 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compilation Flow for the Generation of CNN Inference Accelerators on FPGAs
Mar 08, 2022



We present a compilation flow for the generation of CNN inference accelerators on FPGAs. The flow translates a frozen model into OpenCL kernels with the TVM compiler and uses the Intel OpenCL SDK to compile to an FPGA bitstream. We improve the quality of the generated hardware with optimizations applied to the base OpenCL kernels generated by TVM. These optimizations increase parallelism, reduce memory access latency, increase concurrency and save on-chip resources. We automate these optimizations in TVM and evaluate them by generating accelerators for LeNet-5, MobileNetV1 and ResNet-34 on an Intel Stratix~10SX. We show that the optimizations improve the performance of the generated accelerators by up to 846X over the base accelerators. The performance of the optimized accelerators is up to 4.57X better than TensorFlow on CPU, 3.83X better than single-threaded TVM and is only 0.34X compared to TVM with 56 threads. Our optimized kernels also outperform ones generated by a similar approach (that also uses high-level synthesis) while providing more functionality and flexibility. However, it underperforms an approach that utilizes hand-optimized designs. Thus, we view our approach as useful in pre-production environments that benefit from increased performance and fast prototyping, realizing the benefits of FPGAs without hardware design expertise.
Pipelined Training with Stale Weights of Deep Convolutional Neural Networks
Dec 29, 2019
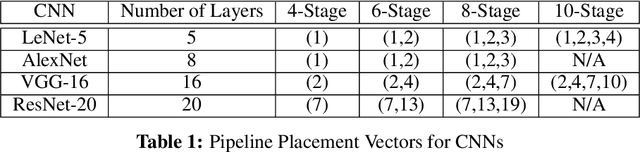
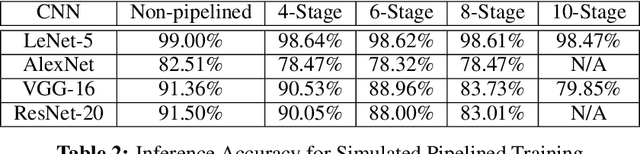
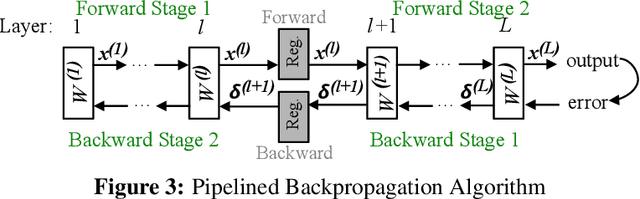
The growth in the complexity of Convolutional Neural Networks (CNNs) is increasing interest in partitioning a network across multiple accelerators during training and pipelining the backpropagation computations over the accelerators. Existing approaches avoid or limit the use of stale weights through techniques such as micro-batching or weight stashing. These techniques either underutilize of accelerators or increase memory footprint. We explore the impact of stale weights on the statistical efficiency and performance in a pipelined backpropagation scheme that maximizes accelerator utilization and keeps memory overhead modest. We use 4 CNNs (LeNet-5, AlexNet, VGG and ResNet) and show that when pipelining is limited to early layers in a network, training with stale weights converges and results in models with comparable inference accuracies to those resulting from non-pipelined training on MNIST and CIFAR-10 datasets; a drop in accuracy of 0.4%, 4%, 0.83% and 1.45% for the 4 networks, respectively. However, when pipelining is deeper in the network, inference accuracies drop significantly. We propose combining pipelined and non-pipelined training in a hybrid scheme to address this drop. We demonstrate the implementation and performance of our pipelined backpropagation in PyTorch on 2 GPUs using ResNet, achieving speedups of up to 1.8X over a 1-GPU baseline, with a small drop in inference accuracy.
Fast On-the-fly Retraining-free Sparsification of Convolutional Neural Networks
Nov 13, 2018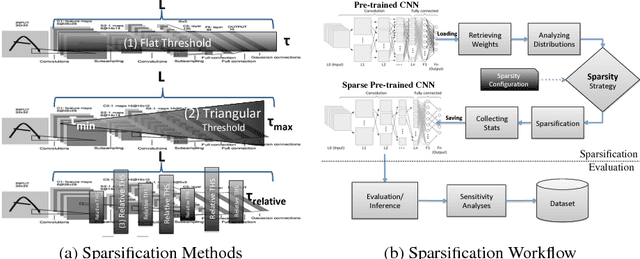

Modern Convolutional Neural Networks (CNNs) are complex, encompassing millions of parameters. Their deployment exerts computational, storage and energy demands, particularly on embedded platforms. Existing approaches to prune or sparsify CNNs require retraining to maintain inference accuracy. Such retraining is not feasible in some contexts. In this paper, we explore the sparsification of CNNs by proposing three model-independent methods. Our methods are applied on-the-fly and require no retraining. We show that the state-of-the-art models' weights can be reduced by up to 73% (compression factor of 3.7x) without incurring more than 5% loss in Top-5 accuracy. Additional fine-tuning gains only 8% in sparsity, which indicates that our fast on-the-fly methods are effective.