 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Outlier Distribution in Large Language Models: An In-depth Study
May 27, 2025



Investigating outliers in large language models (LLMs) is crucial due to their significant impact on various aspects of LLM performance, including quantization and compression. Outliers often cause considerable quantization errors, leading to degraded model performance. Identifying and addressing these outliers can enhance the accuracy and efficiency of the quantization process, enabling smoother deployment on edge devices or specialized hardware. Recent studies have identified two common types of outliers in LLMs: massive activations and channel-wise outliers. While numerous quantization algorithms have been proposed to mitigate their effects and maintain satisfactory accuracy, few have thoroughly explored the root causes of these outliers in depth. In this paper, we conduct a comprehensive investigation into the formation mechanisms of these outliers and propose potential strategies to mitigate their occurrence. Ultimately, we introduce some efficient approaches to eliminate most massive activations and channel-wise outliers with minimal impact on accuracy.
DREAM: Drafting with Refined Target Features and Entropy-Adaptive Cross-Attention Fusion for Multimodal Speculative Decoding
May 25, 2025Speculative decoding (SD) has emerged as a powerful method for accelerating autoregressive generation in large language models (LLMs), yet its integration into vision-language models (VLMs) remains underexplored. We introduce DREAM, a novel speculative decoding framework tailored for VLMs that combines three key innovations: (1) a cross-attention-based mechanism to inject intermediate features from the target model into the draft model for improved alignment, (2) adaptive intermediate feature selection based on attention entropy to guide efficient draft model training, and (3) visual token compression to reduce draft model latency. DREAM enables efficient, accurate, and parallel multimodal decoding with significant throughput improvement. Experiments across a diverse set of recent popular VLMs, including LLaVA, Pixtral, SmolVLM and Gemma3, demonstrate up to 3.6x speedup over conventional decoding and significantly outperform prior SD baselines in both inference throughput and speculative draft acceptance length across a broad range of multimodal benchmarks. The code is publicly available at: https://github.com/SAI-Lab-NYU/DREAM.git
PipeSpec: Breaking Stage Dependencies in Hierarchical LLM Decoding
May 02, 2025Speculative decoding accelerates large language model inference by using smaller draft models to generate candidate tokens for parallel verification. However, current approaches are limited by sequential stage dependencies that prevent full hardware utilization. We present PipeSpec, a framework that generalizes speculative decoding to $k$ models arranged in a hierarchical pipeline, enabling asynchronous execution with lightweight coordination for prediction verification and rollback. Our analytical model characterizes token generation rates across pipeline stages and proves guaranteed throughput improvements over traditional decoding for any non-zero acceptance rate. We further derive closed-form expressions for steady-state verification probabilities that explain the empirical benefits of pipeline depth. Experimental results show that PipeSpec achieves up to 2.54$\times$ speedup while outperforming state-of-the-art methods. We validate PipeSpec across text summarization and code generation tasks using LLaMA 2 and 3 models, demonstrating that pipeline efficiency increases with model depth, providing a scalable approach to accelerating LLM inference on multi-device systems.
Foveated Instance Segmentation
Mar 27, 2025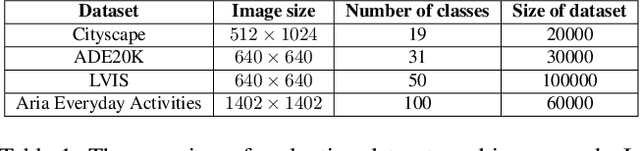
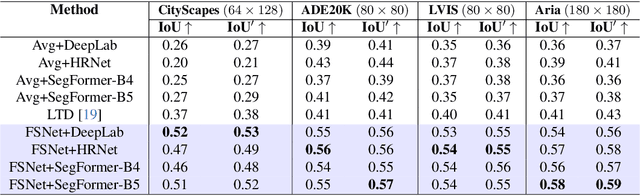
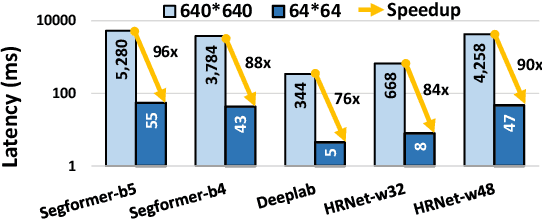
Instance segmentation is essential for augmented reality and virtual reality (AR/VR) as it enables precise object recognition and interaction, enhancing the integration of virtual and real-world elements for an immersive experience. However, the high computational overhead of segmentation limits its application on resource-constrained AR/VR devices, causing large processing latency and degrading user experience. In contrast to conventional scenarios, AR/VR users typically focus on only a few regions within their field of view before shifting perspective, allowing segmentation to be concentrated on gaze-specific areas. This insight drives the need for efficient segmentation methods that prioritize processing instance of interest, reducing computational load and enhancing real-time performance. In this paper, we present a foveated instance segmentation (FovealSeg) framework that leverages real-time user gaze data to perform instance segmentation exclusively on instance of interest, resulting in substantial computational savings. Evaluation results show that FSNet achieves an IoU of 0.56 on ADE20K and 0.54 on LVIS, notably outperforming the baseline. The code is available at https://github.com/SAI-
Speculative Decoding and Beyond: An In-Depth Review of Techniques
Feb 27, 2025Sequential dependencies present a fundamental bottleneck in deploying large-scale autoregressive models, particularly for real-time applications. While traditional optimization approaches like pruning and quantization often compromise model quality, recent advances in generation-refinement frameworks demonstrate that this trade-off can be significantly mitigated. This survey presents a comprehensive taxonomy of generation-refinement frameworks, analyzing methods across autoregressive sequence tasks. We categorize methods based on their generation strategies (from simple n-gram prediction to sophisticated draft models) and refinement mechanisms (including single-pass verification and iterative approaches). Through systematic analysis of both algorithmic innovations and system-level implementations, we examine deployment strategies across computing environments and explore applications spanning text, images, and speech generation. This systematic examination of both theoretical frameworks and practical implementations provides a foundation for future research in efficient autoregressive decoding.
Huff-LLM: End-to-End Lossless Compression for Efficient LLM Inference
Feb 02, 2025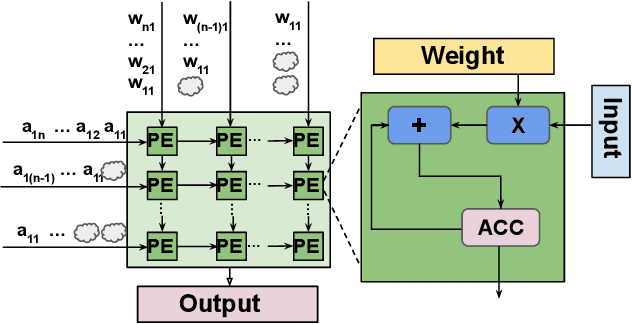
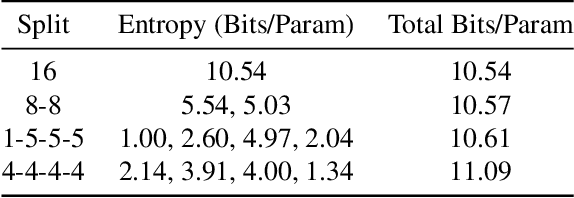
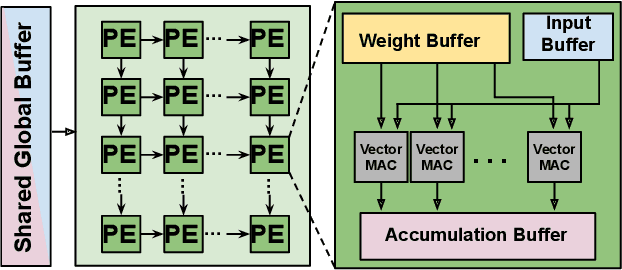

As they become more capable, large language models (LLMs) have continued to rapidly increase in size. This has exacerbated the difficulty in running state of the art LLMs on small, edge devices. Standard techniques advocate solving this problem through lossy compression techniques such as quantization or pruning. However, such compression techniques are lossy, and have been shown to change model behavior in unpredictable manners. We propose Huff-LLM, an \emph{end-to-end, lossless} model compression method that lets users store LLM weights in compressed format \emph{everywhere} -- cloud, disk, main memory, and even in on-chip memory/buffers. This allows us to not only load larger models in main memory, but also reduces bandwidth required to load weights on chip, and makes more efficient use of on-chip weight buffers. In addition to the memory savings achieved via compression, we also show latency and energy efficiency improvements when performing inference with the compressed model.
FovealNet: Advancing AI-Driven Gaze Tracking Solutions for Optimized Foveated Rendering System Performance in Virtual Reality
Dec 12, 2024



Leveraging real-time eye-tracking, foveated rendering optimizes hardware efficiency and enhances visual quality virtual reality (VR). This approach leverages eye-tracking techniques to determine where the user is looking, allowing the system to render high-resolution graphics only in the foveal region-the small area of the retina where visual acuity is highest, while the peripheral view is rendered at lower resolution. However, modern deep learning-based gaze-tracking solutions often exhibit a long-tail distribution of tracking errors, which can degrade user experience and reduce the benefits of foveated rendering by causing misalignment and decreased visual quality. This paper introduces \textit{FovealNet}, an advanced AI-driven gaze tracking framework designed to optimize system performance by strategically enhancing gaze tracking accuracy. To further reduce the implementation cost of the gaze tracking algorithm, FovealNet employs an event-based cropping method that eliminates over $64.8\%$ of irrelevant pixels from the input image. Additionally, it incorporates a simple yet effective token-pruning strategy that dynamically removes tokens on the fly without compromising tracking accuracy. Finally, to support different runtime rendering configurations, we propose a system performance-aware multi-resolution training strategy, allowing the gaze tracking DNN to adapt and optimize overall system performance more effectively. Evaluation results demonstrate that FovealNet achieves at least $1.42\times$ speed up compared to previous methods and 13\% increase in perceptual quality for foveated output.
Unlocking Visual Secrets: Inverting Features with Diffusion Priors for Image Reconstruction
Dec 11, 2024Inverting visual representations within deep neural networks (DNNs) presents a challenging and important problem in the field of security and privacy for deep learning. The main goal is to invert the features of an unidentified target image generated by a pre-trained DNN, aiming to reconstruct the original image. Feature inversion holds particular significance in understanding the privacy leakage inherent in contemporary split DNN execution techniques, as well as in various applications based on the extracted DNN features. In this paper, we explore the use of diffusion models, a promising technique for image synthesis, to enhance feature inversion quality. We also investigate the potential of incorporating alternative forms of prior knowledge, such as textual prompts and cross-frame temporal correlations, to further improve the quality of inverted features. Our findings reveal that diffusion models can effectively leverage hidden information from the DNN features, resulting in superior reconstruction performance compared to previous methods. This research offers valuable insights into how diffusion models can enhance privacy and security within applications that are reliant on DNN features.
DFRot: Achieving Outlier-Free and Massive Activation-Free for Rotated LLMs with Refined Rotation
Dec 03, 2024



Rotating the activation and weight matrices to reduce the influence of outliers in large language models (LLMs) has recently attracted significant attention, particularly in the context of model quantization. Prior studies have shown that in low-precision quantization scenarios, such as 4-bit weights and 4-bit activations (W4A4), randomized Hadamard transforms can achieve significantly higher accuracy than randomized orthogonal transforms. Notably, the reason behind this phenomena remains unknown. In this paper, we find that these transformations show substantial improvement in eliminating outliers for common tokens and achieve similar quantization error. The primary reason for the accuracy difference lies in the fact that randomized Hadamard transforms can slightly reduce the quantization error for tokens with massive activations while randomized orthogonal transforms increase the quantization error. Due to the extreme rarity of these tokens and their critical impact on model accuracy, we consider this a long-tail optimization problem, and therefore construct a simple yet effective method: a weighted loss function. Additionally, we propose an optimization strategy for the rotation matrix that involves alternating optimization of quantization parameters while employing orthogonal Procrustes transforms to refine the rotation matrix. This makes the distribution of the rotated activation values more conducive to quantization, especially for tokens with massive activations. Our method enhances the Rotated LLMs by achieving dual free, Outlier-Free and Massive Activation-Free, dubbed as DFRot. Extensive experiments demonstrate the effectiveness and efficiency of DFRot. By tuning the rotation matrix using just a single sample, DFRot achieves a perplexity improvement of 0.25 and 0.21 on W4A4KV4 and W4A4KV16, respectively, for LLaMA3-8B, a model known for its quantization challenges.
GazeGen: Gaze-Driven User Interaction for Visual Content Generation
Nov 07, 2024

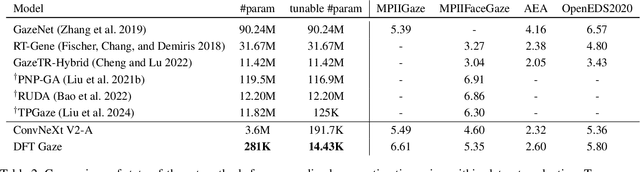
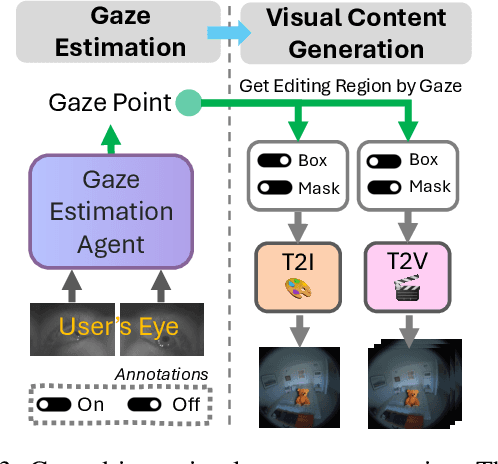
We present GazeGen, a user interaction system that generates visual content (images and videos) for locations indicated by the user's eye gaze. GazeGen allows intuitive manipulation of visual content by targeting regions of interest with gaze. Using advanced techniques in object detection and generative AI, GazeGen performs gaze-controlled image adding/deleting, repositioning, and surface material changes of image objects, and converts static images into videos. Central to GazeGen is the DFT Gaze (Distilled and Fine-Tuned Gaze) agent, an ultra-lightweight model with only 281K parameters, performing accurate real-time gaze predictions tailored to individual users' eyes on small edge devices. GazeGen is the first system to combine visual content generation with real-time gaze estimation, made possible exclusively by DFT Gaze. This real-time gaze estimation enables various visual content generation tasks, all controlled by the user's gaze. The input for DFT Gaze is the user's eye images, while the inputs for visual content generation are the user's view and the predicted gaze point from DFT Gaze. To achieve efficient gaze predictions, we derive the small model from a large model (10x larger) via novel knowledge distillation and personal adaptation techniques. We integrate knowledge distillation with a masked autoencoder, developing a compact yet powerful gaze estimation model. This model is further fine-tuned with Adapters, enabling highly accurate and personalized gaze predictions with minimal user input. DFT Gaze ensures low-latency and precise gaze tracking, supporting a wide range of gaze-driven tasks. We validate the performance of DFT Gaze on AEA and OpenEDS2020 benchmarks, demonstrating low angular gaze error and low latency on the edge device (Raspberry Pi 4). Furthermore, we describe applications of GazeGen, illustrating its versatility and effectiveness in various usage scenarios.