 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtean Compiler: An Agile Framework to Drive Fine-grain Phase Ordering
Feb 05, 2026The phase ordering problem has been a long-standing challenge since the late 1970s, yet it remains an open problem due to having a vast optimization space and an unbounded nature, making it an open-ended problem without a finite solution, one can limit the scope by reducing the number and the length of optimizations. Traditionally, such locally optimized decisions are made by hand-coded algorithms tuned for a small number of benchmarks, often requiring significant effort to be retuned when the benchmark suite changes. In the past 20 years, Machine Learning has been employed to construct performance models to improve the selection and ordering of compiler optimizations, however, the approaches are not baked into the compiler seamlessly and never materialized to be leveraged at a fine-grained scope of code segments. This paper presents Protean Compiler: An agile framework to enable LLVM with built-in phase-ordering capabilities at a fine-grained scope. The framework also comprises a complete library of more than 140 handcrafted static feature collection methods at varying scopes, and the experimental results showcase speedup gains of up to 4.1% on average and up to 15.7% on select Cbench applications wrt LLVM's O3 by just incurring a few extra seconds of build time on Cbench. Additionally, Protean compiler allows for an easy integration with third-party ML frameworks and other Large Language Models, and this two-step optimization shows a gain of 10.1% and 8.5% speedup wrt O3 on Cbench's Susan and Jpeg applications. Protean compiler is seamlessly integrated into LLVM and can be used as a new, enhanced, full-fledged compiler. We plan to release the project to the open-source community in the near future.
ACPO: AI-Enabled Compiler-Driven Program Optimization
Dec 15, 2023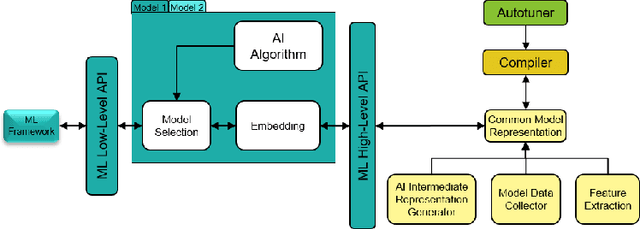
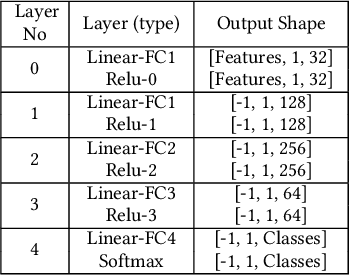
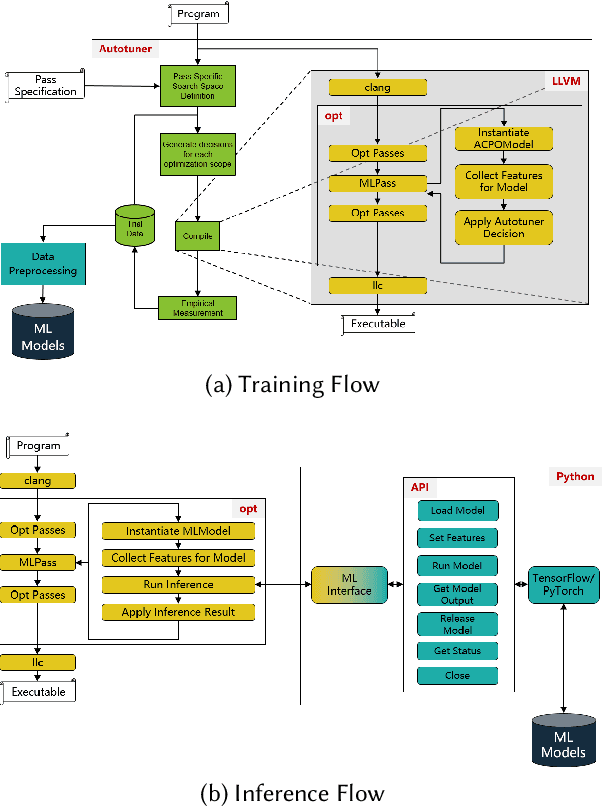
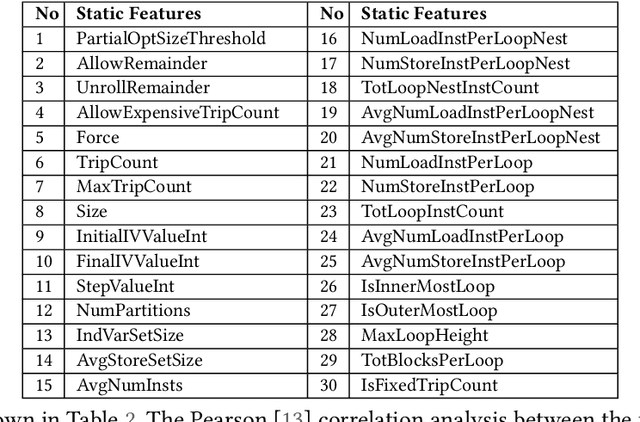
The key to performance optimization of a program is to decide correctly when a certain transformation should be applied by a compiler. Traditionally, such profitability decisions are made by hand-coded algorithms tuned for a very small number of benchmarks, usually requiring a great deal of effort to be retuned when the benchmark suite changes. This is an ideal opportunity to apply machine-learning models to speed up the tuning process; while this realization has been around since the late 90s, only recent advancements in ML enabled a practical application of ML to compilers as an end-to-end framework. Even so, seamless integration of ML into the compiler would require constant rebuilding of the compiler when models are updated. This paper presents ACPO: \textbf{\underline{A}}I-Enabled \textbf{\underline{C}}ompiler-driven \textbf{\underline{P}}rogram \textbf{\underline{O}}ptimization; a novel framework to provide LLVM with simple and comprehensive tools to benefit from employing ML models for different optimization passes. We first showcase the high-level view, class hierarchy, and functionalities of ACPO and subsequently, demonstrate \taco{a couple of use cases of ACPO by ML-enabling the Loop Unroll and Function Inlining passes and describe how ACPO can be leveraged to optimize other passes. Experimental results reveal that ACPO model for Loop Unroll is able to gain on average 4\% and 3\%, 5.4\%, 0.2\% compared to LLVM's O3 optimization when deployed on Polybench, Coral-2, CoreMark, and Graph-500, respectively. Furthermore, by adding the Inliner model as well, ACPO is able to provide up to 4.5\% and 2.4\% on Polybench and Cbench compared with LLVM's O3 optimization, respectively.
MLGOPerf: An ML Guided Inliner to Optimize Performance
Jul 19, 2022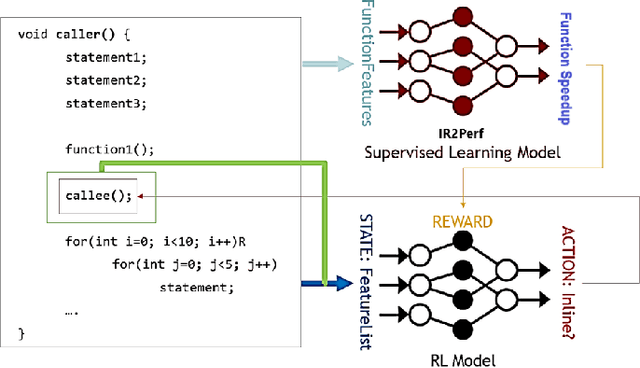
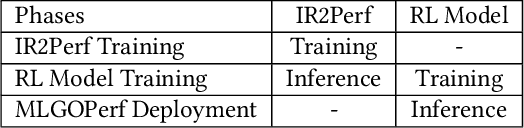
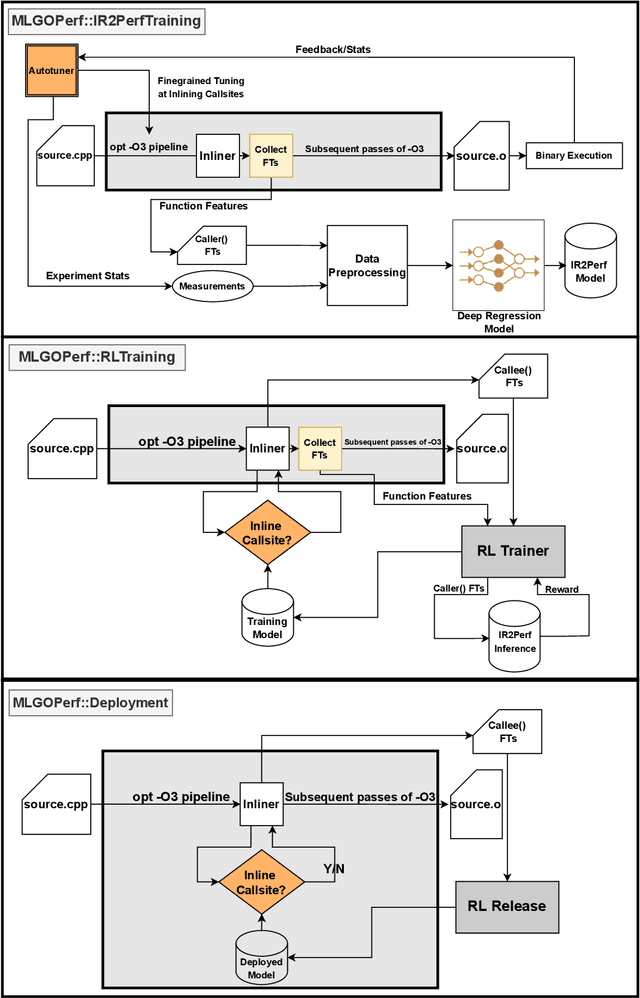
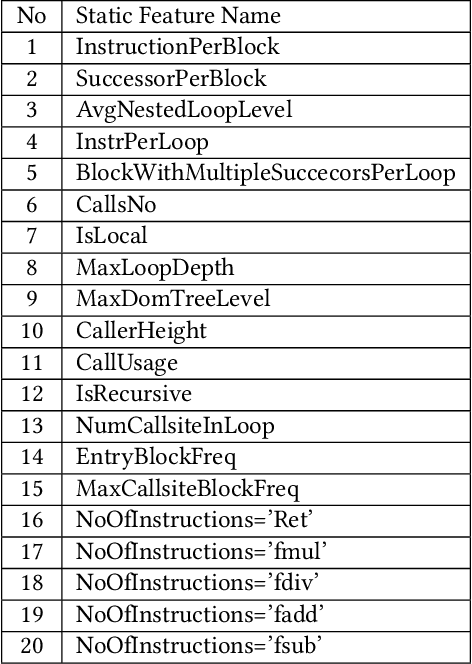
For the past 25 years, we have witnessed an extensive application of Machine Learning to the Compiler space; the selection and the phase-ordering problem. However, limited works have been upstreamed into the state-of-the-art compilers, i.e., LLVM, to seamlessly integrate the former into the optimization pipeline of a compiler to be readily deployed by the user. MLGO was among the first of such projects and it only strives to reduce the code size of a binary with an ML-based Inliner using Reinforcement Learning. This paper presents MLGOPerf; the first end-to-end framework capable of optimizing performance using LLVM's ML-Inliner. It employs a secondary ML model to generate rewards used for training a retargeted Reinforcement learning agent, previously used as the primary model by MLGO. It does so by predicting the post-inlining speedup of a function under analysis and it enables a fast training framework for the primary model which otherwise wouldn't be practical. The experimental results show MLGOPerf is able to gain up to 1.8% and 2.2% with respect to LLVM's optimization at O3 when trained for performance on SPEC CPU2006 and Cbench benchmarks, respectively. Furthermore, the proposed approach provides up to 26% increased opportunities to autotune code regions for our benchmarks which can be translated into an additional 3.7% speedup value.
Fast On-the-fly Retraining-free Sparsification of Convolutional Neural Networks
Nov 13, 2018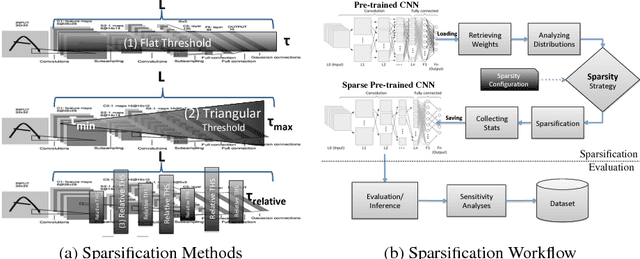

Modern Convolutional Neural Networks (CNNs) are complex, encompassing millions of parameters. Their deployment exerts computational, storage and energy demands, particularly on embedded platforms. Existing approaches to prune or sparsify CNNs require retraining to maintain inference accuracy. Such retraining is not feasible in some contexts. In this paper, we explore the sparsification of CNNs by proposing three model-independent methods. Our methods are applied on-the-fly and require no retraining. We show that the state-of-the-art models' weights can be reduced by up to 73% (compression factor of 3.7x) without incurring more than 5% loss in Top-5 accuracy. Additional fine-tuning gains only 8% in sparsity, which indicates that our fast on-the-fly methods are effective.
A Survey on Compiler Autotuning using Machine Learning
Sep 03, 2018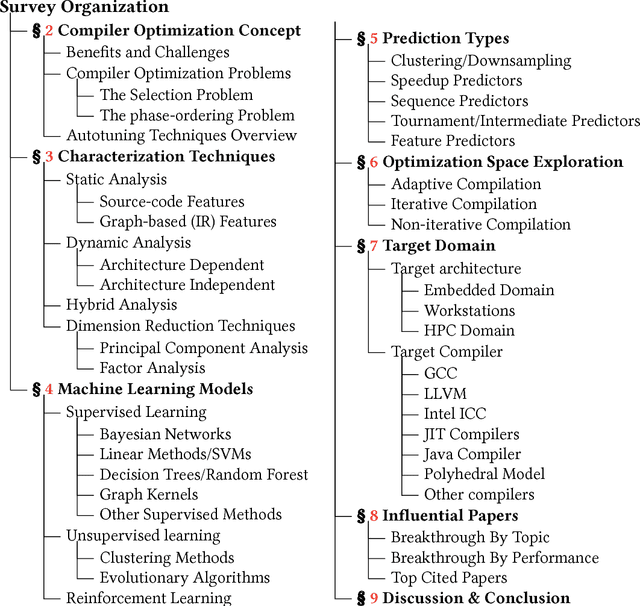

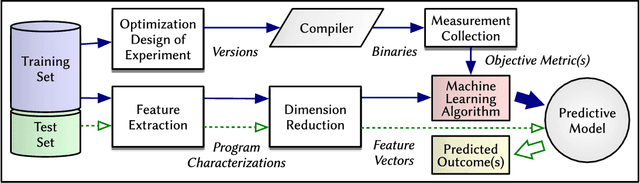
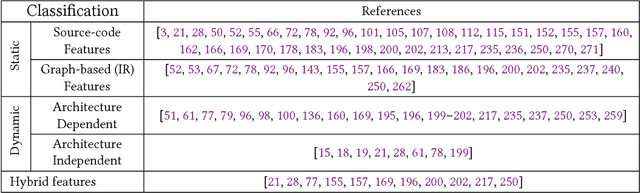
Since the mid-1990s, researchers have been trying to use machine-learning based approaches to solve a number of different compiler optimization problems. These techniques primarily enhance the quality of the obtained results and, more importantly, make it feasible to tackle two main compiler optimization problems: optimization selection (choosing which optimizations to apply) and phase-ordering (choosing the order of applying optimizations). The compiler optimization space continues to grow due to the advancement of applications, increasing number of compiler optimizations, and new target architectures. Generic optimization passes in compilers cannot fully leverage newly introduced optimizations and, therefore, cannot keep up with the pace of increasing options. This survey summarizes and classifies the recent advances in using machine learning for the compiler optimization field, particularly on the two major problems of (1) selecting the best optimizations and (2) the phase-ordering of optimizations. The survey highlights the approaches taken so far, the obtained results, the fine-grain classification among different approaches and finally, the influential papers of the field.