 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts-Agent: Data Recipes for Agentic Models
Jun 23, 2026Agentic language models dramatically expand the applications of AI yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks and a 3.9 percentage point improvement over the strongest existing open data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons. We publicly release our training sets, data pipeline, experimental data, and models at openthoughts.ai to support future open research on agentic model training.
Exploring the Agentic Frontier of Verilog Code Generation
Mar 19, 2026Large language models (LLMs) have made rapid advancements in code generation for popular languages such as Python and C++. Many of these recent gains can be attributed to the use of ``agents'' that wrap domain-relevant tools alongside LLMs. Hardware design languages such as Verilog have also seen improved code generation in recent years, but the impact of agentic frameworks on Verilog code generation tasks remains unclear. In this work, we present the first systematic evaluation of agentic LLMs for Verilog generation, using the recently introduced CVDP benchmark. We also introduce several open-source hardware design agent harnesses, providing a model-agnostic baseline for future work. Through controlled experiments across frontier models, we study how structured prompting and tool design affect performance, analyze agent failure modes and tool usage patterns, compare open-source and closed-source models, and provide qualitative examples of successful and failed agent runs. Our results show that naive agentic wrapping around frontier models can degrade performance (relative to standard forward passes with optimized prompts), but that structured harnesses meaningfully match and in some cases exceed non-agentic baselines. We find that the performance gap between open and closed source models is driven by both higher crash rates and weaker tool output interpretation. Our exploration illuminates the path towards designing special-purpose agents for verilog generation in the future.
Discovering Sparse Recovery Algorithms Using Neural Architecture Search
Dec 25, 2025The design of novel algorithms for solving inverse problems in signal processing is an incredibly difficult, heuristic-driven, and time-consuming task. In this short paper, we the idea of automated algorithm discovery in the signal processing context through meta-learning tools such as Neural Architecture Search (NAS). Specifically, we examine the Iterative Shrinkage Thresholding Algorithm (ISTA) and its accelerated Fast ISTA (FISTA) variant as candidates for algorithm rediscovery. We develop a meta-learning framework which is capable of rediscovering (several key elements of) the two aforementioned algorithms when given a search space of over 50,000 variables. We then show how our framework can apply to various data distributions and algorithms besides ISTA/FISTA.
Huff-LLM: End-to-End Lossless Compression for Efficient LLM Inference
Feb 02, 2025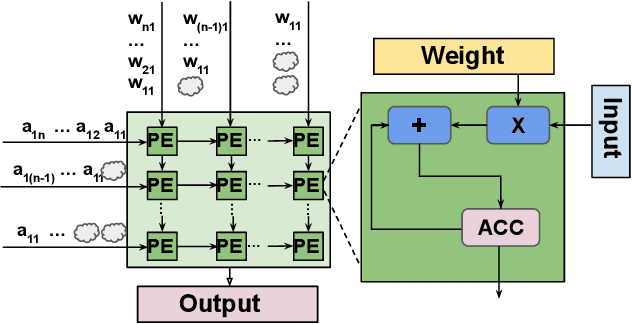
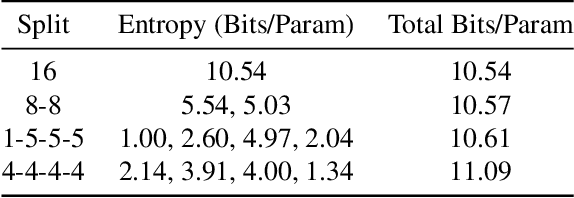

As they become more capable, large language models (LLMs) have continued to rapidly increase in size. This has exacerbated the difficulty in running state of the art LLMs on small, edge devices. Standard techniques advocate solving this problem through lossy compression techniques such as quantization or pruning. However, such compression techniques are lossy, and have been shown to change model behavior in unpredictable manners. We propose Huff-LLM, an \emph{end-to-end, lossless} model compression method that lets users store LLM weights in compressed format \emph{everywhere} -- cloud, disk, main memory, and even in on-chip memory/buffers. This allows us to not only load larger models in main memory, but also reduces bandwidth required to load weights on chip, and makes more efficient use of on-chip weight buffers. In addition to the memory savings achieved via compression, we also show latency and energy efficiency improvements when performing inference with the compressed model.
TruncFormer: Private LLM Inference Using Only Truncations
Dec 02, 2024


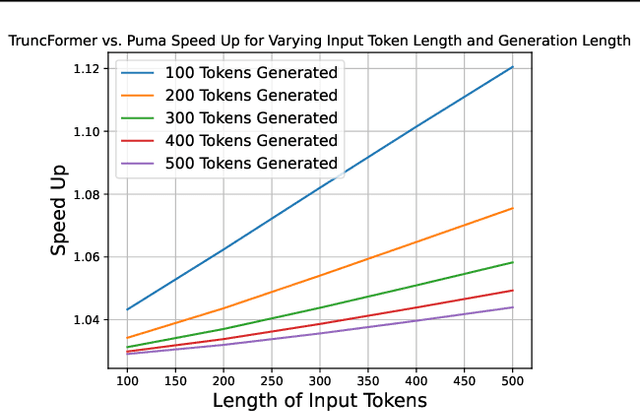
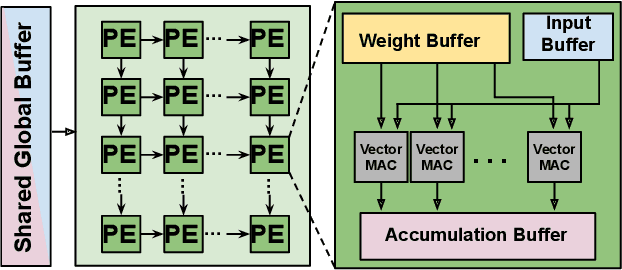
Private inference (PI) serves an important role in guaranteeing the privacy of user data when interfacing with proprietary machine learning models such as LLMs. However, PI remains practically intractable due to the massive latency costs associated with nonlinear functions present in LLMs. Existing works have focused on improving latency of specific LLM nonlinearities (such as the Softmax, or the GeLU) via approximations. However, new types of nonlinearities are regularly introduced with new LLM architectures, and this has led to a constant game of catch-up where PI researchers attempt to optimize the newest nonlinear function. We introduce TruncFormer, a framework for taking any LLM and transforming it into a plaintext emulation of PI. Our framework leverages the fact that nonlinearities in LLMs are differentiable and can be accurately approximated with a sequence of additions, multiplications, and truncations. Further, we decouple the add/multiply and truncation operations, and statically determine where truncations should be inserted based on a given field size and input representation size. This leads to latency improvements over existing cryptographic protocols that enforce truncation after every multiplication operation. We open source our code for community use.
SELECT: A Large-Scale Benchmark of Data Curation Strategies for Image Classification
Oct 07, 2024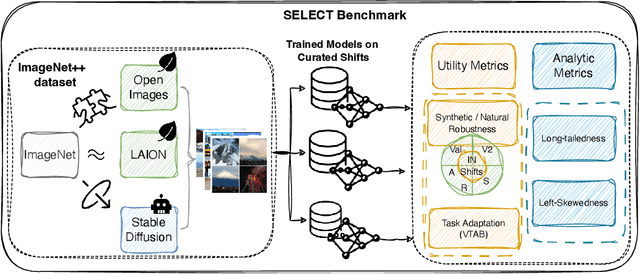
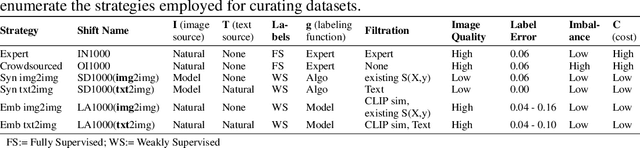

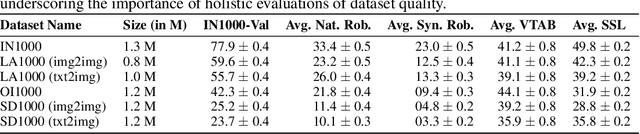
Data curation is the problem of how to collect and organize samples into a dataset that supports efficient learning. Despite the centrality of the task, little work has been devoted towards a large-scale, systematic comparison of various curation methods. In this work, we take steps towards a formal evaluation of data curation strategies and introduce SELECT, the first large-scale benchmark of curation strategies for image classification. In order to generate baseline methods for the SELECT benchmark, we create a new dataset, ImageNet++, which constitutes the largest superset of ImageNet-1K to date. Our dataset extends ImageNet with 5 new training-data shifts, each approximately the size of ImageNet-1K itself, and each assembled using a distinct curation strategy. We evaluate our data curation baselines in two ways: (i) using each training-data shift to train identical image classification models from scratch (ii) using the data itself to fit a pretrained self-supervised representation. Our findings show interesting trends, particularly pertaining to recent methods for data curation such as synthetic data generation and lookup based on CLIP embeddings. We show that although these strategies are highly competitive for certain tasks, the curation strategy used to assemble the original ImageNet-1K dataset remains the gold standard. We anticipate that our benchmark can illuminate the path for new methods to further reduce the gap. We release our checkpoints, code, documentation, and a link to our dataset at https://github.com/jimmyxu123/SELECT.