 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Inductive Bias of Convolutional Neural Networks: Locality and Weight Sharing Reshape Implicit Regularization
Mar 05, 2026We study how architectural inductive bias reshapes the implicit regularization induced by the edge-of-stability phenomenon in gradient descent. Prior work has established that for fully connected networks, the strength of this regularization is governed solely by the global input geometry; consequently, it is insufficient to prevent overfitting on difficult distributions such as the high-dimensional sphere. In this paper, we show that locality and weight sharing fundamentally change this picture. Specifically, we prove that provided the receptive field size $m$ remains small relative to the ambient dimension $d$, these networks generalize on spherical data with a rate of $n^{-\frac{1}{6} +O(m/d)}$, a regime where fully connected networks provably fail. This theoretical result confirms that weight sharing couples the learned filters to the low-dimensional patch manifold, thereby bypassing the high dimensionality of the ambient space. We further corroborate our theory by analyzing the patch geometry of natural images, showing that standard convolutional designs induce patch distributions that are highly amenable to this stability mechanism, thus providing a systematic explanation for the superior generalization of convolutional networks over fully connected baselines.
Robust Tangent Space Estimation via Laplacian Eigenvector Gradient Orthogonalization
Oct 02, 2025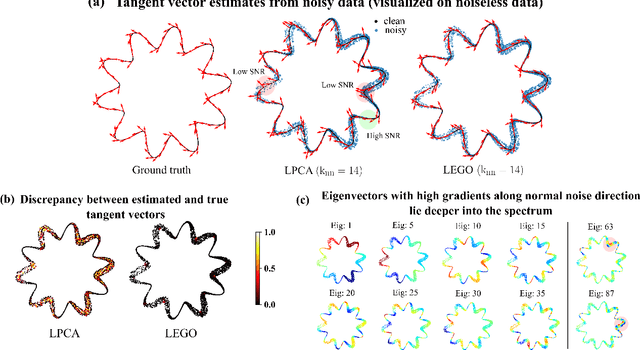
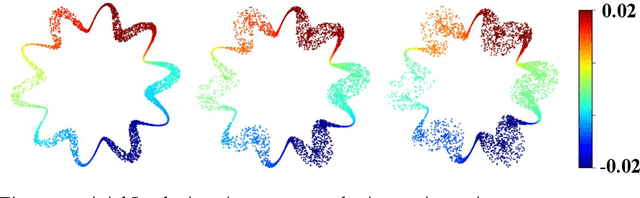
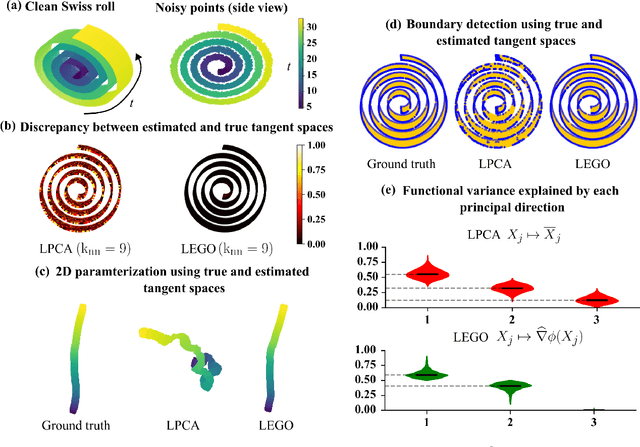
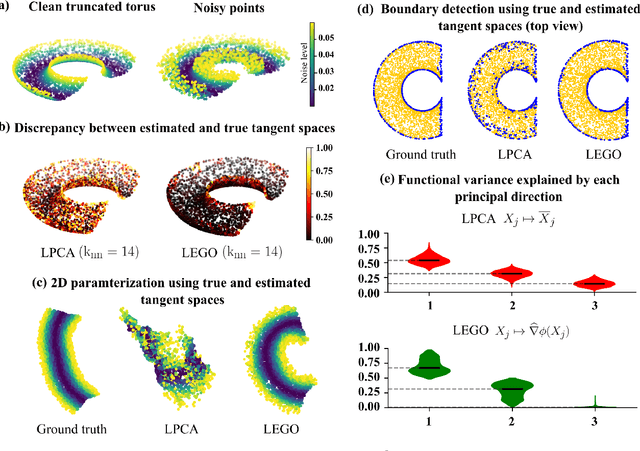
Estimating the tangent spaces of a data manifold is a fundamental problem in data analysis. The standard approach, Local Principal Component Analysis (LPCA), struggles in high-noise settings due to a critical trade-off in choosing the neighborhood size. Selecting an optimal size requires prior knowledge of the geometric and noise characteristics of the data that are often unavailable. In this paper, we propose a spectral method, Laplacian Eigenvector Gradient Orthogonalization (LEGO), that utilizes the global structure of the data to guide local tangent space estimation. Instead of relying solely on local neighborhoods, LEGO estimates the tangent space at each data point by orthogonalizing the gradients of low-frequency eigenvectors of the graph Laplacian. We provide two theoretical justifications of our method. First, a differential geometric analysis on a tubular neighborhood of a manifold shows that gradients of the low-frequency Laplacian eigenfunctions of the tube align closely with the manifold's tangent bundle, while an eigenfunction with high gradient in directions orthogonal to the manifold lie deeper in the spectrum. Second, a random matrix theoretic analysis also demonstrates that low-frequency eigenvectors are robust to sub-Gaussian noise. Through comprehensive experiments, we demonstrate that LEGO yields tangent space estimates that are significantly more robust to noise than those from LPCA, resulting in marked improvements in downstream tasks such as manifold learning, boundary detection, and local intrinsic dimension estimation.
Transformers for Learning on Noisy and Task-Level Manifolds: Approximation and Generalization Insights
May 06, 2025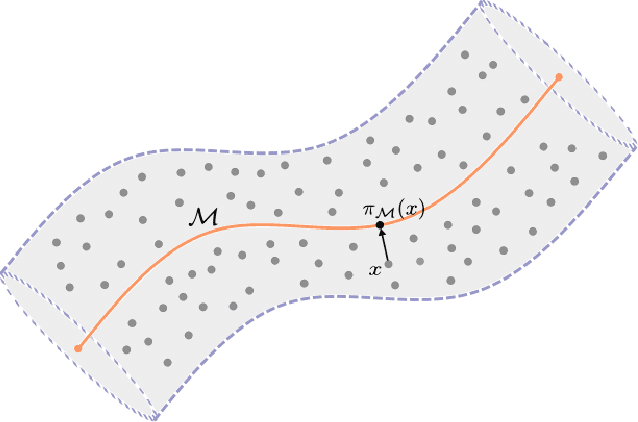
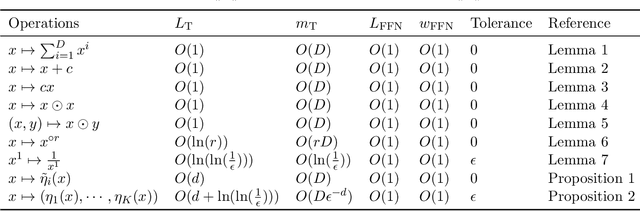


Transformers serve as the foundational architecture for large language and video generation models, such as GPT, BERT, SORA and their successors. Empirical studies have demonstrated that real-world data and learning tasks exhibit low-dimensional structures, along with some noise or measurement error. The performance of transformers tends to depend on the intrinsic dimension of the data/tasks, though theoretical understandings remain largely unexplored for transformers. This work establishes a theoretical foundation by analyzing the performance of transformers for regression tasks involving noisy input data on a manifold. Specifically, the input data are in a tubular neighborhood of a manifold, while the ground truth function depends on the projection of the noisy data onto the manifold. We prove approximation and generalization errors which crucially depend on the intrinsic dimension of the manifold. Our results demonstrate that transformers can leverage low-complexity structures in learning task even when the input data are perturbed by high-dimensional noise. Our novel proof technique constructs representations of basic arithmetic operations by transformers, which may hold independent interest.
Robust Graph-Based Semi-Supervised Learning via $p$-Conductances
Feb 13, 2025We study the problem of semi-supervised learning on graphs in the regime where data labels are scarce or possibly corrupted. We propose an approach called $p$-conductance learning that generalizes the $p$-Laplace and Poisson learning methods by introducing an objective reminiscent of $p$-Laplacian regularization and an affine relaxation of the label constraints. This leads to a family of probability measure mincut programs that balance sparse edge removal with accurate distribution separation. Our theoretical analysis connects these programs to well-known variational and probabilistic problems on graphs (including randomized cuts, effective resistance, and Wasserstein distance) and provides motivation for robustness when labels are diffused via the heat kernel. Computationally, we develop a semismooth Newton-conjugate gradient algorithm and extend it to incorporate class-size estimates when converting the continuous solutions into label assignments. Empirical results on computer vision and citation datasets demonstrate that our approach achieves state-of-the-art accuracy in low label-rate, corrupted-label, and partial-label regimes.
Linearized Optimal Transport pyLOT Library: A Toolkit for Machine Learning on Point Clouds
Feb 05, 2025



The pyLOT library offers a Python implementation of linearized optimal transport (LOT) techniques and methods to use in downstream tasks. The pipeline embeds probability distributions into a Hilbert space via the Optimal Transport maps from a fixed reference distribution, and this linearization allows downstream tasks to be completed using off the shelf (linear) machine learning algorithms. We provide a case study of performing ML on 3D scans of lemur teeth, where the original questions of classification, clustering, dimension reduction, and data generation reduce to simple linear operations performed on the LOT embedded representations.
Using Linearized Optimal Transport to Predict the Evolution of Stochastic Particle Systems
Aug 03, 2024



We develop an algorithm to approximate the time evolution of a probability measure without explicitly learning an operator that governs the evolution. A particular application of interest is discrete measures $\mu_t^N$ that arise from particle systems. In many such situations, the individual particles move chaotically on short time scales, making it difficult to learn the dynamics of a governing operator, but the bulk distribution $\mu_t^N$ approximates an absolutely continuous measure $\mu_t$ that evolves ``smoothly.'' If $\mu_t$ is known on some time interval, then linearized optimal transport theory provides an Euler-like scheme for approximating the evolution of $\mu_t$ using its ``tangent vector field'' (represented as a time-dependent vector field on $\mathbb R^d$), which can be computed as a limit of optimal transport maps. We propose an analog of this Euler approximation to predict the evolution of the discrete measure $\mu_t^N$ (without knowing $\mu_t$). To approximate the analogous tangent vector field, we use a finite difference over a time step that sits between the two time scales of the system -- long enough for the large-$N$ evolution ($\mu_t$) to emerge but short enough to satisfactorily approximate the derivative object used in the Euler scheme. By allowing the limiting behavior to emerge, the optimal transport maps closely approximate the vector field describing the bulk distribution's smooth evolution instead of the individual particles' more chaotic movements. We demonstrate the efficacy of this approach with two illustrative examples, Gaussian diffusion and a cell chemotaxis model, and show that our method succeeds in predicting the bulk behavior over relatively large steps.
Training Guarantees of Neural Network Classification Two-Sample Tests by Kernel Analysis
Jul 09, 2024



We construct and analyze a neural network two-sample test to determine whether two datasets came from the same distribution (null hypothesis) or not (alternative hypothesis). We perform time-analysis on a neural tangent kernel (NTK) two-sample test. In particular, we derive the theoretical minimum training time needed to ensure the NTK two-sample test detects a deviation-level between the datasets. Similarly, we derive the theoretical maximum training time before the NTK two-sample test detects a deviation-level. By approximating the neural network dynamics with the NTK dynamics, we extend this time-analysis to the realistic neural network two-sample test generated from time-varying training dynamics and finite training samples. A similar extension is done for the neural network two-sample test generated from time-varying training dynamics but trained on the population. To give statistical guarantees, we show that the statistical power associated with the neural network two-sample test goes to 1 as the neural network training samples and test evaluation samples go to infinity. Additionally, we prove that the training times needed to detect the same deviation-level in the null and alternative hypothesis scenarios are well-separated. Finally, we run some experiments showcasing a two-layer neural network two-sample test on a hard two-sample test problem and plot a heatmap of the statistical power of the two-sample test in relation to training time and network complexity.
LINSCAN -- A Linearity Based Clustering Algorithm
Jun 25, 2024DBSCAN and OPTICS are powerful algorithms for identifying clusters of points in domains where few assumptions can be made about the structure of the data. In this paper, we leverage these strengths and introduce a new algorithm, LINSCAN, designed to seek lineated clusters that are difficult to find and isolate with existing methods. In particular, by embedding points as normal distributions approximating their local neighborhoods and leveraging a distance function derived from the Kullback Leibler Divergence, LINSCAN can detect and distinguish lineated clusters that are spatially close but have orthogonal covariances. We demonstrate how LINSCAN can be applied to seismic data to identify active faults, including intersecting faults, and determine their orientation. Finally, we discuss the properties a generalization of DBSCAN and OPTICS must have in order to retain the stability benefits of these algorithms.
All You Need is Resistance: On the Equivalence of Effective Resistance and Certain Optimal Transport Problems on Graphs
Apr 26, 2024



The fields of effective resistance and optimal transport on graphs are filled with rich connections to combinatorics, geometry, machine learning, and beyond. In this article we put forth a bold claim: that the two fields should be understood as one and the same, up to a choice of $p$. We make this claim precise by introducing the parameterized family of $p$-Beckmann distances for probability measures on graphs and relate them sharply to certain Wasserstein distances. Then, we break open a suite of results including explicit connections to optimal stopping times and random walks on graphs, graph Sobolev spaces, and a Benamou-Brenier type formula for $2$-Beckmann distance. We further explore empirical implications in the world of unsupervised learning for graph data and propose further study of the usage of these metrics where Wasserstein distance may produce computational bottlenecks.
OTClean: Data Cleaning for Conditional Independence Violations using Optimal Transport
Mar 04, 2024
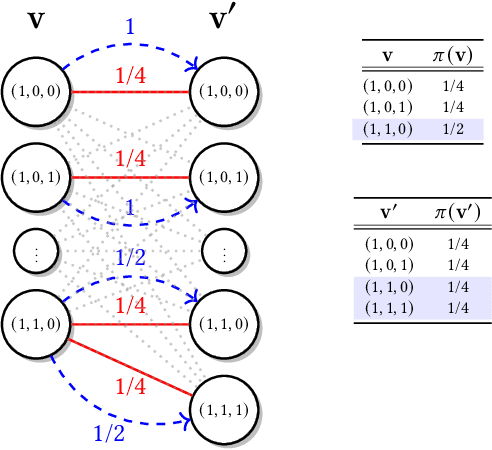
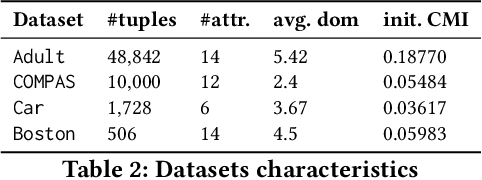
Ensuring Conditional Independence (CI) constraints is pivotal for the development of fair and trustworthy machine learning models. In this paper, we introduce \sys, a framework that harnesses optimal transport theory for data repair under CI constraints. Optimal transport theory provides a rigorous framework for measuring the discrepancy between probability distributions, thereby ensuring control over data utility. We formulate the data repair problem concerning CIs as a Quadratically Constrained Linear Program (QCLP) and propose an alternating method for its solution. However, this approach faces scalability issues due to the computational cost associated with computing optimal transport distances, such as the Wasserstein distance. To overcome these scalability challenges, we reframe our problem as a regularized optimization problem, enabling us to develop an iterative algorithm inspired by Sinkhorn's matrix scaling algorithm, which efficiently addresses high-dimensional and large-scale data. Through extensive experiments, we demonstrate the efficacy and efficiency of our proposed methods, showcasing their practical utility in real-world data cleaning and preprocessing tasks. Furthermore, we provide comparisons with traditional approaches, highlighting the superiority of our techniques in terms of preserving data utility while ensuring adherence to the desired CI constraints.