 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncFormer: Private LLM Inference Using Only Truncations
Paper and Code



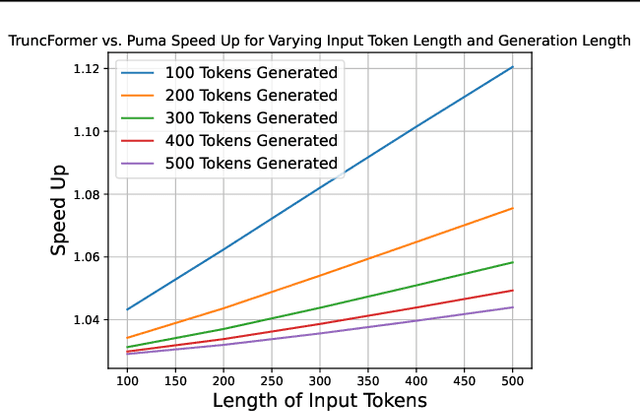
Private inference (PI) serves an important role in guaranteeing the privacy of user data when interfacing with proprietary machine learning models such as LLMs. However, PI remains practically intractable due to the massive latency costs associated with nonlinear functions present in LLMs. Existing works have focused on improving latency of specific LLM nonlinearities (such as the Softmax, or the GeLU) via approximations. However, new types of nonlinearities are regularly introduced with new LLM architectures, and this has led to a constant game of catch-up where PI researchers attempt to optimize the newest nonlinear function. We introduce TruncFormer, a framework for taking any LLM and transforming it into a plaintext emulation of PI. Our framework leverages the fact that nonlinearities in LLMs are differentiable and can be accurately approximated with a sequence of additions, multiplications, and truncations. Further, we decouple the add/multiply and truncation operations, and statically determine where truncations should be inserted based on a given field size and input representation size. This leads to latency improvements over existing cryptographic protocols that enforce truncation after every multiplication operation. We open source our code for community use.