 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Beyond English: Language Diversity for Better Quantized Multilingual LLM
Jan 26, 2026Quantization is an effective technique for reducing the storage footprint and computational costs of Large Language Models (LLMs), but it often results in performance degradation. Existing post-training quantization methods typically use small, English-only calibration sets; however, their impact on multilingual models remains underexplored. We systematically evaluate eight calibration settings (five single-language and three multilingual mixes) on two quantizers (GPTQ, AWQ) on data from 10 languages. Our findings reveal a consistent trend: non-English and multilingual calibration sets significantly improve perplexity compared to English-only baselines. Specifically, we observe notable average perplexity gains across both quantizers on Llama3.1 8B and Qwen2.5 7B, with multilingual mixes achieving the largest overall reductions of up to 3.52 points in perplexity. Furthermore, our analysis indicates that tailoring calibration sets to the evaluation language yields the largest improvements for individual languages, underscoring the importance of linguistic alignment. We also identify specific failure cases where certain language-quantizer combinations degrade performance, which we trace to differences in activation range distributions across languages. These results highlight that static one-size-fits-all calibration is suboptimal and that tailoring calibration data, both in language and diversity, plays a crucial role in robustly quantizing multilingual LLMs.
Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls
Oct 02, 2025Training data plays a crucial role in Large Language Models (LLM) scaling, yet high quality data is of limited supply. Synthetic data techniques offer a potential path toward sidestepping these limitations. We conduct a large-scale empirical investigation (>1000 LLMs with >100k GPU hours) using a unified protocol and scaling laws, comparing natural web data, diverse synthetic types (rephrased text, generated textbooks), and mixtures of natural and synthetic data. Specifically, we found pre-training on rephrased synthetic data \textit{alone} is not faster than pre-training on natural web texts; while pre-training on 1/3 rephrased synthetic data mixed with 2/3 natural web texts can speed up 5-10x (to reach the same validation loss) at larger data budgets. Pre-training on textbook-style synthetic data \textit{alone} results in notably higher loss on many downstream domains especially at small data budgets. "Good" ratios of synthetic data in training data mixtures depend on the model size and data budget, empirically converging to ~30% for rephrased synthetic data. Larger generator models do not necessarily yield better pre-training data than ~8B-param models. These results contribute mixed evidence on "model collapse" during large-scale single-round (n=1) model training on synthetic data--training on rephrased synthetic data shows no degradation in performance in foreseeable scales whereas training on mixtures of textbook-style pure-generated synthetic data shows patterns predicted by "model collapse". Our work demystifies synthetic data in pre-training, validates its conditional benefits, and offers practical guidance.
Carbon Aware Transformers Through Joint Model-Hardware Optimization
May 02, 2025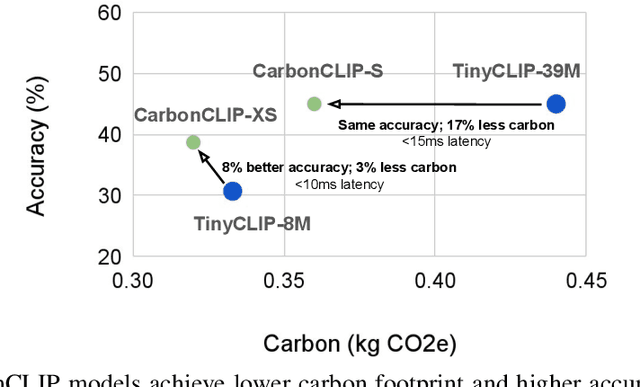
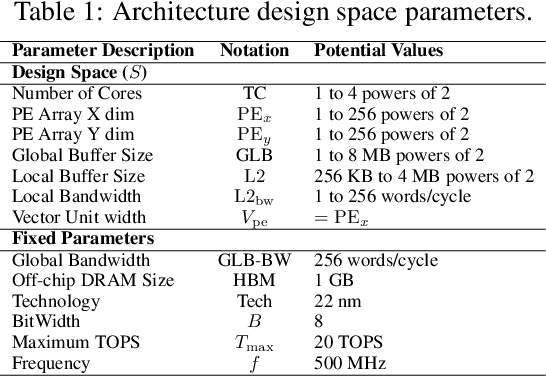
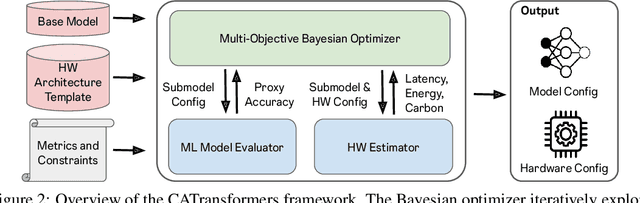
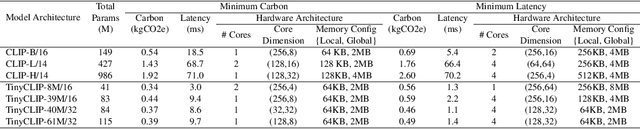
The rapid growth of machine learning (ML) systems necessitates a more comprehensive evaluation of their environmental impact, particularly their carbon footprint, which comprises operational carbon from training and inference execution and embodied carbon from hardware manufacturing and its entire life-cycle. Despite the increasing importance of embodied emissions, there is a lack of tools and frameworks to holistically quantify and optimize the total carbon footprint of ML systems. To address this, we propose CATransformers, a carbon-aware architecture search framework that enables sustainability-driven co-optimization of ML models and hardware architectures. By incorporating both operational and embodied carbon metrics into early design space exploration of domain-specific hardware accelerators, CATransformers demonstrates that optimizing for carbon yields design choices distinct from those optimized solely for latency or energy efficiency. We apply our framework to multi-modal CLIP-based models, producing CarbonCLIP, a family of CLIP models achieving up to 17% reduction in total carbon emissions while maintaining accuracy and latency compared to state-of-the-art edge small CLIP baselines. This work underscores the need for holistic optimization methods to design high-performance, environmentally sustainable AI systems.
Hardware Scaling Trends and Diminishing Returns in Large-Scale Distributed Training
Nov 20, 2024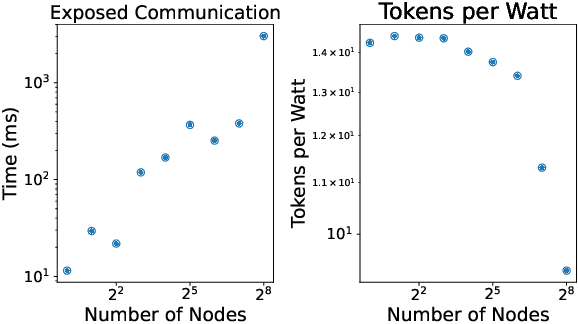

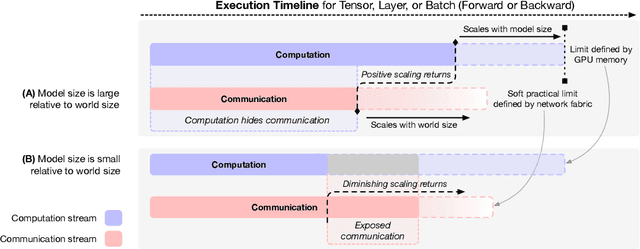
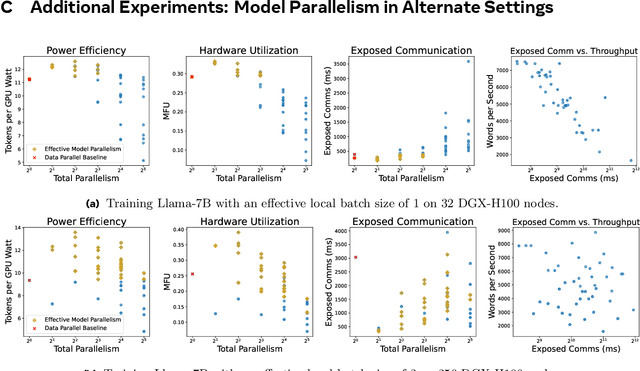
Dramatic increases in the capabilities of neural network models in recent years are driven by scaling model size, training data, and corresponding computational resources. To develop the exceedingly large networks required in modern applications, such as large language models (LLMs), model training is distributed across tens of thousands of hardware accelerators (e.g. GPUs), requiring orchestration of computation and communication across large computing clusters. In this work, we demonstrate that careful consideration of hardware configuration and parallelization strategy is critical for effective (i.e. compute- and cost-efficient) scaling of model size, training data, and total computation. We conduct an extensive empirical study of the performance of large-scale LLM training workloads across model size, hardware configurations, and distributed parallelization strategies. We demonstrate that: (1) beyond certain scales, overhead incurred from certain distributed communication strategies leads parallelization strategies previously thought to be sub-optimal in fact become preferable; and (2) scaling the total number of accelerators for large model training quickly yields diminishing returns even when hardware and parallelization strategies are properly optimized, implying poor marginal performance per additional unit of power or GPU-hour.
PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers in a resource-limited Context
Oct 23, 2024



Following their success in natural language processing (NLP), there has been a shift towards transformer models in computer vision. While transformers perform well and offer promising multi-tasking performance, due to their high compute requirements, many resource-constrained applications still rely on convolutional or hybrid models that combine the benefits of convolution and attention layers and achieve the best results in the sub 100M parameter range. Simultaneously, task adaptation techniques that allow for the use of one shared transformer backbone for multiple downstream tasks, resulting in great storage savings at negligible cost in performance, have not yet been adopted for hybrid transformers. In this work, we investigate how to achieve the best task-adaptation performance and introduce PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers. We further combine PETAH adaptation with pruning to achieve highly performant and storage friendly models for multi-tasking. In our extensive evaluation on classification and other vision tasks, we demonstrate that our PETAH-adapted hybrid models outperform established task-adaptation techniques for ViTs while requiring fewer parameters and being more efficient on mobile hardware.
Brevity is the soul of wit: Pruning long files for code generation
Jun 29, 2024


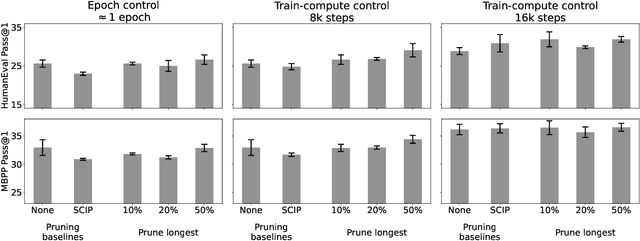
Data curation is commonly considered a "secret-sauce" for LLM training, with higher quality data usually leading to better LLM performance. Given the scale of internet-scraped corpora, data pruning has become a larger and larger focus. Specifically, many have shown that de-duplicating data, or sub-selecting higher quality data, can lead to efficiency or performance improvements. Generally, three types of methods are used to filter internet-scale corpora: embedding-based, heuristic-based, and classifier-based. In this work, we contrast the former two in the domain of finetuning LLMs for code generation. We find that embedding-based methods are often confounded by length, and that a simple heuristic--pruning long files--outperforms other methods in compute-limited regimes. Our method can yield up to a 2x efficiency benefit in training (while matching performance) or a 3.5% absolute performance improvement on HumanEval (while matching compute). However, we find that perplexity on held-out long files can increase, begging the question of whether optimizing data mixtures for common coding benchmarks (HumanEval, MBPP) actually best serves downstream use cases. Overall, we hope our work builds useful intuitions about code data (specifically, the low quality of extremely long code files) provides a compelling heuristic-based method for data pruning, and brings to light questions in how we evaluate code generation models.
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Apr 29, 2024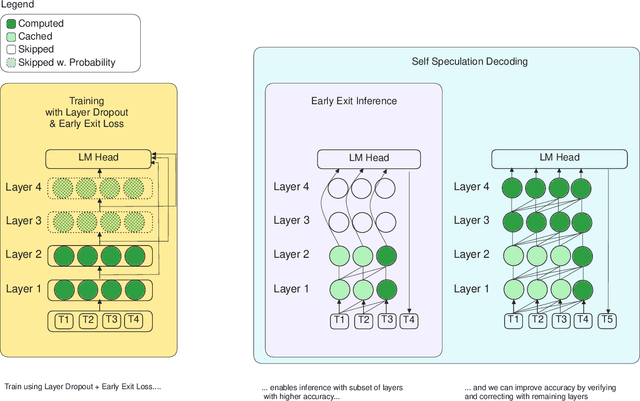
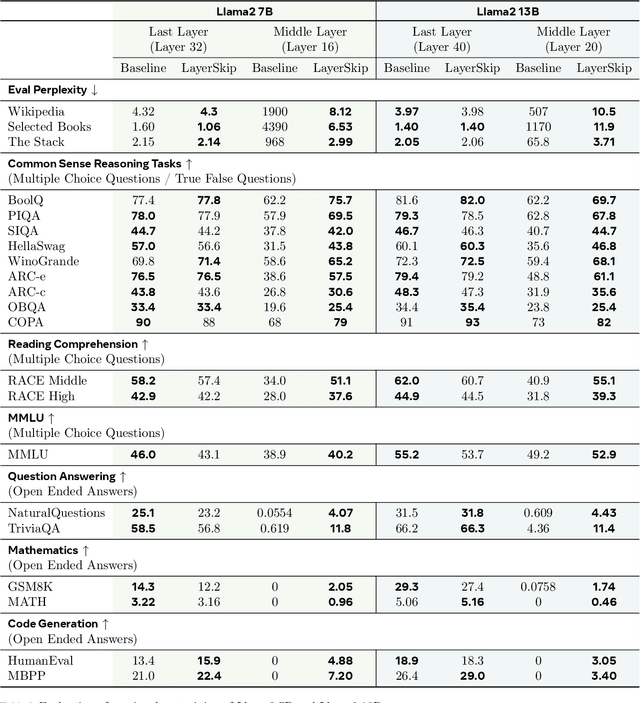
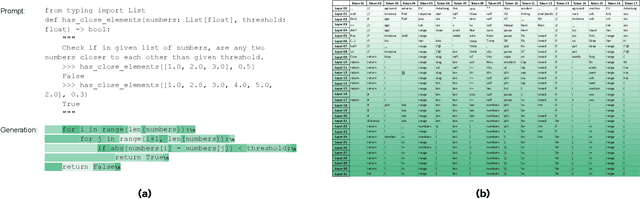
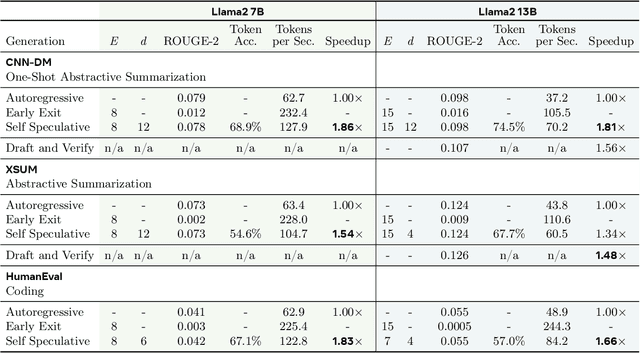
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
CHAI: Clustered Head Attention for Efficient LLM Inference
Mar 12, 2024



Large Language Models (LLMs) with hundreds of billions of parameters have transformed the field of machine learning. However, serving these models at inference time is both compute and memory intensive, where a single request can require multiple GPUs and tens of Gigabytes of memory. Multi-Head Attention is one of the key components of LLMs, which can account for over 50% of LLMs memory and compute requirement. We observe that there is a high amount of redundancy across heads on which tokens they pay attention to. Based on this insight, we propose Clustered Head Attention (CHAI). CHAI combines heads with a high amount of correlation for self-attention at runtime, thus reducing both memory and compute. In our experiments, we show that CHAI is able to reduce the memory requirements for storing K,V cache by up to 21.4% and inference time latency by up to 1.73x without any fine-tuning required. CHAI achieves this with a maximum 3.2% deviation in accuracy across 3 different models (i.e. OPT-66B, LLAMA-7B, LLAMA-33B) and 5 different evaluation datasets.
Evaluation of LLMs on Syntax-Aware Code Fill-in-the-Middle Tasks
Mar 07, 2024



We introduce Syntax-Aware Fill-In-the-Middle (SAFIM), a new benchmark for evaluating Large Language Models (LLMs) on the code Fill-in-the-Middle (FIM) task. This benchmark focuses on syntax-aware completions of program structures such as code blocks and conditional expressions, and includes 17,720 examples from multiple programming languages, sourced from recent code submissions after April 2022 to minimize data contamination. SAFIM provides a robust framework with various prompt designs and novel syntax-aware post-processing techniques, facilitating accurate and fair comparisons across LLMs. Our comprehensive evaluation of 15 LLMs shows that FIM pretraining not only enhances FIM proficiency but also improves Left-to-Right (L2R) inference using LLMs. Our findings challenge conventional beliefs and suggest that pretraining methods and data quality have more impact than model size. SAFIM thus serves as a foundational platform for future research in effective pretraining strategies for code LLMs. The evaluation toolkit and dataset are available at https://github.com/gonglinyuan/safim, and the leaderboard is available at https://safimbenchmark.com.
AST-T5: Structure-Aware Pretraining for Code Generation and Understanding
Jan 05, 2024



Large language models (LLMs) have made significant advancements in code-related tasks, yet many LLMs treat code as simple sequences, neglecting its structured nature. We introduce AST-T5, a novel pretraining paradigm that leverages the Abstract Syntax Tree (AST) for enhanced code generation, transpilation, and understanding. Using dynamic programming, our AST-Aware Segmentation retains code structure, while our AST-Aware Span Corruption objective equips the model to reconstruct various code structures. Unlike other models, AST-T5 avoids intricate program analyses or architectural changes, so it integrates seamlessly with any encoder-decoder Transformer. Evaluations show that AST-T5 consistently outperforms similar-sized LMs across various code-related tasks. Structure-awareness makes AST-T5 particularly powerful in code-to-code tasks, surpassing CodeT5 by 2 points in exact match score for the Bugs2Fix task and by 3 points in exact match score for Java-C# Transpilation in CodeXGLUE. Our code and model are publicly available at https://github.com/gonglinyuan/ast_t5.