 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws
May 20, 2026Scaling laws have made language-model performance predictable from model size, data, and compute, but they typically treat the optimizer as a fixed training detail. We show that this assumption misses a fundamental axis of representation scaling: how effectively the optimizer converts added FFN width into utilized spectral capacity. Using eigenspectra of feed-forward network representations, measured through soft and hard spectral-ranks, we find that \emph{the same Transformer architecture realizes markedly different spectral scaling laws when trained with different optimizers}. Holding architecture and width schedule fixed, AdamW exhibits weak hard-rank scaling ($β$=0.44) on rare-token (TAIL) representations where learning is known to be hardest, whereas Muon achieves linear scaling ($β$=1.02) in the same regimes, a $2.3\times$ increase in the scaling exponent. This difference is not reducible to validation loss: AdamW configurations can match low-rank Dion variants in perplexity, under extended training, while exhibiting sharply different spectral geometry, demonstrating that matched loss does not imply matched representation structure. Hard--soft rank asymmetry further reveals that optimizers differ not only in how much capacity is realized, but also in how that capacity is structured across eigenmodes. To disentangle optimizer effects from architectural ones, we compare against architectural interventions (e.g., attention rank and positional encoding), and find that optimizer-induced spectral shifts often exceed the architectural effects. These results suggest optimization as a first-class axis of representation scaling, motivating optimizer--architecture co-design.
Spectral Scaling Laws in Language Models: How Effectively Do Feed-Forward Networks Use Their Latent Space?
Oct 01, 2025As large language models (LLMs) scale, the question is not only how large they become, but how much of their capacity is effectively utilized. Existing scaling laws relate model size to loss, yet overlook how components exploit their latent space. We study feed-forward networks (FFNs) and recast width selection as a spectral utilization problem. Using a lightweight diagnostic suite -- Hard Rank (participation ratio), Soft Rank (Shannon rank), Spectral Concentration, and the composite Spectral Utilization Index (SUI) -- we quantify how many latent directions are meaningfully activated across LLaMA, GPT-2, and nGPT families. Our key finding is an asymmetric spectral scaling law: soft rank follows an almost perfect power law with FFN width, while hard rank grows only sublinearly and with high variance. This asymmetry suggests that widening FFNs mostly adds low-energy tail directions, while dominant-mode subspaces saturate early. Moreover, at larger widths, variance further collapses into a narrow subspace, leaving much of the latent space under-utilized. These results recast FFN width selection as a principled trade-off between tail capacity and dominant-mode capacity, offering concrete guidance for inference-efficient LLM design.
Entropy-Guided Attention for Private LLMs
Jan 07, 2025



The pervasiveness of proprietary language models has raised critical privacy concerns, necessitating advancements in private inference (PI), where computations are performed directly on encrypted data without revealing users' sensitive information. While PI offers a promising solution, its practical deployment is hindered by substantial communication and latency overheads, primarily stemming from nonlinear operations. To address this, we introduce an information-theoretic framework to characterize the role of nonlinearities in decoder-only language models, laying a principled foundation for optimizing transformer-architectures tailored to the demands of PI. By leveraging Shannon's entropy as a quantitative measure, we uncover the previously unexplored dual significance of nonlinearities: beyond ensuring training stability, they are crucial for maintaining attention head diversity. Specifically, we find that their removal triggers two critical failure modes: {\em entropy collapse} in deeper layers that destabilizes training, and {\em entropic overload} in earlier layers that leads to under-utilization of Multi-Head Attention's (MHA) representational capacity. We propose an entropy-guided attention mechanism paired with a novel entropy regularization technique to mitigate entropic overload. Additionally, we explore PI-friendly alternatives to layer normalization for preventing entropy collapse and stabilizing the training of LLMs with reduced-nonlinearities. Our study bridges the gap between information theory and architectural design, establishing entropy dynamics as a principled guide for developing efficient PI architectures. The code and implementation are available at \href{https://github.com/Nandan91/entropy-guided-attention-llm}{entropy-guided-llm}.
TruncFormer: Private LLM Inference Using Only Truncations
Dec 02, 2024


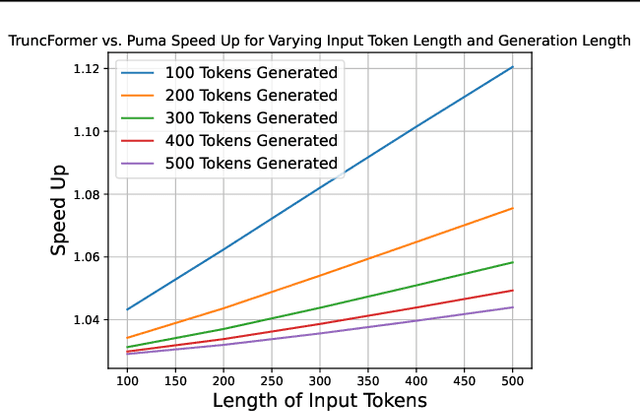
Private inference (PI) serves an important role in guaranteeing the privacy of user data when interfacing with proprietary machine learning models such as LLMs. However, PI remains practically intractable due to the massive latency costs associated with nonlinear functions present in LLMs. Existing works have focused on improving latency of specific LLM nonlinearities (such as the Softmax, or the GeLU) via approximations. However, new types of nonlinearities are regularly introduced with new LLM architectures, and this has led to a constant game of catch-up where PI researchers attempt to optimize the newest nonlinear function. We introduce TruncFormer, a framework for taking any LLM and transforming it into a plaintext emulation of PI. Our framework leverages the fact that nonlinearities in LLMs are differentiable and can be accurately approximated with a sequence of additions, multiplications, and truncations. Further, we decouple the add/multiply and truncation operations, and statically determine where truncations should be inserted based on a given field size and input representation size. This leads to latency improvements over existing cryptographic protocols that enforce truncation after every multiplication operation. We open source our code for community use.
AERO: Softmax-Only LLMs for Efficient Private Inference
Oct 16, 2024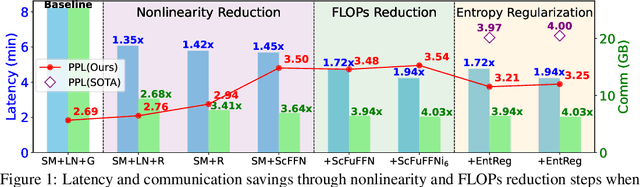

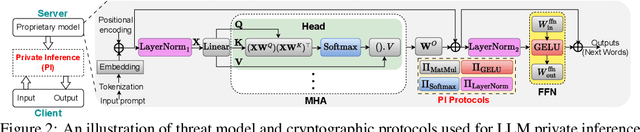
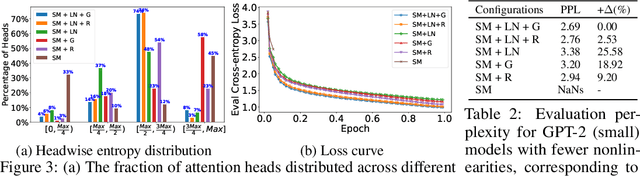
The pervasiveness of proprietary language models has raised privacy concerns for users' sensitive data, emphasizing the need for private inference (PI), where inference is performed directly on encrypted inputs. However, current PI methods face prohibitively higher communication and latency overheads, primarily due to nonlinear operations. In this paper, we present a comprehensive analysis to understand the role of nonlinearities in transformer-based decoder-only language models. We introduce AERO, a four-step architectural optimization framework that refines the existing LLM architecture for efficient PI by systematically removing nonlinearities such as LayerNorm and GELU and reducing FLOPs counts. For the first time, we propose a Softmax-only architecture with significantly fewer FLOPs tailored for efficient PI. Furthermore, we devise a novel entropy regularization technique to improve the performance of Softmax-only models. AERO achieves up to 4.23$\times$ communication and 1.94$\times$ latency reduction. We validate the effectiveness of AERO by benchmarking it against the state-of-the-art.
ReLU's Revival: On the Entropic Overload in Normalization-Free Large Language Models
Oct 12, 2024LayerNorm is a critical component in modern large language models (LLMs) for stabilizing training and ensuring smooth optimization. However, it introduces significant challenges in mechanistic interpretability, outlier feature suppression, faithful signal propagation, and computational and communication complexity of private inference. This work explores desirable activation functions in normalization-free decoder-only LLMs. Contrary to the conventional preference for the GELU in transformer-based models, our empirical findings demonstrate an {\em opposite trend} -- ReLU significantly outperforms GELU in LayerNorm-free models, leading to an {\bf 8.2\%} perplexity improvement. We discover a key issue with GELU, where early layers experience entropic overload, leading to the under-utilization of the representational capacity of attention heads. This highlights that smoother activations like GELU are {\em ill-suited} for LayerNorm-free architectures, whereas ReLU's geometrical properties -- specialization in input space and intra-class selectivity -- lead to improved learning dynamics and better information retention in the absence of LayerNorm. This study offers key insights for optimizing transformer architectures where LayerNorm introduces significant challenges.
PriViT: Vision Transformers for Fast Private Inference
Oct 06, 2023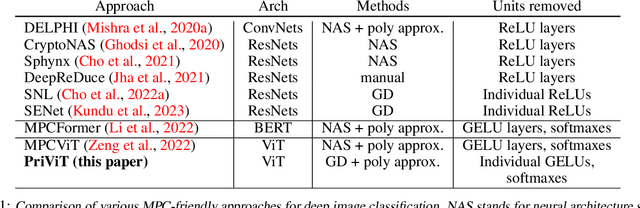
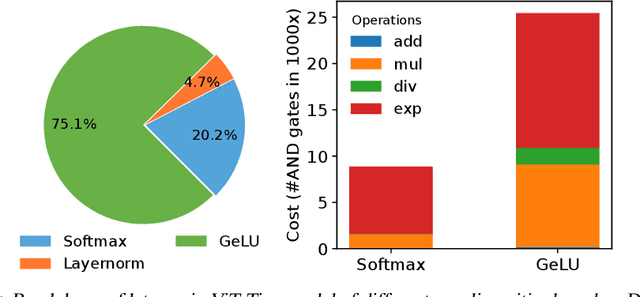
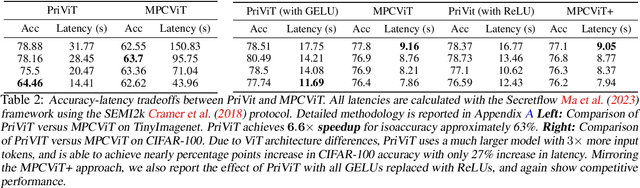
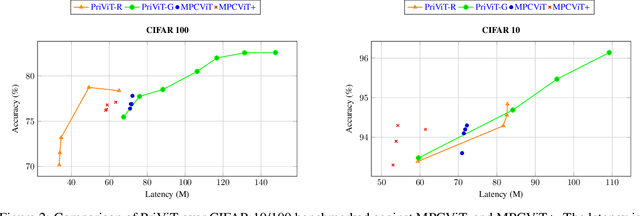
The Vision Transformer (ViT) architecture has emerged as the backbone of choice for state-of-the-art deep models for computer vision applications. However, ViTs are ill-suited for private inference using secure multi-party computation (MPC) protocols, due to the large number of non-polynomial operations (self-attention, feed-forward rectifiers, layer normalization). We propose PriViT, a gradient based algorithm to selectively "Taylorize" nonlinearities in ViTs while maintaining their prediction accuracy. Our algorithm is conceptually simple, easy to implement, and achieves improved performance over existing approaches for designing MPC-friendly transformer architectures in terms of achieving the Pareto frontier in latency-accuracy. We confirm these improvements via experiments on several standard image classification tasks. Public code is available at https://github.com/NYU-DICE-Lab/privit.
Towards Fast and Scalable Private Inference
Jul 09, 2023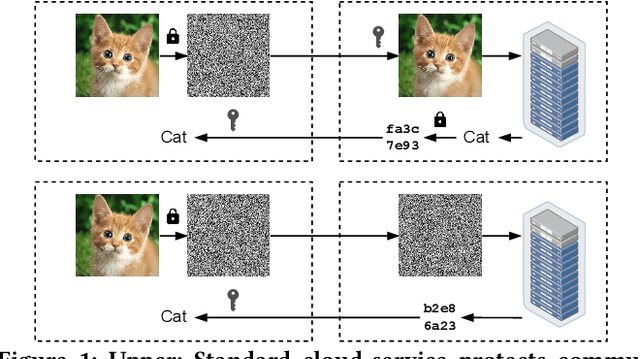
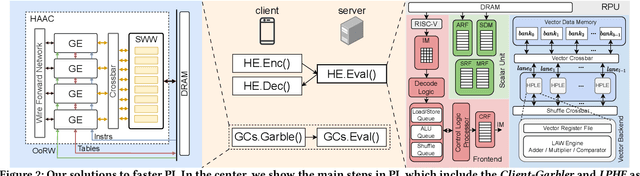
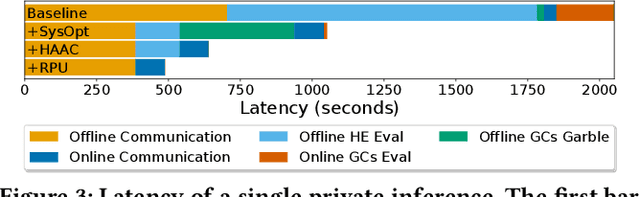
Privacy and security have rapidly emerged as first order design constraints. Users now demand more protection over who can see their data (confidentiality) as well as how it is used (control). Here, existing cryptographic techniques for security fall short: they secure data when stored or communicated but must decrypt it for computation. Fortunately, a new paradigm of computing exists, which we refer to as privacy-preserving computation (PPC). Emerging PPC technologies can be leveraged for secure outsourced computation or to enable two parties to compute without revealing either users' secret data. Despite their phenomenal potential to revolutionize user protection in the digital age, the realization has been limited due to exorbitant computational, communication, and storage overheads. This paper reviews recent efforts on addressing various PPC overheads using private inference (PI) in neural network as a motivating application. First, the problem and various technologies, including homomorphic encryption (HE), secret sharing (SS), garbled circuits (GCs), and oblivious transfer (OT), are introduced. Next, a characterization of their overheads when used to implement PI is covered. The characterization motivates the need for both GCs and HE accelerators. Then two solutions are presented: HAAC for accelerating GCs and RPU for accelerating HE. To conclude, results and effects are shown with a discussion on what future work is needed to overcome the remaining overheads of PI.
Selective Network Linearization for Efficient Private Inference
Feb 04, 2022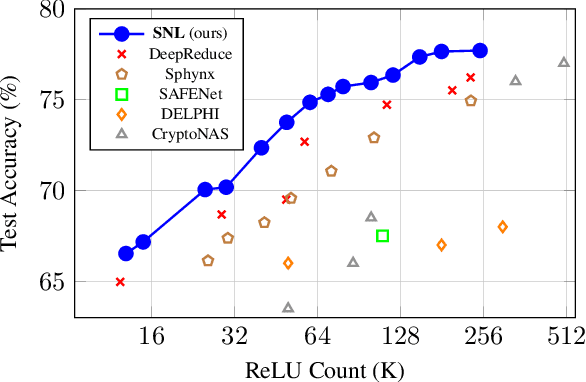

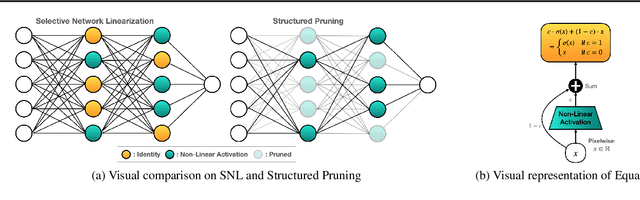
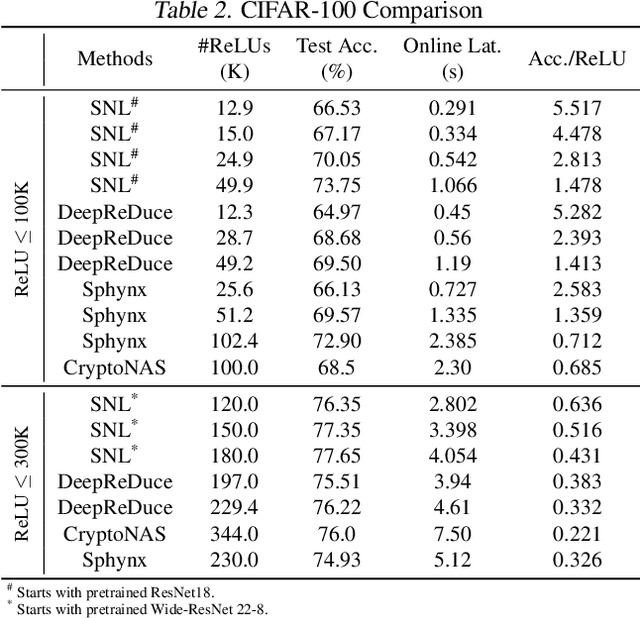
Private inference (PI) enables inference directly on cryptographically secure data. While promising to address many privacy issues, it has seen limited use due to extreme runtimes. Unlike plaintext inference, where latency is dominated by FLOPs, in PI non-linear functions (namely ReLU) are the bottleneck. Thus, practical PI demands novel ReLU-aware optimizations. To reduce PI latency we propose a gradient-based algorithm that selectively linearizes ReLUs while maintaining prediction accuracy. We evaluate our algorithm on several standard PI benchmarks. The results demonstrate up to $4.25\%$ more accuracy (iso-ReLU count at 50K) or $2.2\times$ less latency (iso-accuracy at 70\%) than the current state of the art and advance the Pareto frontier across the latency-accuracy space. To complement empirical results, we present a "no free lunch" theorem that sheds light on how and when network linearization is possible while maintaining prediction accuracy.
Sisyphus: A Cautionary Tale of Using Low-Degree Polynomial Activations in Privacy-Preserving Deep Learning
Jul 26, 2021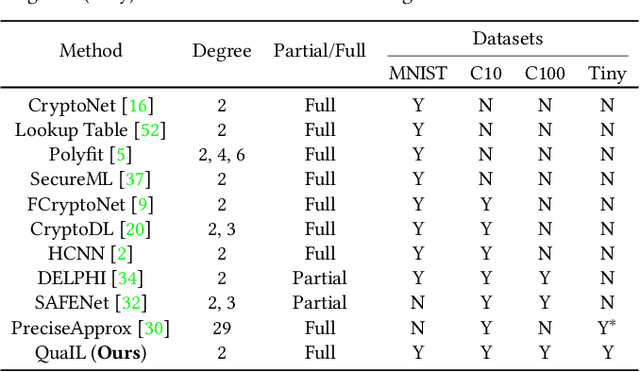
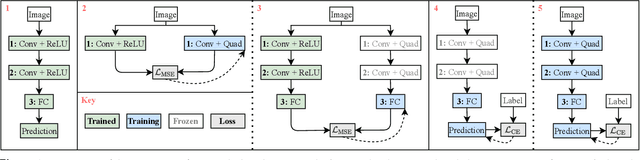
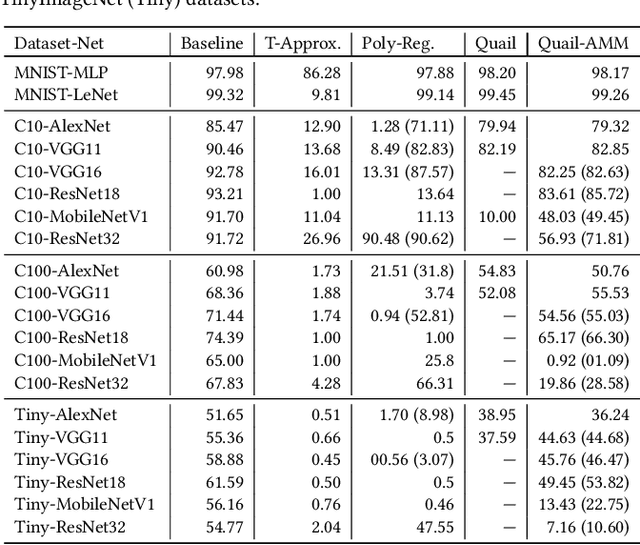
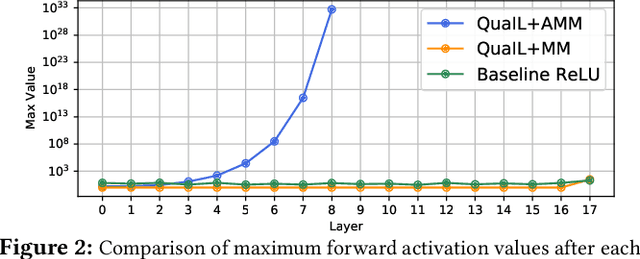
Privacy concerns in client-server machine learning have given rise to private inference (PI), where neural inference occurs directly on encrypted inputs. PI protects clients' personal data and the server's intellectual property. A common practice in PI is to use garbled circuits to compute nonlinear functions privately, namely ReLUs. However, garbled circuits suffer from high storage, bandwidth, and latency costs. To mitigate these issues, PI-friendly polynomial activation functions have been employed to replace ReLU. In this work, we ask: Is it feasible to substitute all ReLUs with low-degree polynomial activation functions for building deep, privacy-friendly neural networks? We explore this question by analyzing the challenges of substituting ReLUs with polynomials, starting with simple drop-and-replace solutions to novel, more involved replace-and-retrain strategies. We examine the limitations of each method and provide commentary on the use of polynomial activation functions for PI. We find all evaluated solutions suffer from the escaping activation problem: forward activation values inevitably begin to expand at an exponential rate away from stable regions of the polynomials, which leads to exploding values (NaNs) or poor approximations.