 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding In-Context Learning for Nonlinear Regression with Transformers: Attention as Featurizer
May 06, 2026Pre-trained transformers are able to learn from examples provided as part of the prompt without any weight updates, a remarkable ability known as in-context learning (ICL). Despite its demonstrated efficacy across various domains, the theoretical understanding of ICL is still developing. Whereas most existing theory has focused on linear models, we study ICL in the nonlinear regression setting. Through the interaction mechanism in attention, we explicitly construct transformer networks to realize nonlinear features, such as polynomial or spline bases, which span a wide class of functions. Based on this construction, we establish a framework to analyze end-to-end in-context nonlinear regression with the constructed features. Our theory provides finite-sample generalization error bounds in terms of context length and training set size. We numerically validate the theory on synthetic regression tasks.
In-Context Operator Learning on the Space of Probability Measures
Jan 15, 2026We introduce \emph{in-context operator learning on probability measure spaces} for optimal transport (OT). The goal is to learn a single solution operator that maps a pair of distributions to the OT map, using only few-shot samples from each distribution as a prompt and \emph{without} gradient updates at inference. We parameterize the solution operator and develop scaling-law theory in two regimes. In the \emph{nonparametric} setting, when tasks concentrate on a low-intrinsic-dimension manifold of source--target pairs, we establish generalization bounds that quantify how in-context accuracy scales with prompt size, intrinsic task dimension, and model capacity. In the \emph{parametric} setting (e.g., Gaussian families), we give an explicit architecture that recovers the exact OT map in context and provide finite-sample excess-risk bounds. Our numerical experiments on synthetic transports and generative-modeling benchmarks validate the framework.
Data-Driven Model Reduction using WeldNet: Windowed Encoders for Learning Dynamics
Dec 11, 2025Many problems in science and engineering involve time-dependent, high dimensional datasets arising from complex physical processes, which are costly to simulate. In this work, we propose WeldNet: Windowed Encoders for Learning Dynamics, a data-driven nonlinear model reduction framework to build a low-dimensional surrogate model for complex evolution systems. Given time-dependent training data, we split the time domain into multiple overlapping windows, within which nonlinear dimension reduction is performed by auto-encoders to capture latent codes. Once a low-dimensional representation of the data is learned, a propagator network is trained to capture the evolution of the latent codes in each window, and a transcoder is trained to connect the latent codes between adjacent windows. The proposed windowed decomposition significantly simplifies propagator training by breaking long-horizon dynamics into multiple short, manageable segments, while the transcoders ensure consistency across windows. In addition to the algorithmic framework, we develop a mathematical theory establishing the representation power of WeldNet under the manifold hypothesis, justifying the success of nonlinear model reduction via deep autoencoder-based architectures. Our numerical experiments on various differential equations indicate that WeldNet can capture nonlinear latent structures and their underlying dynamics, outperforming both traditional projection-based approaches and recently developed nonlinear model reduction methods.
Understanding In-Context Learning on Structured Manifolds: Bridging Attention to Kernel Methods
Jun 12, 2025While in-context learning (ICL) has achieved remarkable success in natural language and vision domains, its theoretical understanding--particularly in the context of structured geometric data--remains unexplored. In this work, we initiate a theoretical study of ICL for regression of H\"older functions on manifolds. By establishing a novel connection between the attention mechanism and classical kernel methods, we derive generalization error bounds in terms of the prompt length and the number of training tasks. When a sufficient number of training tasks are observed, transformers give rise to the minimax regression rate of H\"older functions on manifolds, which scales exponentially with the intrinsic dimension of the manifold, rather than the ambient space dimension. Our result also characterizes how the generalization error scales with the number of training tasks, shedding light on the complexity of transformers as in-context algorithm learners. Our findings provide foundational insights into the role of geometry in ICL and novels tools to study ICL of nonlinear models.
Transformers for Learning on Noisy and Task-Level Manifolds: Approximation and Generalization Insights
May 06, 2025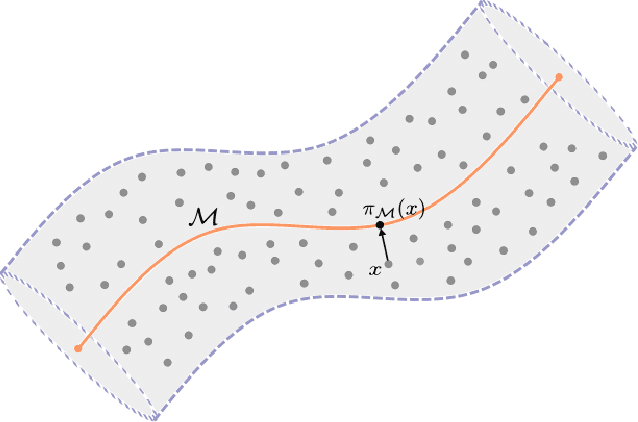
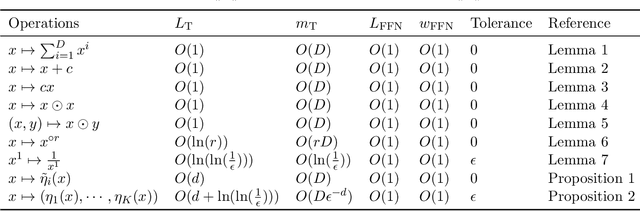


Transformers serve as the foundational architecture for large language and video generation models, such as GPT, BERT, SORA and their successors. Empirical studies have demonstrated that real-world data and learning tasks exhibit low-dimensional structures, along with some noise or measurement error. The performance of transformers tends to depend on the intrinsic dimension of the data/tasks, though theoretical understandings remain largely unexplored for transformers. This work establishes a theoretical foundation by analyzing the performance of transformers for regression tasks involving noisy input data on a manifold. Specifically, the input data are in a tubular neighborhood of a manifold, while the ground truth function depends on the projection of the noisy data onto the manifold. We prove approximation and generalization errors which crucially depend on the intrinsic dimension of the manifold. Our results demonstrate that transformers can leverage low-complexity structures in learning task even when the input data are perturbed by high-dimensional noise. Our novel proof technique constructs representations of basic arithmetic operations by transformers, which may hold independent interest.
TART: Boosting Clean Accuracy Through Tangent Direction Guided Adversarial Training
Aug 27, 2024



Adversarial training has been shown to be successful in enhancing the robustness of deep neural networks against adversarial attacks. However, this robustness is accompanied by a significant decline in accuracy on clean data. In this paper, we propose a novel method, called Tangent Direction Guided Adversarial Training (TART), that leverages the tangent space of the data manifold to ameliorate the existing adversarial defense algorithms. We argue that training with adversarial examples having large normal components significantly alters the decision boundary and hurts accuracy. TART mitigates this issue by estimating the tangent direction of adversarial examples and allocating an adaptive perturbation limit according to the norm of their tangential component. To the best of our knowledge, our paper is the first work to consider the concept of tangent space and direction in the context of adversarial defense. We validate the effectiveness of TART through extensive experiments on both simulated and benchmark datasets. The results demonstrate that TART consistently boosts clean accuracy while retaining a high level of robustness against adversarial attacks. Our findings suggest that incorporating the geometric properties of data can lead to more effective and efficient adversarial training methods.
Unsupervised Solution Operator Learning for Mean-Field Games via Sampling-Invariant Parametrizations
Jan 27, 2024
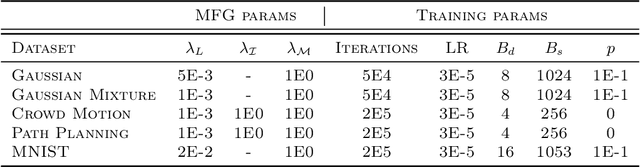
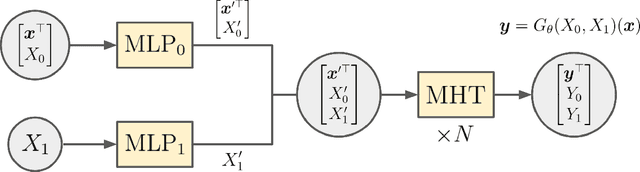
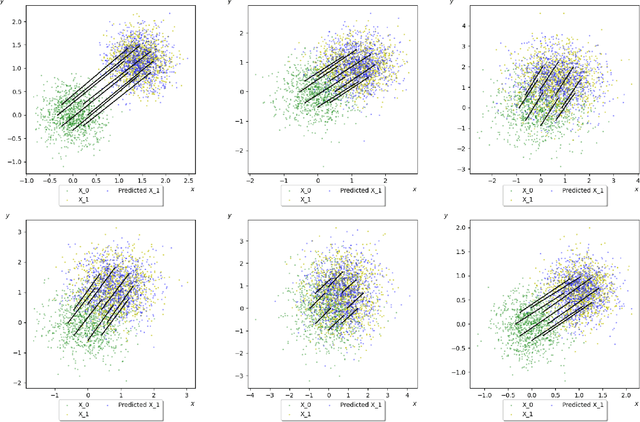
Recent advances in deep learning has witnessed many innovative frameworks that solve high dimensional mean-field games (MFG) accurately and efficiently. These methods, however, are restricted to solving single-instance MFG and demands extensive computational time per instance, limiting practicality. To overcome this, we develop a novel framework to learn the MFG solution operator. Our model takes a MFG instances as input and output their solutions with one forward pass. To ensure the proposed parametrization is well-suited for operator learning, we introduce and prove the notion of sampling invariance for our model, establishing its convergence to a continuous operator in the sampling limit. Our method features two key advantages. First, it is discretization-free, making it particularly suitable for learning operators of high-dimensional MFGs. Secondly, it can be trained without the need for access to supervised labels, significantly reducing the computational overhead associated with creating training datasets in existing operator learning methods. We test our framework on synthetic and realistic datasets with varying complexity and dimensionality to substantiate its robustness.
Emulating Complex Synapses Using Interlinked Proton Conductors
Jan 26, 2024



In terms of energy efficiency and computational speed, neuromorphic electronics based on non-volatile memory devices is expected to be one of most promising hardware candidates for future artificial intelligence (AI). However, catastrophic forgetting, networks rapidly overwriting previously learned weights when learning new tasks, remains as a pivotal hurdle in either digital or analog AI chips for unleashing the true power of brain-like computing. To address catastrophic forgetting in the context of online memory storage, a complex synapse model (the Benna-Fusi model) has been proposed recently[1], whose synaptic weight and internal variables evolve following a diffusion dynamics. In this work, by designing a proton transistor with a series of charge-diffusion-controlled storage components, we have experimentally realized the Benna-Fusi artificial complex synapse. The memory consolidation from coupled storage components is revealed by both numerical simulations and experimental observations. Different memory timescales for the complex synapse are engineered by the diffusion length of charge carriers, the capacity and number of coupled storage components. The advantage of the demonstrated complex synapse in both memory capacity and memory consolidation is revealed by neural network simulations of face familiarity detection. Our experimental realization of the complex synapse suggests a promising approach to enhance memory capacity and to enable continual learning.
Generalization Error Guaranteed Auto-Encoder-Based Nonlinear Model Reduction for Operator Learning
Jan 19, 2024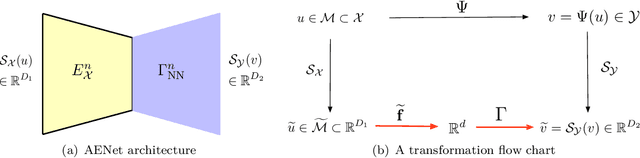
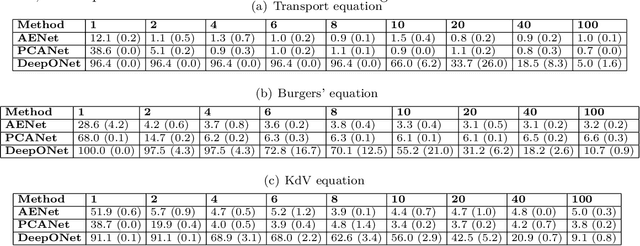
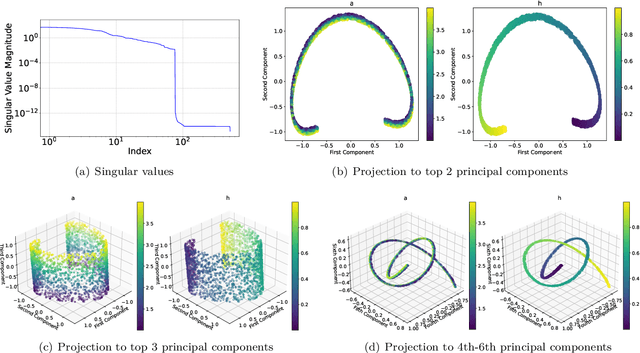
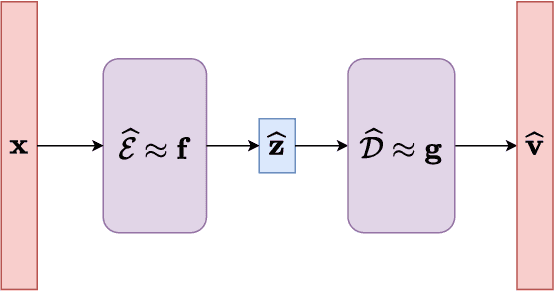
Many physical processes in science and engineering are naturally represented by operators between infinite-dimensional function spaces. The problem of operator learning, in this context, seeks to extract these physical processes from empirical data, which is challenging due to the infinite or high dimensionality of data. An integral component in addressing this challenge is model reduction, which reduces both the data dimensionality and problem size. In this paper, we utilize low-dimensional nonlinear structures in model reduction by investigating Auto-Encoder-based Neural Network (AENet). AENet first learns the latent variables of the input data and then learns the transformation from these latent variables to corresponding output data. Our numerical experiments validate the ability of AENet to accurately learn the solution operator of nonlinear partial differential equations. Furthermore, we establish a mathematical and statistical estimation theory that analyzes the generalization error of AENet. Our theoretical framework shows that the sample complexity of training AENet is intricately tied to the intrinsic dimension of the modeled process, while also demonstrating the remarkable resilience of AENet to noise.
Deep Nonparametric Estimation of Intrinsic Data Structures by Chart Autoencoders: Generalization Error and Robustness
Mar 20, 2023

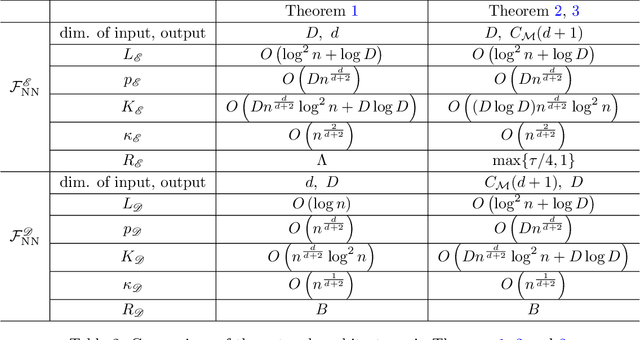
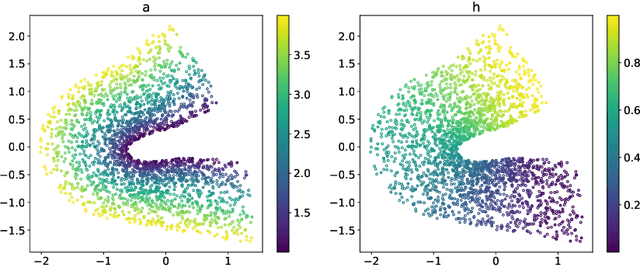
Autoencoders have demonstrated remarkable success in learning low-dimensional latent features of high-dimensional data across various applications. Assuming that data are sampled near a low-dimensional manifold, we employ chart autoencoders, which encode data into low-dimensional latent features on a collection of charts, preserving the topology and geometry of the data manifold. Our paper establishes statistical guarantees on the generalization error of chart autoencoders, and we demonstrate their denoising capabilities by considering $n$ noisy training samples, along with their noise-free counterparts, on a $d$-dimensional manifold. By training autoencoders, we show that chart autoencoders can effectively denoise the input data with normal noise. We prove that, under proper network architectures, chart autoencoders achieve a squared generalization error in the order of $\displaystyle n^{-\frac{2}{d+2}}\log^4 n$, which depends on the intrinsic dimension of the manifold and only weakly depends on the ambient dimension and noise level. We further extend our theory on data with noise containing both normal and tangential components, where chart autoencoders still exhibit a denoising effect for the normal component. As a special case, our theory also applies to classical autoencoders, as long as the data manifold has a global parametrization. Our results provide a solid theoretical foundation for the effectiveness of autoencoders, which is further validated through several numerical experiments.