 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmulating Complex Synapses Using Interlinked Proton Conductors
Jan 26, 2024



In terms of energy efficiency and computational speed, neuromorphic electronics based on non-volatile memory devices is expected to be one of most promising hardware candidates for future artificial intelligence (AI). However, catastrophic forgetting, networks rapidly overwriting previously learned weights when learning new tasks, remains as a pivotal hurdle in either digital or analog AI chips for unleashing the true power of brain-like computing. To address catastrophic forgetting in the context of online memory storage, a complex synapse model (the Benna-Fusi model) has been proposed recently[1], whose synaptic weight and internal variables evolve following a diffusion dynamics. In this work, by designing a proton transistor with a series of charge-diffusion-controlled storage components, we have experimentally realized the Benna-Fusi artificial complex synapse. The memory consolidation from coupled storage components is revealed by both numerical simulations and experimental observations. Different memory timescales for the complex synapse are engineered by the diffusion length of charge carriers, the capacity and number of coupled storage components. The advantage of the demonstrated complex synapse in both memory capacity and memory consolidation is revealed by neural network simulations of face familiarity detection. Our experimental realization of the complex synapse suggests a promising approach to enhance memory capacity and to enable continual learning.
AxonEM Dataset: 3D Axon Instance Segmentation of Brain Cortical Regions
Jul 12, 2021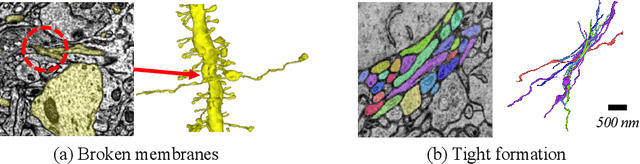

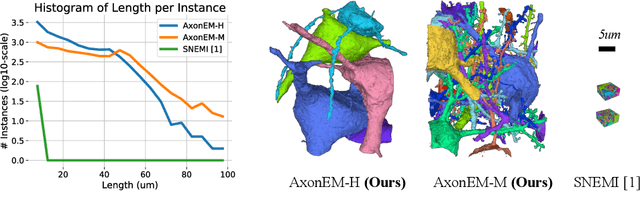

Electron microscopy (EM) enables the reconstruction of neural circuits at the level of individual synapses, which has been transformative for scientific discoveries. However, due to the complex morphology, an accurate reconstruction of cortical axons has become a major challenge. Worse still, there is no publicly available large-scale EM dataset from the cortex that provides dense ground truth segmentation for axons, making it difficult to develop and evaluate large-scale axon reconstruction methods. To address this, we introduce the AxonEM dataset, which consists of two 30x30x30 um^3 EM image volumes from the human and mouse cortex, respectively. We thoroughly proofread over 18,000 axon instances to provide dense 3D axon instance segmentation, enabling large-scale evaluation of axon reconstruction methods. In addition, we densely annotate nine ground truth subvolumes for training, per each data volume. With this, we reproduce two published state-of-the-art methods and provide their evaluation results as a baseline. We publicly release our code and data at https://connectomics-bazaar.github.io/proj/AxonEM/index.html to foster the development of advanced methods.
Pipelined Training with Stale Weights of Deep Convolutional Neural Networks
Dec 29, 2019
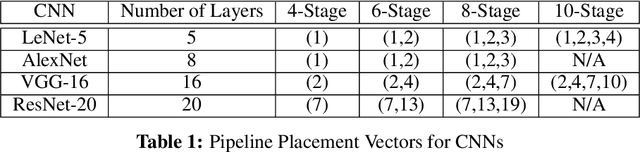
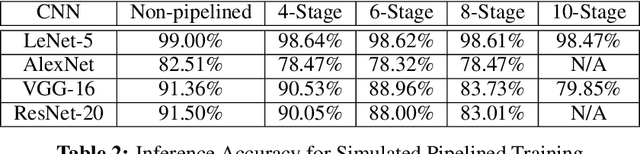
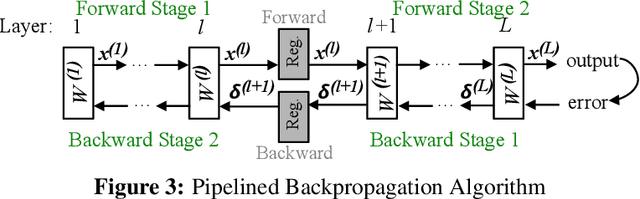
The growth in the complexity of Convolutional Neural Networks (CNNs) is increasing interest in partitioning a network across multiple accelerators during training and pipelining the backpropagation computations over the accelerators. Existing approaches avoid or limit the use of stale weights through techniques such as micro-batching or weight stashing. These techniques either underutilize of accelerators or increase memory footprint. We explore the impact of stale weights on the statistical efficiency and performance in a pipelined backpropagation scheme that maximizes accelerator utilization and keeps memory overhead modest. We use 4 CNNs (LeNet-5, AlexNet, VGG and ResNet) and show that when pipelining is limited to early layers in a network, training with stale weights converges and results in models with comparable inference accuracies to those resulting from non-pipelined training on MNIST and CIFAR-10 datasets; a drop in accuracy of 0.4%, 4%, 0.83% and 1.45% for the 4 networks, respectively. However, when pipelining is deeper in the network, inference accuracies drop significantly. We propose combining pipelined and non-pipelined training in a hybrid scheme to address this drop. We demonstrate the implementation and performance of our pipelined backpropagation in PyTorch on 2 GPUs using ResNet, achieving speedups of up to 1.8X over a 1-GPU baseline, with a small drop in inference accuracy.