 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM: Drafting with Refined Target Features and Entropy-Adaptive Cross-Attention Fusion for Multimodal Speculative Decoding
May 25, 2025Speculative decoding (SD) has emerged as a powerful method for accelerating autoregressive generation in large language models (LLMs), yet its integration into vision-language models (VLMs) remains underexplored. We introduce DREAM, a novel speculative decoding framework tailored for VLMs that combines three key innovations: (1) a cross-attention-based mechanism to inject intermediate features from the target model into the draft model for improved alignment, (2) adaptive intermediate feature selection based on attention entropy to guide efficient draft model training, and (3) visual token compression to reduce draft model latency. DREAM enables efficient, accurate, and parallel multimodal decoding with significant throughput improvement. Experiments across a diverse set of recent popular VLMs, including LLaVA, Pixtral, SmolVLM and Gemma3, demonstrate up to 3.6x speedup over conventional decoding and significantly outperform prior SD baselines in both inference throughput and speculative draft acceptance length across a broad range of multimodal benchmarks. The code is publicly available at: https://github.com/SAI-Lab-NYU/DREAM.git
Foveated Instance Segmentation
Mar 27, 2025
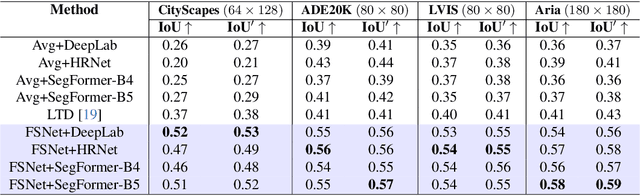
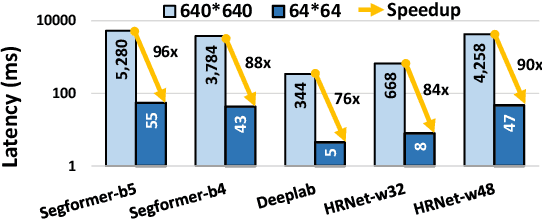
Instance segmentation is essential for augmented reality and virtual reality (AR/VR) as it enables precise object recognition and interaction, enhancing the integration of virtual and real-world elements for an immersive experience. However, the high computational overhead of segmentation limits its application on resource-constrained AR/VR devices, causing large processing latency and degrading user experience. In contrast to conventional scenarios, AR/VR users typically focus on only a few regions within their field of view before shifting perspective, allowing segmentation to be concentrated on gaze-specific areas. This insight drives the need for efficient segmentation methods that prioritize processing instance of interest, reducing computational load and enhancing real-time performance. In this paper, we present a foveated instance segmentation (FovealSeg) framework that leverages real-time user gaze data to perform instance segmentation exclusively on instance of interest, resulting in substantial computational savings. Evaluation results show that FSNet achieves an IoU of 0.56 on ADE20K and 0.54 on LVIS, notably outperforming the baseline. The code is available at https://github.com/SAI-
Huff-LLM: End-to-End Lossless Compression for Efficient LLM Inference
Feb 02, 2025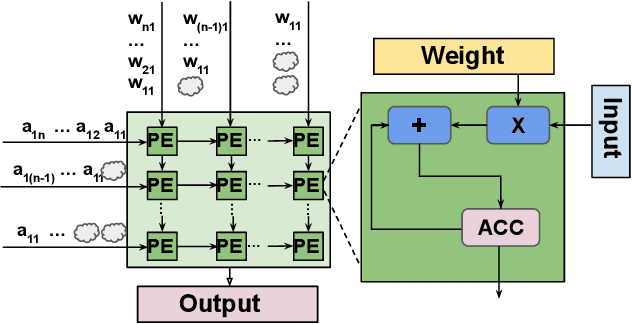
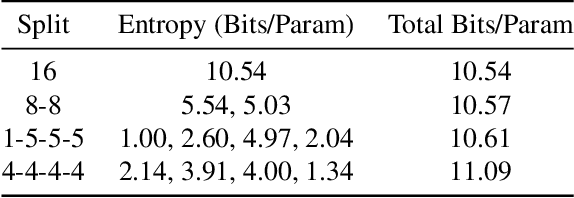
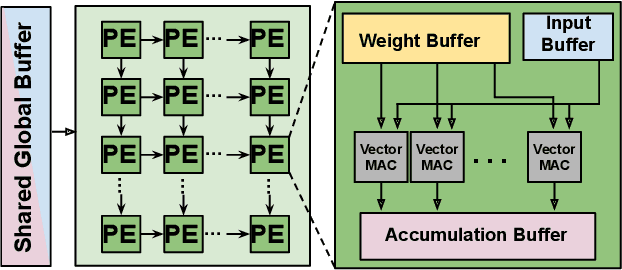

As they become more capable, large language models (LLMs) have continued to rapidly increase in size. This has exacerbated the difficulty in running state of the art LLMs on small, edge devices. Standard techniques advocate solving this problem through lossy compression techniques such as quantization or pruning. However, such compression techniques are lossy, and have been shown to change model behavior in unpredictable manners. We propose Huff-LLM, an \emph{end-to-end, lossless} model compression method that lets users store LLM weights in compressed format \emph{everywhere} -- cloud, disk, main memory, and even in on-chip memory/buffers. This allows us to not only load larger models in main memory, but also reduces bandwidth required to load weights on chip, and makes more efficient use of on-chip weight buffers. In addition to the memory savings achieved via compression, we also show latency and energy efficiency improvements when performing inference with the compressed model.