 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLGOPerf: An ML Guided Inliner to Optimize Performance
Jul 19, 2022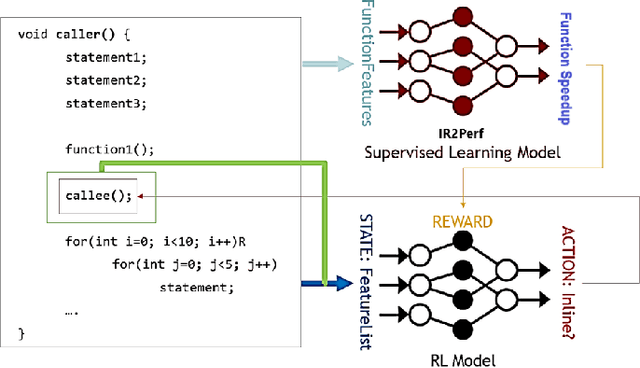
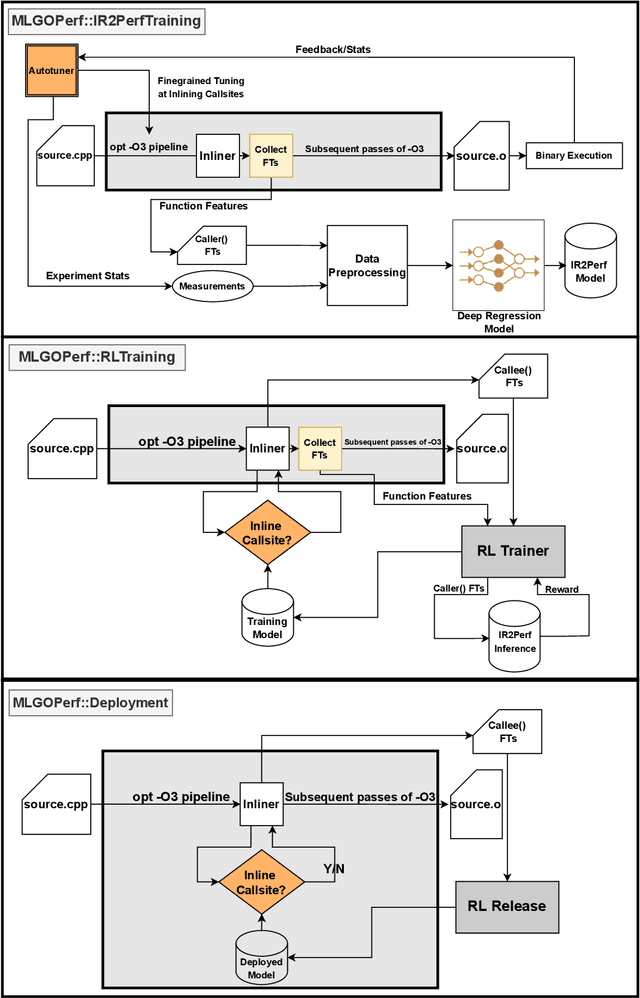
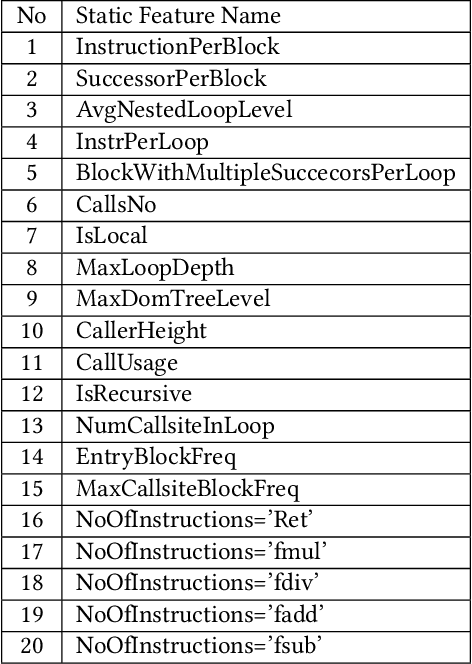
For the past 25 years, we have witnessed an extensive application of Machine Learning to the Compiler space; the selection and the phase-ordering problem. However, limited works have been upstreamed into the state-of-the-art compilers, i.e., LLVM, to seamlessly integrate the former into the optimization pipeline of a compiler to be readily deployed by the user. MLGO was among the first of such projects and it only strives to reduce the code size of a binary with an ML-based Inliner using Reinforcement Learning. This paper presents MLGOPerf; the first end-to-end framework capable of optimizing performance using LLVM's ML-Inliner. It employs a secondary ML model to generate rewards used for training a retargeted Reinforcement learning agent, previously used as the primary model by MLGO. It does so by predicting the post-inlining speedup of a function under analysis and it enables a fast training framework for the primary model which otherwise wouldn't be practical. The experimental results show MLGOPerf is able to gain up to 1.8% and 2.2% with respect to LLVM's optimization at O3 when trained for performance on SPEC CPU2006 and Cbench benchmarks, respectively. Furthermore, the proposed approach provides up to 26% increased opportunities to autotune code regions for our benchmarks which can be translated into an additional 3.7% speedup value.