 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTQ-intrinsic LoRA: A Near-optimal Algorithm for Low-precision Quantization with Low-rank Adaptation
May 31, 2026Post-training quantization is widely used for compressing large neural networks, but aggressive low-bit quantization can significantly degrade model quality. A common remedy is to augment the quantized weights with a low-rank correction, leading to approximations of the form $W\approx Q+LR$. In this paper, we study this low-precision plus low-rank representation through the layer-wise reconstruction objective $\|XW-X(Q+LR)\|_F^2$, where $X$ is a calibration matrix. We establish, to our knowledge, the first information-theoretic lower bounds for this problem under finite-alphabet and bounded low-rank compensation constraints. We then propose GPTQ-intrinsic LoRA, a training-free algorithm that incorporates the low-rank correction directly into a GPTQ-style quantization pass by appropriately augmenting the calibration Hessian. For the choice $L=V_r$, where $V_r$ contains the top right singular vectors of $X$, we prove layer-wise reconstruction error bounds in which the usual GPTQ dependence on $\|X\|_F^2$ is replaced by the rank-$r$ residual $\|X-X_r\|_F^2$, up to regularization terms. Under natural structural assumptions, these bounds match the information-theoretic lower bounds in their dominant scaling, up to constants and mild factors. We also introduce Bid-Up, a fixed-grid quantization refinement step that can be alternated with optimal low-rank compensation with guaranteed non-increasing layer-wise reconstruction error. Experiments on Qwen3 language models and DeiT vision transformers show that GPTQ-intrinsic LoRA improves over GPTQ and GPTQ followed by low-rank compensation, with additional gains from refinement loops.
Low-Bit Quantization of Bandlimited Graph Signals via Iterative Methods
Jan 26, 2026We study the quantization of real-valued bandlimited signals on graphs, focusing on low-bit representations. We propose iterative noise-shaping algorithms for quantization, including sampling approaches with and without vertex replacement. The methods leverage the spectral properties of the graph Laplacian and exploit graph incoherence to achieve high-fidelity approximations. Theoretical guarantees are provided for the random sampling method, and extensive numerical experiments on synthetic and real-world graphs illustrate the efficiency and robustness of the proposed schemes.
Provable Post-Training Quantization: Theoretical Analysis of OPTQ and Qronos
Aug 06, 2025Post-training quantization (PTQ) has become a crucial tool for reducing the memory and compute costs of modern deep neural networks, including large language models (LLMs). Among PTQ algorithms, the OPTQ framework-also known as GPTQ-has emerged as a leading method due to its computational efficiency and strong empirical performance. Despite its widespread adoption, however, OPTQ lacks rigorous quantitative theoretical guarantees. This paper presents the first quantitative error bounds for both deterministic and stochastic variants of OPTQ, as well as for Qronos, a recent related state-of-the-art PTQ algorithm. We analyze how OPTQ's iterative procedure induces quantization error and derive non-asymptotic 2-norm error bounds that depend explicitly on the calibration data and a regularization parameter that OPTQ uses. Our analysis provides theoretical justification for several practical design choices, including the widely used heuristic of ordering features by decreasing norm, as well as guidance for selecting the regularization parameter. For the stochastic variant, we establish stronger infinity-norm error bounds, which enable control over the required quantization alphabet and are particularly useful for downstream layers and nonlinearities. Finally, we extend our analysis to Qronos, providing new theoretical bounds, for both its deterministic and stochastic variants, that help explain its empirical advantages.
Qronos: Correcting the Past by Shaping the Future... in Post-Training Quantization
May 16, 2025We introduce Qronos -- a new state-of-the-art post-training quantization algorithm that sequentially rounds and updates neural network weights. Qronos not only explicitly corrects errors due to both weight and activation quantization, but also errors resulting from quantizing previous layers. Our iterative algorithm is based on an interpretable and disciplined optimization framework that subsumes and surpasses existing data-driven approaches. At each step, Qronos alternates between error correction and diffusion via optimal update rules. Importantly, we prove that Qronos admits an efficient implementation that uses the Cholesky decomposition for solving least-squares problems. We also demonstrate that Qronos is compatible with existing transformation techniques such as Hadamard-based incoherence processing and weight-activation scaling equalization, among others. We evaluate Qronos using recent autoregressive language generation models in the Llama3 family; Qronos consistently outperforms previous state-of-the-art adaptive rounding methods when quantizing the weights, activations, and/or KV caches.
Theoretical Guarantees for Low-Rank Compression of Deep Neural Networks
Feb 04, 2025Deep neural networks have achieved state-of-the-art performance across numerous applications, but their high memory and computational demands present significant challenges, particularly in resource-constrained environments. Model compression techniques, such as low-rank approximation, offer a promising solution by reducing the size and complexity of these networks while only minimally sacrificing accuracy. In this paper, we develop an analytical framework for data-driven post-training low-rank compression. We prove three recovery theorems under progressively weaker assumptions about the approximate low-rank structure of activations, modeling deviations via noise. Our results represent a step toward explaining why data-driven low-rank compression methods outperform data-agnostic approaches and towards theoretically grounded compression algorithms that reduce inference costs while maintaining performance.
Unified Stochastic Framework for Neural Network Quantization and Pruning
Dec 24, 2024Quantization and pruning are two essential techniques for compressing neural networks, yet they are often treated independently, with limited theoretical analysis connecting them. This paper introduces a unified framework for post-training quantization and pruning using stochastic path-following algorithms. Our approach builds on the Stochastic Path Following Quantization (SPFQ) method, extending its applicability to pruning and low-bit quantization, including challenging 1-bit regimes. By incorporating a scaling parameter and generalizing the stochastic operator, the proposed method achieves robust error correction and yields rigorous theoretical error bounds for both quantization and pruning as well as their combination.
Accumulator-Aware Post-Training Quantization
Sep 25, 2024Several recent studies have investigated low-precision accumulation, reporting improvements in throughput, power, and area across various platforms. However, the accompanying proposals have only considered the quantization-aware training (QAT) paradigm, in which models are fine-tuned or trained from scratch with quantization in the loop. As models continue to grow in size, QAT techniques become increasingly more expensive, which has motivated the recent surge in post-training quantization (PTQ) research. To the best of our knowledge, ours marks the first formal study of accumulator-aware quantization in the PTQ setting. To bridge this gap, we introduce AXE, a practical framework of accumulator-aware extensions designed to endow overflow avoidance guarantees to existing layer-wise PTQ algorithms. We theoretically motivate AXE and demonstrate its flexibility by implementing it on top of two state-of-the-art PTQ algorithms: GPFQ and OPTQ. We further generalize AXE to support multi-stage accumulation for the first time, opening the door for full datapath optimization and scaling to large language models (LLMs). We evaluate AXE across image classification and language generation models, and observe significant improvements in the trade-off between accumulator bit width and model accuracy over baseline methods.
SPFQ: A Stochastic Algorithm and Its Error Analysis for Neural Network Quantization
Sep 20, 2023

Quantization is a widely used compression method that effectively reduces redundancies in over-parameterized neural networks. However, existing quantization techniques for deep neural networks often lack a comprehensive error analysis due to the presence of non-convex loss functions and nonlinear activations. In this paper, we propose a fast stochastic algorithm for quantizing the weights of fully trained neural networks. Our approach leverages a greedy path-following mechanism in combination with a stochastic quantizer. Its computational complexity scales only linearly with the number of weights in the network, thereby enabling the efficient quantization of large networks. Importantly, we establish, for the first time, full-network error bounds, under an infinite alphabet condition and minimal assumptions on the weights and input data. As an application of this result, we prove that when quantizing a multi-layer network having Gaussian weights, the relative square quantization error exhibits a linear decay as the degree of over-parametrization increases. Furthermore, we demonstrate that it is possible to achieve error bounds equivalent to those obtained in the infinite alphabet case, using on the order of a mere $\log\log N$ bits per weight, where $N$ represents the largest number of neurons in a layer.
A simple approach for quantizing neural networks
Sep 07, 2022In this short note, we propose a new method for quantizing the weights of a fully trained neural network. A simple deterministic pre-processing step allows us to quantize network layers via memoryless scalar quantization while preserving the network performance on given training data. On one hand, the computational complexity of this pre-processing slightly exceeds that of state-of-the-art algorithms in the literature. On the other hand, our approach does not require any hyper-parameter tuning and, in contrast to previous methods, allows a plain analysis. We provide rigorous theoretical guarantees in the case of quantizing single network layers and show that the relative error decays with the number of parameters in the network if the training data behaves well, e.g., if it is sampled from suitable random distributions. The developed method also readily allows the quantization of deep networks by consecutive application to single layers.
Spectrally Adaptive Common Spatial Patterns
Feb 09, 2022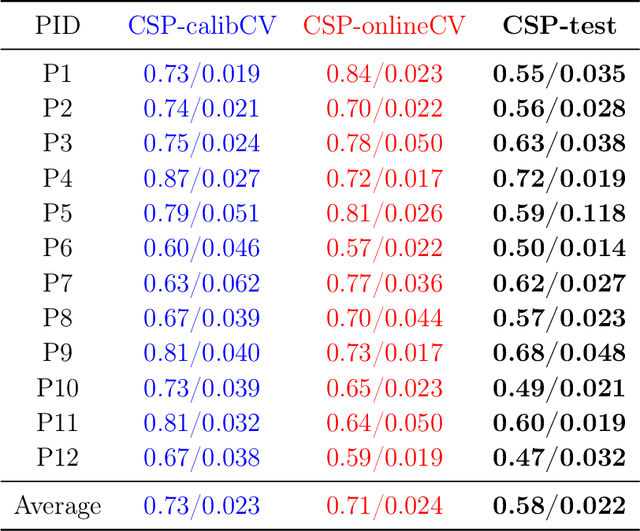
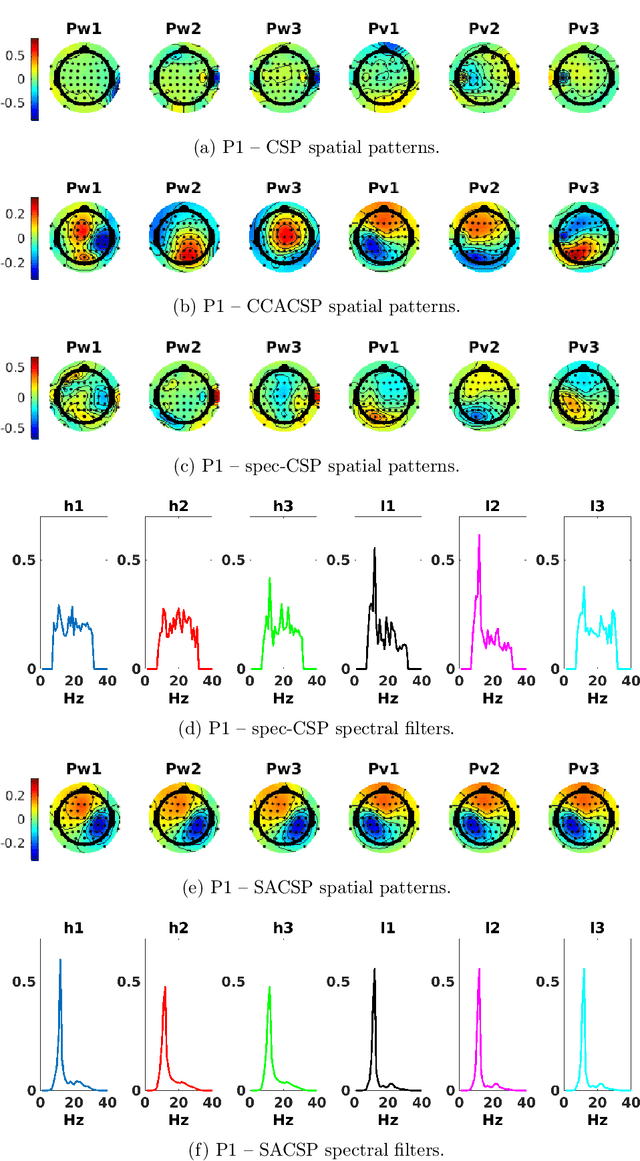
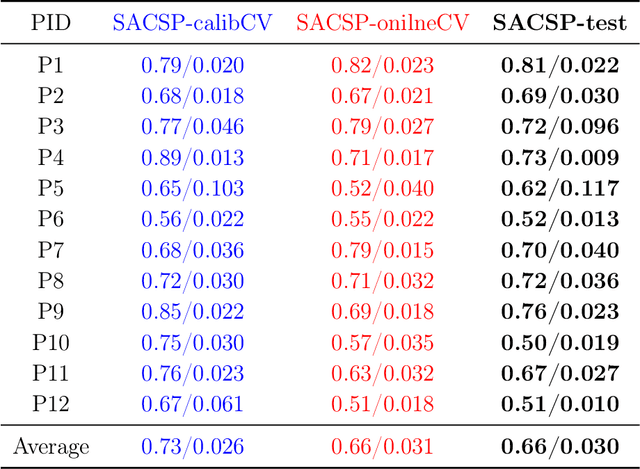
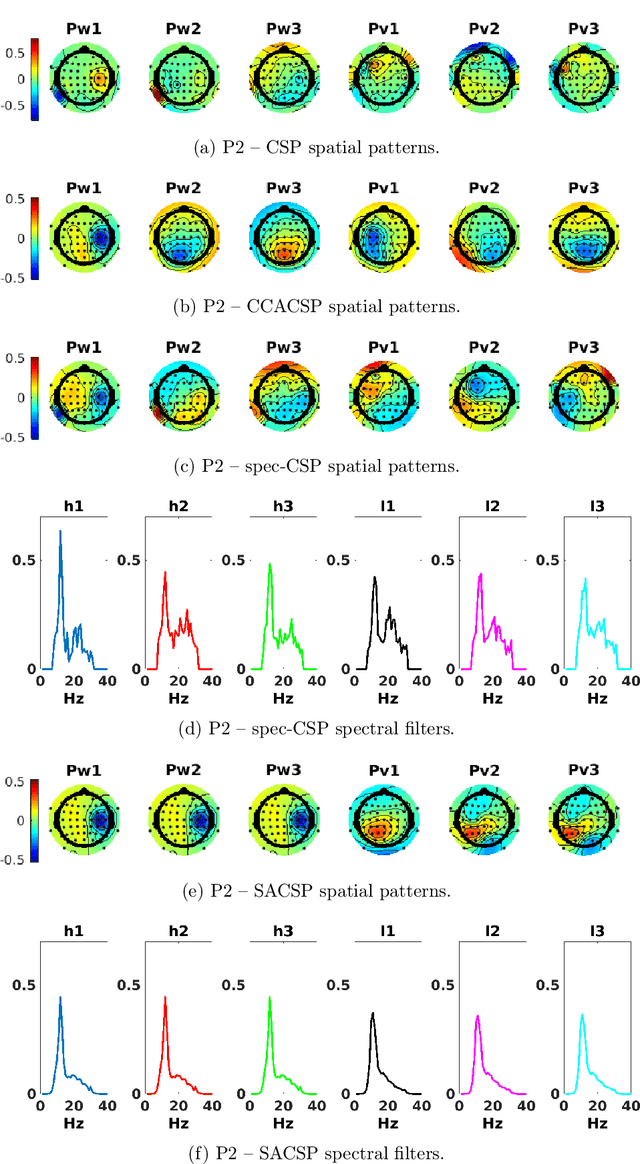
The method of Common Spatial Patterns (CSP) is widely used for feature extraction of electroencephalography (EEG) data, such as in motor imagery brain-computer interface (BCI) systems. It is a data-driven method estimating a set of spatial filters so that the power of the filtered EEG signal is maximized for one motor imagery class and minimized for the other. This method, however, is prone to overfitting and is known to suffer from poor generalization especially with limited calibration data. Additionally, due to the high heterogeneity in brain data and the non-stationarity of brain activity, CSP is usually trained for each user separately resulting in long calibration sessions or frequent re-calibrations that are tiring for the user. In this work, we propose a novel algorithm called Spectrally Adaptive Common Spatial Patterns (SACSP) that improves CSP by learning a temporal/spectral filter for each spatial filter so that the spatial filters are concentrated on the most relevant temporal frequencies for each user. We show the efficacy of SACSP in providing better generalizability and higher classification accuracy from calibration to online control compared to existing methods. Furthermore, we show that SACSP provides neurophysiologically relevant information about the temporal frequencies of the filtered signals. Our results highlight the differences in the motor imagery signal among BCI users as well as spectral differences in the signals generated for each class, and show the importance of learning robust user-specific features in a data-driven manner.