 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
DASH: Detection and Assessment of Systematic Hallucinations of VLMs
Mar 30, 2025



Vision-language models (VLMs) are prone to object hallucinations, where they erroneously indicate the presenceof certain objects in an image. Existing benchmarks quantify hallucinations using relatively small, labeled datasets. However, this approach is i) insufficient to assess hallucinations that arise in open-world settings, where VLMs are widely used, and ii) inadequate for detecting systematic errors in VLMs. We propose DASH (Detection and Assessment of Systematic Hallucinations), an automatic, large-scale pipeline designed to identify systematic hallucinations of VLMs on real-world images in an open-world setting. A key component is DASH-OPT for image-based retrieval, where we optimize over the ''natural image manifold'' to generate images that mislead the VLM. The output of DASH consists of clusters of real and semantically similar images for which the VLM hallucinates an object. We apply DASH to PaliGemma and two LLaVA-NeXT models across 380 object classes and, in total, find more than 19k clusters with 950k images. We study the transfer of the identified systematic hallucinations to other VLMs and show that fine-tuning PaliGemma with the model-specific images obtained with DASH mitigates object hallucinations. Code and data are available at https://YanNeu.github.io/DASH.
PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers in a resource-limited Context
Oct 23, 2024Following their success in natural language processing (NLP), there has been a shift towards transformer models in computer vision. While transformers perform well and offer promising multi-tasking performance, due to their high compute requirements, many resource-constrained applications still rely on convolutional or hybrid models that combine the benefits of convolution and attention layers and achieve the best results in the sub 100M parameter range. Simultaneously, task adaptation techniques that allow for the use of one shared transformer backbone for multiple downstream tasks, resulting in great storage savings at negligible cost in performance, have not yet been adopted for hybrid transformers. In this work, we investigate how to achieve the best task-adaptation performance and introduce PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers. We further combine PETAH adaptation with pruning to achieve highly performant and storage friendly models for multi-tasking. In our extensive evaluation on classification and other vision tasks, we demonstrate that our PETAH-adapted hybrid models outperform established task-adaptation techniques for ViTs while requiring fewer parameters and being more efficient on mobile hardware.
Analyzing and Explaining Image Classifiers via Diffusion Guidance
Nov 29, 2023



While deep learning has led to huge progress in complex image classification tasks like ImageNet, unexpected failure modes, e.g. via spurious features, call into question how reliably these classifiers work in the wild. Furthermore, for safety-critical tasks the black-box nature of their decisions is problematic, and explanations or at least methods which make decisions plausible are needed urgently. In this paper, we address these problems by generating images that optimize a classifier-derived objective using a framework for guided image generation. We analyze the behavior and decisions of image classifiers by visual counterfactual explanations (VCEs), detection of systematic mistakes by analyzing images where classifiers maximally disagree, and visualization of neurons to verify potential spurious features. In this way, we validate existing observations, e.g. the shape bias of adversarially robust models, as well as novel failure modes, e.g. systematic errors of zero-shot CLIP classifiers, or identify harmful spurious features. Moreover, our VCEs outperform previous work while being more versatile.
Spurious Features Everywhere -- Large-Scale Detection of Harmful Spurious Features in ImageNet
Dec 09, 2022Benchmark performance of deep learning classifiers alone is not a reliable predictor for the performance of a deployed model. In particular, if the image classifier has picked up spurious features in the training data, its predictions can fail in unexpected ways. In this paper, we develop a framework that allows us to systematically identify spurious features in large datasets like ImageNet. It is based on our neural PCA components and their visualization. Previous work on spurious features of image classifiers often operates in toy settings or requires costly pixel-wise annotations. In contrast, we validate our results by checking that presence of the harmful spurious feature of a class is sufficient to trigger the prediction of that class. We introduce a novel dataset "Spurious ImageNet" and check how much existing classifiers rely on spurious features.
Breaking Down Out-of-Distribution Detection: Many Methods Based on OOD Training Data Estimate a Combination of the Same Core Quantities
Jun 20, 2022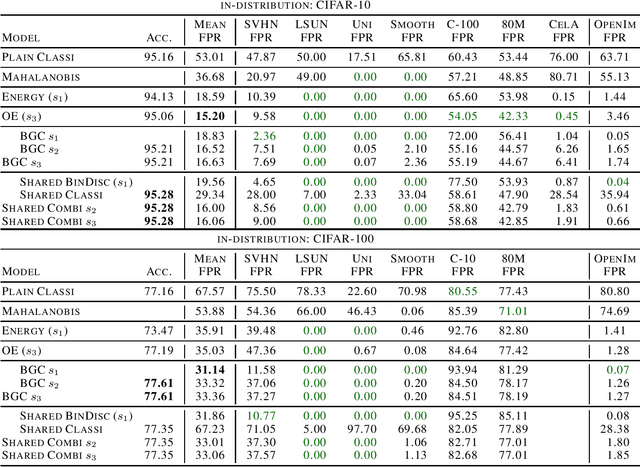
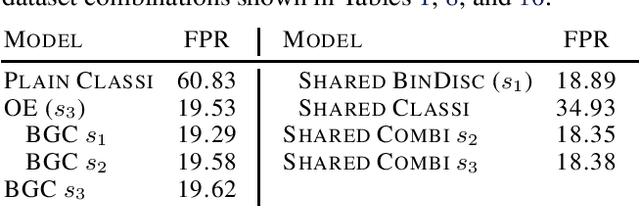
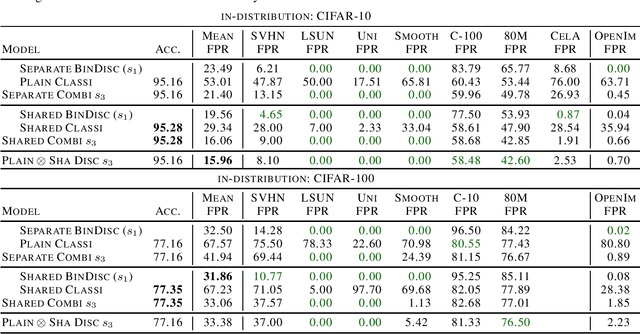

It is an important problem in trustworthy machine learning to recognize out-of-distribution (OOD) inputs which are inputs unrelated to the in-distribution task. Many out-of-distribution detection methods have been suggested in recent years. The goal of this paper is to recognize common objectives as well as to identify the implicit scoring functions of different OOD detection methods. We focus on the sub-class of methods that use surrogate OOD data during training in order to learn an OOD detection score that generalizes to new unseen out-distributions at test time. We show that binary discrimination between in- and (different) out-distributions is equivalent to several distinct formulations of the OOD detection problem. When trained in a shared fashion with a standard classifier, this binary discriminator reaches an OOD detection performance similar to that of Outlier Exposure. Moreover, we show that the confidence loss which is used by Outlier Exposure has an implicit scoring function which differs in a non-trivial fashion from the theoretically optimal scoring function in the case where training and test out-distribution are the same, which again is similar to the one used when training an Energy-Based OOD detector or when adding a background class. In practice, when trained in exactly the same way, all these methods perform similarly.
Sparse Visual Counterfactual Explanations in Image Space
May 16, 2022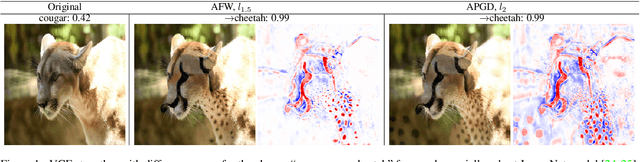
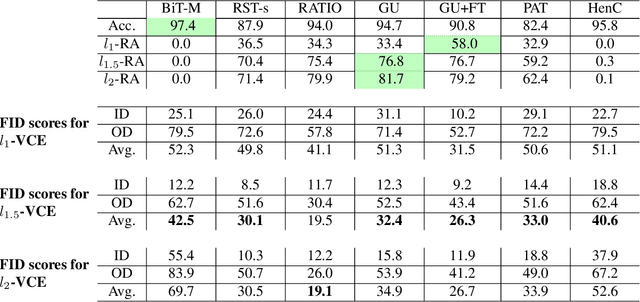


Visual counterfactual explanations (VCEs) in image space are an important tool to understand decisions of image classifiers as they show under which changes of the image the decision of the classifier would change. Their generation in image space is challenging and requires robust models due to the problem of adversarial examples. Existing techniques to generate VCEs in image space suffer from spurious changes in the background. Our novel perturbation model for VCEs together with its efficient optimization via our novel Auto-Frank-Wolfe scheme yields sparse VCEs which are significantly more object-centric. Moreover, we show that VCEs can be used to detect undesired behavior of ImageNet classifiers due to spurious features in the ImageNet dataset and discuss how estimates of the data-generating distribution can be used for VCEs.
Out-distribution aware Self-training in an Open World Setting
Dec 21, 2020
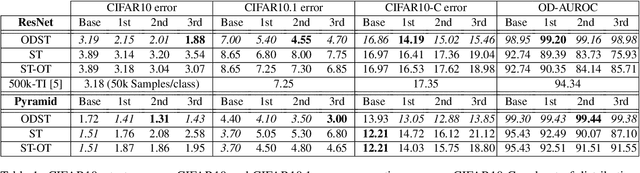
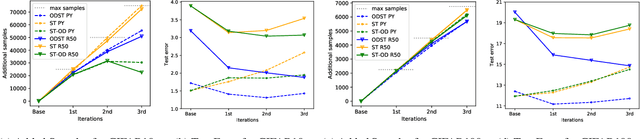
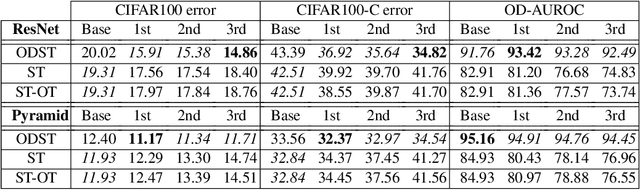
Deep Learning heavily depends on large labeled datasets which limits further improvements. While unlabeled data is available in large amounts, in particular in image recognition, it does not fulfill the closed world assumption of semi-supervised learning that all unlabeled data are task-related. The goal of this paper is to leverage unlabeled data in an open world setting to further improve prediction performance. For this purpose, we introduce out-distribution aware self-training, which includes a careful sample selection strategy based on the confidence of the classifier. While normal self-training deteriorates prediction performance, our iterative scheme improves using up to 15 times the amount of originally labeled data. Moreover, our classifiers are by design out-distribution aware and can thus distinguish task-related inputs from unrelated ones.