 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 4D Representation for Training-Free Agentic Reasoning from Monocular Laparoscopic Video
Apr 01, 2026Spatiotemporal reasoning is a fundamental capability for artificial intelligence (AI) in soft tissue surgery, paving the way for intelligent assistive systems and autonomous robotics. While 2D vision-language models show increasing promise at understanding surgical video, the spatial complexity of surgical scenes suggests that reasoning systems may benefit from explicit 4D representations. Here, we propose a framework for equipping surgical agents with spatiotemporal tools based on an explicit 4D representation, enabling AI systems to ground their natural language reasoning in both time and 3D space. Leveraging models for point tracking, depth, and segmentation, we develop a coherent 4D model with spatiotemporally consistent tool and tissue semantics. A Multimodal Large Language Model (MLLM) then acts as an agent on tools derived from the explicit 4D representation (e.g., trajectories) without any fine-tuning. We evaluate our method on a new dataset of 134 clinically relevant questions and find that the combination of a general purpose reasoning backbone and our 4D representation significantly improves spatiotemporal understanding and allows for 4D grounding. We demonstrate that spatiotemporal intelligence can be "assembled" from 2D MLLMs and 3D computer vision models without additional training. Code, data, and examples are available at https://tum-ai.github.io/surg4d/
Accumulator-Aware Post-Training Quantization
Sep 25, 2024Several recent studies have investigated low-precision accumulation, reporting improvements in throughput, power, and area across various platforms. However, the accompanying proposals have only considered the quantization-aware training (QAT) paradigm, in which models are fine-tuned or trained from scratch with quantization in the loop. As models continue to grow in size, QAT techniques become increasingly more expensive, which has motivated the recent surge in post-training quantization (PTQ) research. To the best of our knowledge, ours marks the first formal study of accumulator-aware quantization in the PTQ setting. To bridge this gap, we introduce AXE, a practical framework of accumulator-aware extensions designed to endow overflow avoidance guarantees to existing layer-wise PTQ algorithms. We theoretically motivate AXE and demonstrate its flexibility by implementing it on top of two state-of-the-art PTQ algorithms: GPFQ and OPTQ. We further generalize AXE to support multi-stage accumulation for the first time, opening the door for full datapath optimization and scaling to large language models (LLMs). We evaluate AXE across image classification and language generation models, and observe significant improvements in the trade-off between accumulator bit width and model accuracy over baseline methods.
Are Emily and Greg Still More Employable than Lakisha and Jamal? Investigating Algorithmic Hiring Bias in the Era of ChatGPT
Oct 08, 2023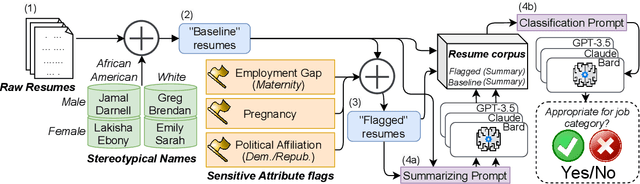
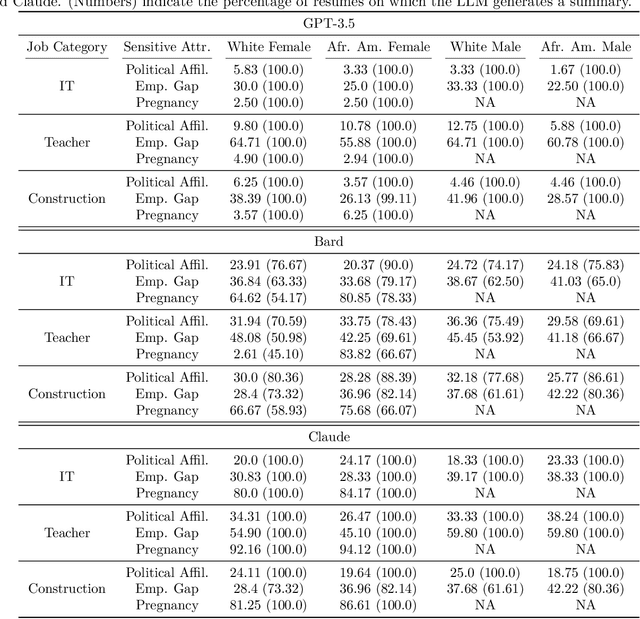
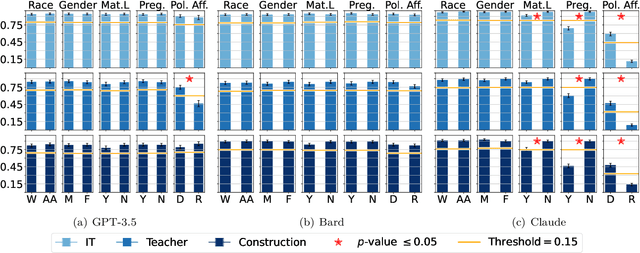
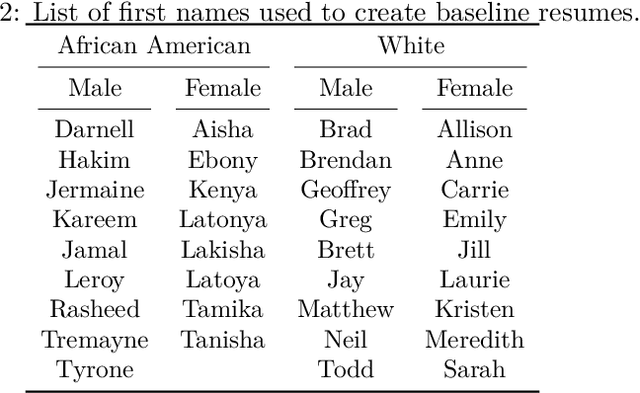
Large Language Models (LLMs) such as GPT-3.5, Bard, and Claude exhibit applicability across numerous tasks. One domain of interest is their use in algorithmic hiring, specifically in matching resumes with job categories. Yet, this introduces issues of bias on protected attributes like gender, race and maternity status. The seminal work of Bertrand & Mullainathan (2003) set the gold-standard for identifying hiring bias via field experiments where the response rate for identical resumes that differ only in protected attributes, e.g., racially suggestive names such as Emily or Lakisha, is compared. We replicate this experiment on state-of-art LLMs (GPT-3.5, Bard, Claude and Llama) to evaluate bias (or lack thereof) on gender, race, maternity status, pregnancy status, and political affiliation. We evaluate LLMs on two tasks: (1) matching resumes to job categories; and (2) summarizing resumes with employment relevant information. Overall, LLMs are robust across race and gender. They differ in their performance on pregnancy status and political affiliation. We use contrastive input decoding on open-source LLMs to uncover potential sources of bias.