories; and (2) summarizing resumes with employment relevant information. Overall, LLMs are robust across race and gender. They differ in their performance on pregnancy status and political affiliation. We use contrastive input decoding on open-source LLMs to uncover potential sources of bias.
Application of BadNets in Spam Filters
Jul 18, 2023



Spam filters are a crucial component of modern email systems, as they help to protect users from unwanted and potentially harmful emails. However, the effectiveness of these filters is dependent on the quality of the machine learning models that power them. In this paper, we design backdoor attacks in the domain of spam filtering. By demonstrating the potential vulnerabilities in the machine learning model supply chain, we highlight the need for careful consideration and evaluation of the models used in spam filters. Our results show that the backdoor attacks can be effectively used to identify vulnerabilities in spam filters and suggest the need for ongoing monitoring and improvement in this area.
Path Planning Under Uncertainty to Localize mmWave Sources
Mar 08, 2023
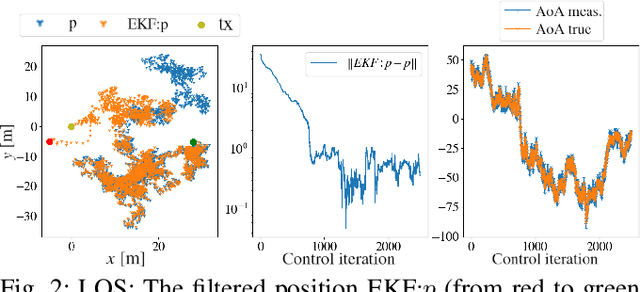

In this paper, we study a navigation problem where a mobile robot needs to locate a mmWave wireless signal. Using the directionality properties of the signal, we propose an estimation and path planning algorithm that can efficiently navigate in cluttered indoor environments. We formulate Extended Kalman filters for emitter location estimation in cases where the signal is received in line-of-sight or after reflections. We then propose to plan motion trajectories based on belief-space dynamics in order to minimize the uncertainty of the position estimates. The associated non-linear optimization problem is solved by a state-of-the-art constrained iLQR solver. In particular, we propose a method that can handle a large number of obstacles (~300) with reasonable computation times. We validate the approach in an extensive set of simulations. We show that our estimators can help increase navigation success rate and that planning to reduce estimation uncertainty can improve the overall task completion speed.
Hyper-parameter Tuning for Fair Classification without Sensitive Attribute Access
Feb 02, 2023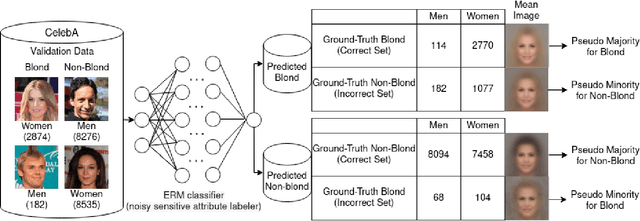

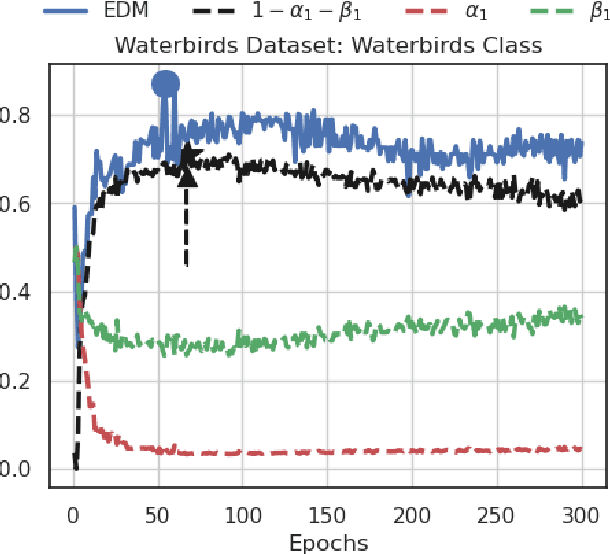

Fair machine learning methods seek to train models that balance model performance across demographic subgroups defined over sensitive attributes like race and gender. Although sensitive attributes are typically assumed to be known during training, they may not be available in practice due to privacy and other logistical concerns. Recent work has sought to train fair models without sensitive attributes on training data. However, these methods need extensive hyper-parameter tuning to achieve good results, and hence assume that sensitive attributes are known on validation data. However, this assumption too might not be practical. Here, we propose Antigone, a framework to train fair classifiers without access to sensitive attributes on either training or validation data. Instead, we generate pseudo sensitive attributes on the validation data by training a biased classifier and using the classifier's incorrectly (correctly) labeled examples as proxies for minority (majority) groups. Since fairness metrics like demographic parity, equal opportunity and subgroup accuracy can be estimated to within a proportionality constant even with noisy sensitive attribute information, we show theoretically and empirically that these proxy labels can be used to maximize fairness under average accuracy constraints. Key to our results is a principled approach to select the hyper-parameters of the biased classifier in a completely unsupervised fashion (meaning without access to ground truth sensitive attributes) that minimizes the gap between fairness estimated using noisy versus ground-truth sensitive labels.
Fairness via In-Processing in the Over-parameterized Regime: A Cautionary Tale
Jun 29, 2022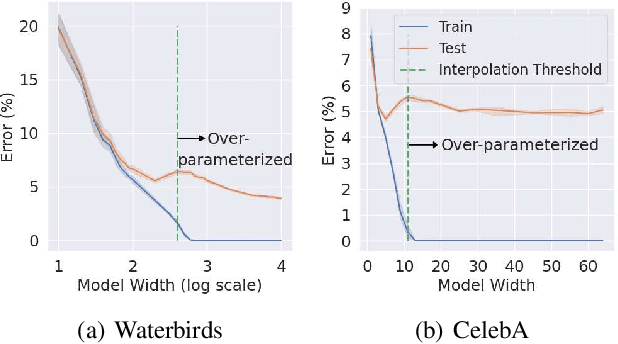
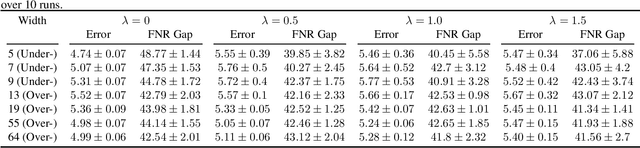
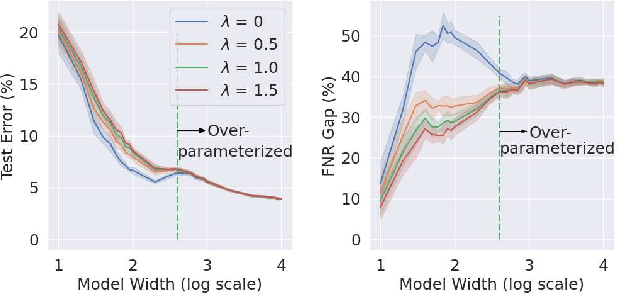

The success of DNNs is driven by the counter-intuitive ability of over-parameterized networks to generalize, even when they perfectly fit the training data. In practice, test error often continues to decrease with increasing over-parameterization, referred to as double descent. This allows practitioners to instantiate large models without having to worry about over-fitting. Despite its benefits, however, prior work has shown that over-parameterization can exacerbate bias against minority subgroups. Several fairness-constrained DNN training methods have been proposed to address this concern. Here, we critically examine MinDiff, a fairness-constrained training procedure implemented within TensorFlow's Responsible AI Toolkit, that aims to achieve Equality of Opportunity. We show that although MinDiff improves fairness for under-parameterized models, it is likely to be ineffective in the over-parameterized regime. This is because an overfit model with zero training loss is trivially group-wise fair on training data, creating an "illusion of fairness," thus turning off the MinDiff optimization (this will apply to any disparity-based measures which care about errors or accuracy. It won't apply to demographic parity). Within specified fairness constraints, under-parameterized MinDiff models can even have lower error compared to their over-parameterized counterparts (despite baseline over-parameterized models having lower error). We further show that MinDiff optimization is very sensitive to choice of batch size in the under-parameterized regime. Thus, fair model training using MinDiff requires time-consuming hyper-parameter searches. Finally, we suggest using previously proposed regularization techniques, viz. L2, early stopping and flooding in conjunction with MinDiff to train fair over-parameterized models.
Detecting Backdoors in Neural Networks Using Novel Feature-Based Anomaly Detection
Nov 04, 2020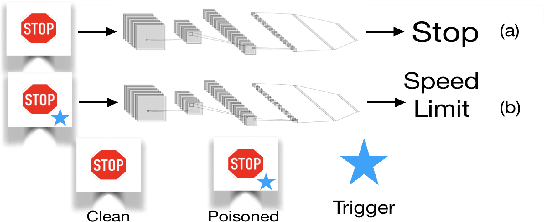
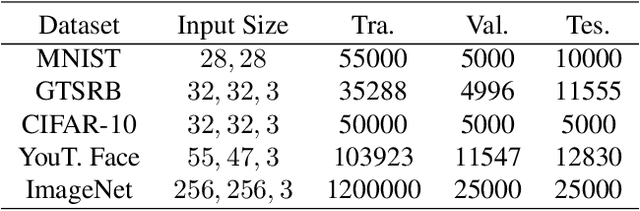
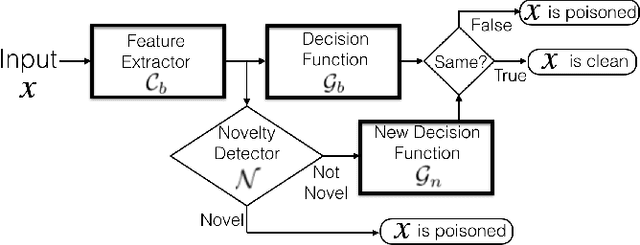
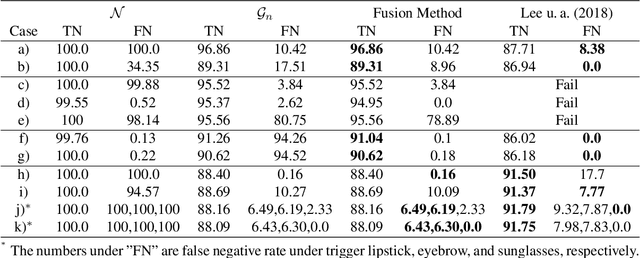
This paper proposes a new defense against neural network backdooring attacks that are maliciously trained to mispredict in the presence of attacker-chosen triggers. Our defense is based on the intuition that the feature extraction layers of a backdoored network embed new features to detect the presence of a trigger and the subsequent classification layers learn to mispredict when triggers are detected. Therefore, to detect backdoors, the proposed defense uses two synergistic anomaly detectors trained on clean validation data: the first is a novelty detector that checks for anomalous features, while the second detects anomalous mappings from features to outputs by comparing with a separate classifier trained on validation data. The approach is evaluated on a wide range of backdoored networks (with multiple variations of triggers) that successfully evade state-of-the-art defenses. Additionally, we evaluate the robustness of our approach on imperceptible perturbations, scalability on large-scale datasets, and effectiveness under domain shift. This paper also shows that the defense can be further improved using data augmentation.
NNoculation: Broad Spectrum and Targeted Treatment of Backdoored DNNs
Feb 19, 2020



This paper proposes a novel two-stage defense (NNoculation) against backdoored neural networks (BadNets) that, unlike existing defenses, makes minimal assumptions on the shape, size and location of backdoor triggers and BadNet's functioning. In the pre-deployment stage, NNoculation retrains the network using "broad-spectrum" random perturbations of inputs drawn from a clean validation set to partially reduce the adversarial impact of a backdoor. In the post-deployment stage, NNoculation detects and quarantines backdoored test inputs by recording disagreements between the original and pre-deployment patched networks. A CycleGAN is then trained to learn transformations between clean validation inputs and quarantined inputs; i.e., it learns to add triggers to clean validation images. This transformed set of backdoored validation images along with their correct labels is used to further retrain the BadNet, yielding our final defense. NNoculation outperforms state-of-the-art defenses NeuralCleanse and Artificial Brain Simulation (ABS) that we show are ineffective when their restrictive assumptions are circumvented by the attacker.