 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACPO: AI-Enabled Compiler-Driven Program Optimization
Dec 15, 2023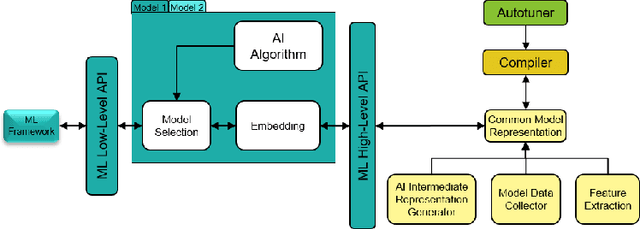
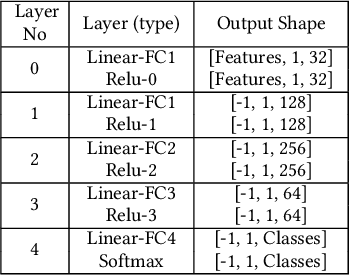
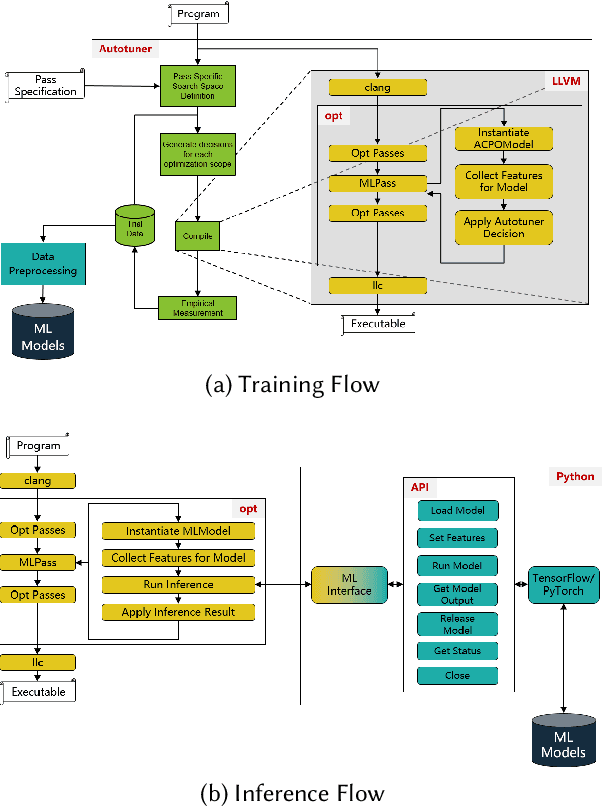
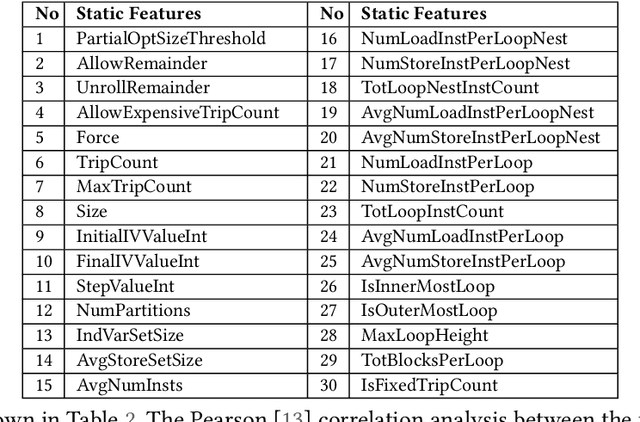
The key to performance optimization of a program is to decide correctly when a certain transformation should be applied by a compiler. Traditionally, such profitability decisions are made by hand-coded algorithms tuned for a very small number of benchmarks, usually requiring a great deal of effort to be retuned when the benchmark suite changes. This is an ideal opportunity to apply machine-learning models to speed up the tuning process; while this realization has been around since the late 90s, only recent advancements in ML enabled a practical application of ML to compilers as an end-to-end framework. Even so, seamless integration of ML into the compiler would require constant rebuilding of the compiler when models are updated. This paper presents ACPO: \textbf{\underline{A}}I-Enabled \textbf{\underline{C}}ompiler-driven \textbf{\underline{P}}rogram \textbf{\underline{O}}ptimization; a novel framework to provide LLVM with simple and comprehensive tools to benefit from employing ML models for different optimization passes. We first showcase the high-level view, class hierarchy, and functionalities of ACPO and subsequently, demonstrate \taco{a couple of use cases of ACPO by ML-enabling the Loop Unroll and Function Inlining passes and describe how ACPO can be leveraged to optimize other passes. Experimental results reveal that ACPO model for Loop Unroll is able to gain on average 4\% and 3\%, 5.4\%, 0.2\% compared to LLVM's O3 optimization when deployed on Polybench, Coral-2, CoreMark, and Graph-500, respectively. Furthermore, by adding the Inliner model as well, ACPO is able to provide up to 4.5\% and 2.4\% on Polybench and Cbench compared with LLVM's O3 optimization, respectively.
MLGOPerf: An ML Guided Inliner to Optimize Performance
Jul 19, 2022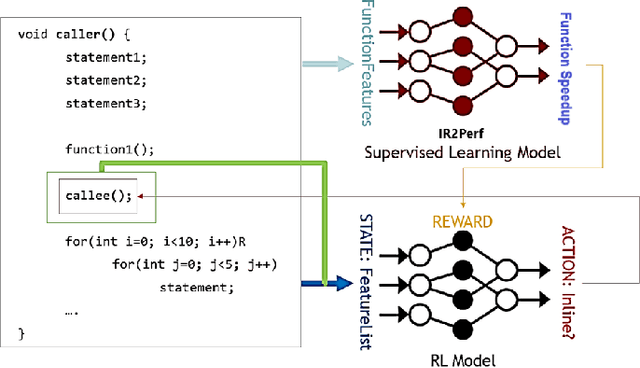
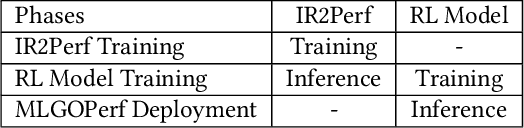
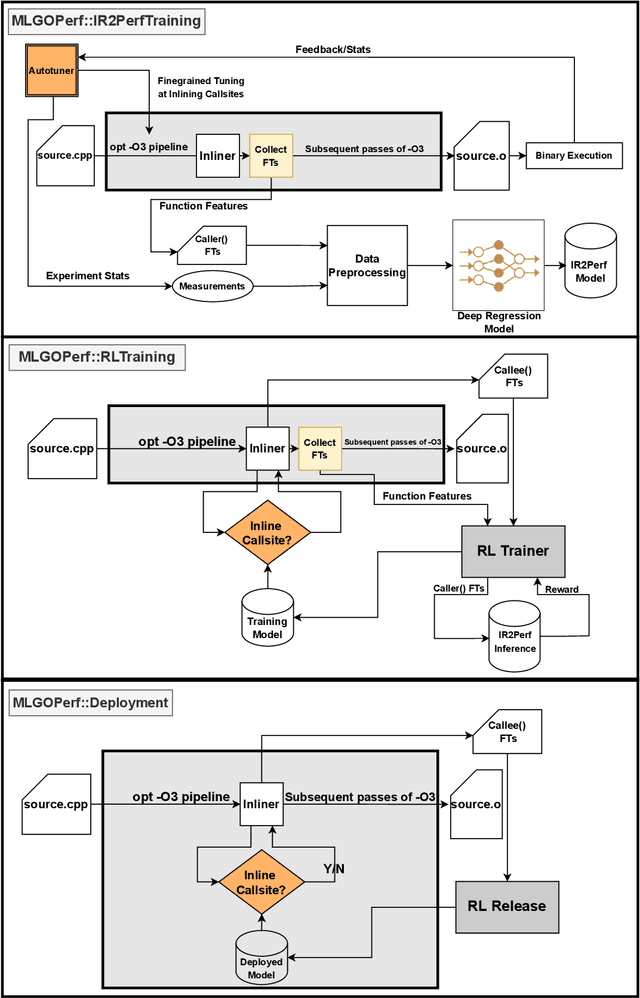
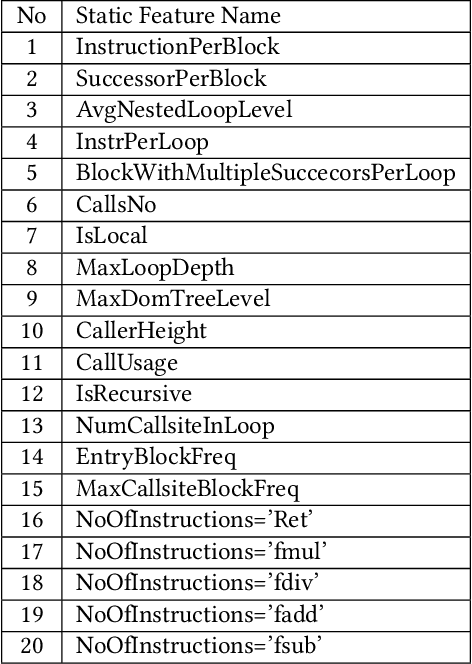
For the past 25 years, we have witnessed an extensive application of Machine Learning to the Compiler space; the selection and the phase-ordering problem. However, limited works have been upstreamed into the state-of-the-art compilers, i.e., LLVM, to seamlessly integrate the former into the optimization pipeline of a compiler to be readily deployed by the user. MLGO was among the first of such projects and it only strives to reduce the code size of a binary with an ML-based Inliner using Reinforcement Learning. This paper presents MLGOPerf; the first end-to-end framework capable of optimizing performance using LLVM's ML-Inliner. It employs a secondary ML model to generate rewards used for training a retargeted Reinforcement learning agent, previously used as the primary model by MLGO. It does so by predicting the post-inlining speedup of a function under analysis and it enables a fast training framework for the primary model which otherwise wouldn't be practical. The experimental results show MLGOPerf is able to gain up to 1.8% and 2.2% with respect to LLVM's optimization at O3 when trained for performance on SPEC CPU2006 and Cbench benchmarks, respectively. Furthermore, the proposed approach provides up to 26% increased opportunities to autotune code regions for our benchmarks which can be translated into an additional 3.7% speedup value.